Turbo code is a channel coding that can achieve excellent error correction performance even under low signal-to-noise ratio conditions. In the early days, in order to emphasize the excellent performance of Turbo code close to the Shannon limit, the codeword length studied was very large [1-2], which caused problems such as high decoding complexity and extended decoding time. Burst data communication mainly transmits small and medium-length data message services, so the code length of Turbo code in burst communication is also below medium length. This paper studies the FPGA implementation of short frame length Turbo code encoding and decoding algorithm for channel coding applications in burst data communication. The optimized encoding and decoding algorithm is used in the implementation to reduce decoding complexity and decoding delay. Finally, the error correction performance and throughput of the Turbo decoder are simulated and tested.
1 FPGA Implementation of Turbo Code Encoder
The encoder of Turbo code is composed of two RSC (Recursive Systematic Convolutional Code) component encoders and an interleaver. RSC code not only has the advantages of systematic code, but also for one RSC code, there is always an NSC code (non-systematic convolutional code) with exactly the same grid structure. Two identical RSC encoders are used in this system, and the generated polynomials are G = [1, 15/13], and the system coding rate is 1/3.
The function of the interleaver is to combine two independent short codes into a long random code by using the idea of randomization. The implementation of the Turbo code interleaver in this topic is to construct an interleaver address generator and generate the interleaver address sequence in real time according to the input frame length information.
Figure 1 is a block diagram of the encoder's FPGA implementation. Before encoding, the address generator obtains the frame length information and completes the preparation process for interleaved address generation. During encoding, the information sequence is written into the dual-port RAM in sequence. After writing a frame of data, the address generator starts to generate sequential addresses and interleaved addresses. The dual-port RAM reads the information sequence X and the interleaved information sequence X' according to two addresses for RSC encoding; finally, the encoder outputs the system bit X and the check bits P0 and P1.

2 FPGA Implementation of Turbo Code Decoder
The Turbo code decoder is relatively complex. The following describes the FPGA implementation of the decoder in detail from five aspects: the decoder interface, internal structure, internal timing control, component decoding MAX-Log-MAP algorithm, and implementation of the SISO module.
2.1 Decoder Interface
The interface pins of the top-level module of the Turbo code decoder are shown in Table 1.
 [page]
[page]
2.2 Internal structure of the decoder
The turbo code decoder consists of two soft-input/soft-output component decoders, an interleaver, and a corresponding deinterleaver. Decoding is the process of iterative operation of information between two component decoders. In the iterative operation, the external information Λe(uk) obtained in the previous operation is used as the prior information Λa(uk) of the next operation. The decoding algorithms of turbo code component decoders mainly include MAP (maximum a posteriori probability decoding algorithm) and SOVA (soft decision Viterbi decoding algorithm) [3]. This paper adopts the MAX-Log-MAP algorithm with moderate computational complexity and performance. The internal structure of the turbo code decoder FPGA implementation is shown in Figure 2.

The address generator is the same as the encoder and is used for data interleaving and deinterleaving. The input data memory is used to store the input received data, including the system information sequence memory and each check sequence memory. The external information memory is used to store the external information generated by iterative decoding. Since the external information is to be used as the prior information for the next decoding, there are two external information memories here, which alternately store the external information of the two component decoders. The SISO module is a soft input and soft output component decoder. The entire Turbo code decoder has two SISO component decoding modules. However, in order to save resources, this scheme only designs one SISO module, which uses time division multiplexing as two component decoders. In Figure 2, represents the system bit in the received codeword, and represents the check bit in the received codeword.
2.3 Timing Control within the Decoder
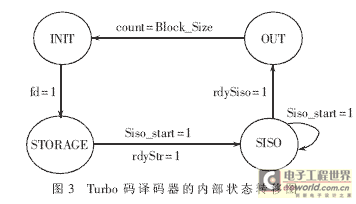
The internal timing control of the turbo decoder is completed by the state machine. The entire decoding process is divided into four processes: initialization, received data storage, iterative decoding, and hard decision output, which correspond to the four states of the state machine: INIT, STORAGE, SISO, and OUT. The internal state transition of the decoder is shown in Figure 3. The initial state INIT completes the initialization work such as frame length setting, and completes the preparation process of interleaving address generation. Once the fd signal indicating the first data input is valid (high effective), it enters the STORAGE state; the state STORAGE completes the storage of the received data sequence into the single-port RAM. After a frame of data is written, the rdyStr signal indicating that the storage is completed is set high, and the SISO state is entered; in the state SISO, the SISO component decoder iteratively decodes the received data according to the set number of iterations. When the iteration is completed, rdySiso is set high and enters the OUT state; the data hard decision is output and counted, and the output valid signal ready is set high at this time, and the INIT state is returned after all decisions are completed.
 [page]
[page]
2.4 Component Decoding Algorithm——MAX-Log-MAP Algorithm
The MAP algorithm requires a large number of multiplication operations and exponential operations as well as a large amount of storage, and the operation is very complex. The Log-MAP algorithm converts the multiplication operations in the MAP algorithm into addition operations in the logarithmic domain (no logarithmic operations are required), which is suitable for engineering implementation. Therefore, when implementing in engineering, the original addition operation in the logarithmic domain can be converted into an operation of taking the larger of two numbers plus a correction term. If the operation of the correction term is also omitted, the Log-MAP algorithm can be simplified to the MAX-Log-MAP algorithm. The main calculation steps of the MAX-Log-MAP algorithm are as follows [4-5]:
(1) Calculate the path metric value of the branch on the Turbo code encoding grid graph:

Since the Lc value has little effect on the decoding performance[6], in order to facilitate fixed-point implementation, it is simplified to Lc=1 in this paper.
2.5 Implementation of SISO Module
The SISO module implemented by FPGA of the component decoder adopts modular design, which mainly includes forward metric calculation module, reverse metric calculation and log-likelihood ratio calculation module, forward metric memory and normalized metric memory. Since both forward metric calculation and reverse metric calculation need to calculate branch metrics, branch metrics can be calculated and stored in advance. However, in this scheme, in order to save storage space, branch metrics are not stored, but calculated once in both forward and reverse metric calculations, and log-likelihood ratio is calculated at the same time after the reverse metric calculation converges.
When using FPGA to implement the algorithm in fixed point, the overflow problem needs to be considered. To prevent overflow during the calculation process, the forward metric and reverse metric calculation process are normalized. If the normalized metric value at a certain moment selects the maximum value of the forward metric at the current moment, then the normalization is the forward metric and reverse metric minus this maximum value. The normalized forward metric and reverse metric calculation formulas are as follows:
[page]
The internal processing flow of the SISO module is divided into three parts: initialization, forward metric calculation and storage, reverse metric calculation, and log-likelihood value calculation, which correspond to the three states of the state machine: INIT, FSM, and RSM. The internal timing of the SISO module is shown in Figure 4. The INIT state completes the initialization setting of the internal register. When the external input signal Siso_start is valid, the SISO module is started and enters the FSM state; in the FSM state, every 8 clock cycles, the 8 forward metric values corresponding to a moment are calculated using equations (1) and (2), and the maximum forward metric value is selected as the normalized metric value, and the normalized forward metric value is calculated using equation (8). Start a forward metric write signal to store the 8 forward metric values currently calculated and the current normalized metric value. When all forward metrics are calculated, the Fsmrdy signal is activated and the RSM state is entered; every 10 clock cycles, the 8 reverse metric values corresponding to a moment are calculated using equations (1) and (2), the normalized reverse metric value is calculated using equation (9), the log-likelihood ratio and external information log-likelihood ratio of the corresponding moment are calculated using equations (4) and (5), and the external information log-likelihood ratio is stored. When all calculations are completed, the Rsmrdy signal is activated and the INIT state is entered.

Since the SISO module in this scheme uses time division multiplexing as two component decoders, it corresponds to two half-iteration processes of one decoding iteration. Therefore, when Decoder_num in Figure 4 is low, the SISO module acts as the first component decoder and performs the first half-iteration operation; when Decoder_num is high, the SISO module acts as the second component decoder and performs the second half-iteration operation. The log-likelihood ratio information generated in each half-iteration is used as the prior information for the next half-iteration. Two RAMs are used to store the external information log-likelihood ratios generated by two half-iterations. In the first half-iteration, the external information log-likelihood ratio generated in the previous half-iteration is read from the second external information memory as the prior information, and the external information log-likelihood ratio is calculated and stored in the first external information memory; in the second half-iteration, the external information log-likelihood ratio generated in the previous half-iteration is read from the first external information memory as the prior information, and the external information log-likelihood ratio is calculated and stored in the second external information memory. The prior information of the first half-iteration in the first iteration of each frame data decoding is set to 0.
After the iteration meets the iteration termination criterion, the decoder stops iterating and outputs the decoding result by hard decision based on the log-likelihood ratio of the information. The commonly used iteration termination criterion in engineering is to set the maximum number of iterations. The setting of the maximum number of iterations needs to comprehensively consider the bit error rate performance and system throughput performance.
3 Performance of Turbo Codec
Based on the FPGA implementation scheme of the Turbo codec proposed above, this paper implements a Turbo codec with a variable frame length between 64 and 1 024 on the XC2V500-6fg256 FPGA chip of the Virtex2 series of Xilinx. The input data is quantized to 4 bits, the internal data width is selected to be 12 bits, and the encoder module and the decoder module are implemented on the same FPGA chip. After synthesis, the minimum clock cycle is 7.188ns, corresponding to the maximum clock frequency of 139.121MHz, and the occupied resources are shown in Table 2.

Delay and throughput are two main indicators for measuring decoder performance. Latency is defined as the time difference between the first data input and the first data output. Throughput is defined as the average amount of data that can be processed per second. Under the conditions of a frame length of 1,024 and a number of iterations of 5, the decoder delay is about 1.4ms and the throughput is about 0.72Mbps. [page]
Finally, the bit error rate performance of the Turbo code decoder with four conditions of frame length of 128, 256, 512 and 1 024 was tested. Gaussian white noise was added to the test system, the data was modulated by BPSK, and the decoder was iterated 5 times. The performance curve of the test results is shown in Figure 5. The test results show that under the condition of signal-to-noise ratio less than 4dB, the frequency hopping data communication system adopts Turbo coding scheme, and the bit error rate is less than 10-5, which meets the requirements of data transmission reliability. Since the frame length of the decoder is variable in the range of 64 to 1 024, it is very suitable for error control in burst data communication.

References
1 Berrou C, Glavieux A, Thitimajshima P. Near shannon limit error-correcting codeing and decoding: turbo codes. in Proc.ICC′93, Geneva, Switzerland, May. 1993:1064~1070
2 Berrou C. Near optimum error correcting coding and decoding-turbo-codes. IEEE Transcations On Communications, 1996;44(10)
3 Wan Lei. Turbo codes and their applications in third generation mobile communication systems. PhD dissertation from Beijing Institute of Technology, 2001
4 Robertson P, Villebrun E, Hoeher P. A comparison of optimal and suboptimal MAP decoding algorithms operation in the log domain. in Proc.ICC’95,Seattle,WA,June 1995:1009~1013
5 Liu Donghua. Turbo Code Principle and Application Technology. Beijing: Publishing House of Electronics Industry, 2004
6 Worm A, hoeher P, When N. Turbo-decoding without SNR estimation. IEEE Commmun,2000;(4):193~195
Previous article:Construction of a NoC Verification Platform Based on FPGA
Next article:Multi-core processor SoC design for embedded system applications
Recommended ReadingLatest update time:2024-11-16 21:58

- Popular Resources
- Popular amplifiers
-
 Analysis and Implementation of MAC Protocol for Wireless Sensor Networks (by Yang Zhijun, Xie Xianjie, and Ding Hongwei)
Analysis and Implementation of MAC Protocol for Wireless Sensor Networks (by Yang Zhijun, Xie Xianjie, and Ding Hongwei) - MATLAB and FPGA implementation of wireless communication
- Intelligent computing systems (Chen Yunji, Li Ling, Li Wei, Guo Qi, Du Zidong)
- Summary of non-synthesizable statements in FPGA
 Analysis and Implementation of MAC Protocol for Wireless Sensor Networks (by Yang Zhijun, Xie Xianjie, and Ding Hongwei)
Analysis and Implementation of MAC Protocol for Wireless Sensor Networks (by Yang Zhijun, Xie Xianjie, and Ding Hongwei)




- Huawei's Strategic Department Director Gai Gang: The cumulative installed base of open source Euler operating system exceeds 10 million sets
- Analysis of the application of several common contact parts in high-voltage connectors of new energy vehicles
- Wiring harness durability test and contact voltage drop test method
- Sn-doped CuO nanostructure-based ethanol gas sensor for real-time drunk driving detection in vehicles
- Design considerations for automotive battery wiring harness
- Do you know all the various motors commonly used in automotive electronics?
- What are the functions of the Internet of Vehicles? What are the uses and benefits of the Internet of Vehicles?
- Power Inverter - A critical safety system for electric vehicles
- Analysis of the information security mechanism of AUTOSAR, the automotive embedded software framework
 Professor at Beihang University, dedicated to promoting microcontrollers and embedded systems for over 20 years.
Professor at Beihang University, dedicated to promoting microcontrollers and embedded systems for over 20 years.






- Innolux's intelligent steer-by-wire solution makes cars smarter and safer
- 8051 MCU - Parity Check
- How to efficiently balance the sensitivity of tactile sensing interfaces
- What should I do if the servo motor shakes? What causes the servo motor to shake quickly?
- 【Brushless Motor】Analysis of three-phase BLDC motor and sharing of two popular development boards
- Midea Industrial Technology's subsidiaries Clou Electronics and Hekang New Energy jointly appeared at the Munich Battery Energy Storage Exhibition and Solar Energy Exhibition
- Guoxin Sichen | Application of ferroelectric memory PB85RS2MC in power battery management, with a capacity of 2M
- Analysis of common faults of frequency converter
- In a head-on competition with Qualcomm, what kind of cockpit products has Intel come up with?
- Dalian Rongke's all-vanadium liquid flow battery energy storage equipment industrialization project has entered the sprint stage before production
- Allegro MicroSystems Introduces Advanced Magnetic and Inductive Position Sensing Solutions at Electronica 2024
- Car key in the left hand, liveness detection radar in the right hand, UWB is imperative for cars!
- After a decade of rapid development, domestic CIS has entered the market
- Aegis Dagger Battery + Thor EM-i Super Hybrid, Geely New Energy has thrown out two "king bombs"
- A brief discussion on functional safety - fault, error, and failure
- In the smart car 2.0 cycle, these core industry chains are facing major opportunities!
- The United States and Japan are developing new batteries. CATL faces challenges? How should China's new energy battery industry respond?
- Murata launches high-precision 6-axis inertial sensor for automobiles
- Ford patents pre-charge alarm to help save costs and respond to emergencies
- New real-time microcontroller system from Texas Instruments enables smarter processing in automotive and industrial applications
- [Fudan Micro FM33LG0 series development board review] Development board microcontroller printf Chinese and English printing test
- Control the state of multiple IOs through the serial port
- Mobile phone RF is moving towards integrated chips
- EEWORLD University ---- Make your home safer - Intelligent building security system
- TI 2022 exciting technical live replays are ready for you!
- Phase-locked loop CD4046 application introduction
- "Dating Spring" + A cherry tree in full bloom
- 【Silicon Labs Development Kit Review】+ Key Program Test
- Welcome to join the open source project--Aurora
- Looking for a software and hardware embedded engineer who works from home, salary is optional






 京公网安备 11010802033920号
京公网安备 11010802033920号