FPGAs have great potential for accelerating common datacenter workloads such as Web searches and similar information retrieval tasks due to their inherent parallel processing and low power consumption. Recognizing this potential, Austrian company Matrixware purchased an FPGA platform but lacked the technology to implement a complex information retrieval application on its own, so the company hired a team we formed in conjunction with the University of Glasgow Department of Computer Science to develop a proof-of-concept for an FPGA-accelerated patent search solution. The team included three designers and adjunct research associate S.T. Elios Papanastasious, who had extensive expertise in information retrieval, FPGAs, and system development, forming a skilled combination of skills necessary to develop a prototype application. After discussion, everyone agreed to use an FPGA-accelerated backend for the development of a real-time patent filtering application.
The project resources were very constrained in terms of manpower and time. Therefore, implementing the filtering algorithm in HDL was not feasible, so we decided to use a high-level programming solution developed by the Swedish company Mitri ON ics.
The prototype application attracted great interest from patent researchers at the Information Retrieval Facility Symposium held in Vienna, Austria last November. Processing millions of patents normally takes several minutes, but with the FPGA-accelerated backend, results can be returned in seconds.
We published the results and performance improvements at the July 2009 ACM SIGIR International Conference on Information Retrieval Research and Development , and presented the architectural design in detail at the FPL 2009 International Conference on Field Programmable Logic.
Document filtering input and output
Typically, information filtering involves checking incoming documents to see if they match a set of defined requirements or profiles. This can be done in a variety of situations and for a variety of reasons, such as detecting whether an incoming email is spam, comparing patent applications for overlap with existing patents, monitoring for terrorist communications, monitoring and tracking news reports, and more. With a large influx of documents, processing must be done in real time, making timeliness a top priority. Given this, our goal is to implement the most computationally intensive filtering applications using FPGAs, thereby making document filtering more efficient while saving time and energy.
In this article, we will adopt the relevance model proposed by Lavrenko and Croft. This concept is applicable to information filtering tasks and determines whether an incoming document is different from a topic profile by generating a probabilistic language model. If the document score exceeds a user-defined threshold, it is considered relevant to the topic profile.
The algorithm implemented on the FPGA is expressed as follows: A document can be modeled as a "bag of words", i.e. a set D consisting of (t,f) pairs, where f=n(t,d) and t represents the number of times the word t appears in document d. The profile M is a set of pairs p=(t,w), where w is weighted as:

The score for a given document for a given profile is calculated as:

Here, T refers to the words that appear in both D and M. This function is the representative kernel algorithm of most filtering algorithms. The main difference between different algorithms lies in the weighting of words in the configuration file.
Application Architecture
The document filtering application uses a client- server architecture consisting of a GUI-based client connected via TCP/IP to a communication server that acts as a proxy between different backend servers and the client (see Figure 1). In a typical use case, the user first issues a request to the query server, which returns a ranked list of selections from a regular search system. The user then creates a profile by selecting relevant documents from this list. Next, the profile server builds a profile (i.e., a list of terms and weights) using the full text of all merged documents. The profile server matches the profile to the full collection of documents and returns a stream of scores to the client.
The modular client-server architecture facilitates system benchmarking because we can easily add a C++ reference implementation of a profile server on the host CPU . As shown in Figure 1, the portion of the application accelerated by the FPGA is limited to the most computationally intensive task, matching documents to profiles. The host system handles all other tasks (see Figure 2).
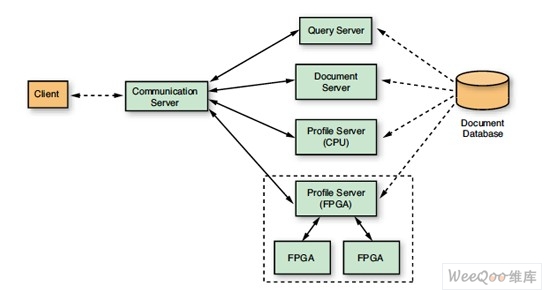
Figure 1 - The system architecture is centered around a communication server that acts as a proxy between clients and backend servers.
The profile server filters a list of documents based on the profile obtained from the client and returns a stream of scores. To evaluate performance, we created both a C++ reference implementation and an FPGA-accelerated implementation. Both versions of the implementation have the same basic functionality, receiving a list of documents that make up a profile through a TCP/IP interface , building a profile using a relevance model, and scoring the documents buffered in memory based on the profile , returning a stream of document scores to the client through TCP/IP. The document stream can be buffered in memory, otherwise the performance of the application will be affected due to slow disk access.
We implemented the application on an SGI Altix 4700 machine with two RC100 blades, each containing two Xilinx Virtex?-4 LX200 FPGAs running at 100 MHz; each FPGA is connected to the host platform via the SGI NUMAlink high-speed I/O interface and has access to a local 64MB SRAM memory bank via a 128-bit data bus running at up to 16GB per second . The host system is an 80-core 64-bit NUMA machine running 64-bit Linux (OpenSuSE). The processors are dual-core Itanium-2s running at 1.6 GHz, each with direct access to 4GB of memory and access to the full 320GB memory space via NUMAlink. It is worth noting that the Itanium processor consumes about 130 watts, while each Virtex-4 FPGA consumes only about 1.25 W.

Figure 2 - In the FPGA subsystem architecture, the Virtex-4 device connects to the host platform through SGI's NUMAlink interface.
For C++ language applications, we implement the Lemur Information Retrieval (IR) framework, and for interaction with FPGA applications, we use the SGI Reconfigurable Application-Specific Computing (RASC) library. The Lemur Toolkit is an open source tool set designed specifically for IR research that supports indexing and multiple relevance and retrieval models. The RASC library is SGI's proprietary solution that integrates FPGAs with host systems over a high-performance NUMAlink interconnect. The RASC library defines a hardware abstraction API that controls all hardware elements in the system .
We used the Mitrionics Software Development Kit (SDK) to convert the domain-specific Mitrion-C language to VHDL. The generated VHDL can now be easily targeted to the FPGA device architecture. We used the Xilinx ISE? tool chain with the XST synthesis tool to create the Virtex-4 bitstream.
Advanced FPGA Programming
The Mitrionics SDK provides Mitrion-C as a high-level language specifically designed for rapid application development on FPGAs. However, the C suffix is somewhat misleading. Although the language uses C-style syntax, it is actually a single-assignment dataflow language that follows a functional programming style. Mitrion-C natively supports broad (vector) and deep (pipeline) parallelism, making it ideal for algorithms that process data streams, such as filtering and many other types of text and data mining algorithms.
Mitrion-C also provides a stream data type that can be used with the foreach looping construct to implement pipeline operations; in addition, it also provides a vector data type to support data parallel work, and a list data type to support sequential lists. Specifically, users can filter the stream output of the foreach loop to generate smaller streams, as shown in the following Mitrion-C code example. In addition, programmers can use tuple constructs to create powerful data types. Finally, another feature worth mentioning is that the language supports variable-width integers and floating-point numbers.

In order to implement the * operations efficiently on FPGA, the key issues we must solve are efficient query of configuration files and efficient I/O flow of the document stream.
For each word in the document, the application queries the configuration file for the corresponding word and obtains the term weight. Since most queries will not find any results (i.e., most words in most documents will not appear in the configuration file), negative words must be discarded first. For this reason, we use Bloom filters [9] in the FPGA Block RAM. The higher the internal bandwidth of the BRAM, the faster the results of rejecting negative words. Since queries are required, the configuration file must be implemented as some kind of hash function. However, since the size of the configuration file cannot be known in advance, it is impossible to construct a perfect hash function. Imperfect hash functions will have collision problems, which will reduce performance.
To address this issue, we use a binning scheme that partitions the external SRAM into bins, each of which can contain a fixed number of profile words. The size of the bin determines the number of collisions that can be handled. To assign a profile word to a bin, only the lower part of the word ID is used as the memory address, thus avoiding the actual hashing operation.
Let the SRAM memory size be NM profile words. The word ID is an unsigned integer whose range depends on the vocabulary size, which for our example is about 4 million words and requires 24 bits. The word weight is 8.32 fixed point number, so the profile word requires 64 bits. The SRAM on RC100 consists of 4 16 MB banks, so NM=223. The number of bins nb=NM/b and the bin address is calculated with word ID "t", i.e. (t&(nb-1)).b.
The probability of bin occupancy x is determined by the combination and permutation of the number of bins nb and the number of descriptors np. Thus, we can calculate the probability of bin overflow as a function of the bin size (i.e., the number of bins), i.e., NM=b.nb. The larger the bin size, the slower the query, but since the SRAM memory bank consists of 4 independent 64-bit addressable dual-port SRAMs, we can actually query four profile words in parallel. Therefore, the relative performance will be reduced by 1/ceil(b/4). Our analysis shows that even for the largest profiles (16K, the largest profile used in our study is 12K, but profiles are usually much smaller than this), the probability of bin overflow is 10-9 when b=4 (optimal performance). In other words, the probability of a descriptor being discarded is less than 1 in 1 billion. It should be noted that this estimate is conservative because we assume an infinite vocabulary size.

Figure 3 - Schematic diagram of FPGA implementation of filtering application
By representing documents as "bags of words", the document stream is a list of pairs such as document ID, document term pair set, etc. Physically, the FPGA receives a 128-bit word stream from NUMAlin at a speed of 1.6 GB per second. Therefore, the document stream must be encoded on the word stream. The document word pair di = (ti, fi) can be encoded as 32 bits: 24 bits for the word ID (supporting a vocabulary of 16 million words) and 8 bits for the frequency of the word. In this way, we can combine 4 pairs into a 128-bit word. To mark the start and end of the document, we need to insert a header and footer word containing the document ID (64 bits) and a marker (64 bits).
With the lookup table architecture and document stream format described above, the actual query and * score system (Figure 3) is quite straight forward. We simply scan the input stream to check for header and footer words. Header words set the document score to 0, while footer words collect and output the document score. For every four profile words in the document, the Bloom filter first discards the negative word results and then reads four profile words from the SRAM. The score for each word is calculated and added in parallel (Figure 4). In reality, three out of four profile word IDs will not match a document word ID; only the fourth is actually calculated. The scores for all words in the document are accumulated, and the final score stream is filtered by comparing it to a limit before being output to host memory.
The host-FPGA interface transfers the document stream from the memory buffer to the FPGA and returns the score stream to the client. Once the configuration document ID table is received from the client, a child process is forked from the main process to build the actual configuration file, load it into SRAM, and run the algorithm on the FPGA. Each child process spawns a separate output thread to buffer the scores obtained from the FPGA and transmit them to the client via TCP/IP, multiplexing the score stream using the network. Without this thread, fluctuations in network throughput would degrade system performance. The main advantage of this host interface architecture is that it is highly scalable and can easily meet the needs of a large number of FPGAs.
Significant speed-up
To evaluate the performance of FPGA-accelerated filtering applications, we conducted a series of experiments comparing the FPGA-based implementation with an optimized reference implementation written in C++ running on Altix. For the comparison, we used three IR test collections (see Table 1): TREC Aquaint, a benchmark reference collection provided by the Text Retrieval Conference (TREC), and patent collections provided by the United States Patent and Trademark Office (USPTO ) and the European Patent Office (EPO). We chose the above test collections to evaluate the impact of different document lengths and sizes on filtering time.
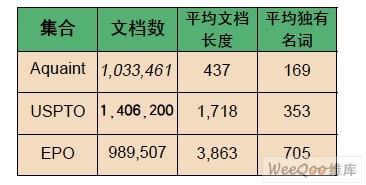
To simulate a number of different filters, we built a profile for each test collection by selecting random documents and requesting them with their titles, then selecting a fixed number of documents returned by the request server as pseudo-relevant documents. We then used the returned documents to build a relevance model that defines the profile that each document in the collection should match (as if streamed from the network). The number of documents in the profile was varied from 1 to 50 to determine how increasing the size of the profile (number of words and documents) would affect performance. We repeated the above process 30 times and calculated the average processing time.
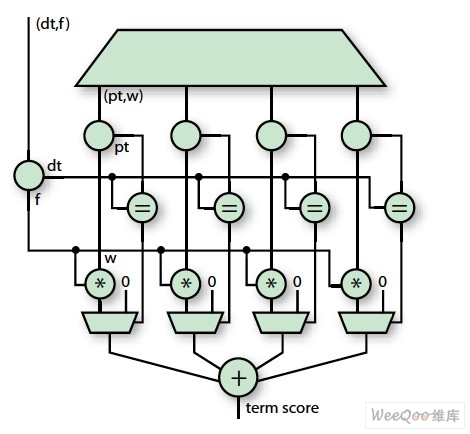
Figure 4 - Correlation Model
We summarize the results in Table 2 and Figure 5. It is clear from the table that the FPGA implementation is generally an order of magnitude faster than the standard implementation. From the figure, it can be seen that as the size of the configuration file (the number of words to match) increases, the standard implementation becomes slower and slower, while the speed of the FPGA implementation remains relatively constant. This is because the FPGA implementation supports streamlining of configuration files by partitions, so that the latency remains relatively constant regardless of the configuration file size.
These results clearly show that FPGAs have great potential for accelerating IR tasks. The speedup achieved with FPGAs is already quite large (especially for large profiles), and there is still room for further improvement. Through simulations, we confirmed that the FPGA algorithm requires two clock cycles to score one document word. The limiting factor is the 128-bit per cycle SRAM access speed, which requires two cycles to read four profile words. If the clock speed is 100 MHz, this means that the FPGA can complete the score of the entire EPO document collection in less than 15 seconds. The current application takes about 8.5 seconds on four FPGAs, so in principle we can at least double the performance again.
The reason for the difference is streaming I/O: a file stream is transferred from user memory space to NUMAlink via a host OS device driver , which requires a direct memory access (DMA) transfer. The driver transfers cache blocks of the stream. Currently, this transfer is not implemented in an optimal way for the size of the transferred block , resulting in sub-optimal throughput. In addition, using separate threads to sort the transfers can also avoid transfer delays.
Problems encountered and lessons learned
The significance of this project lies not only in that it demonstrates the advantages of FPGA as an accelerator for information retrieval tasks, but also in that it provides us with important information about the hardware and software requirements of FPGA acceleration systems.
I/O to the host system is key to performance: the DMA mechanism between the NUMA memory and the FPGA must be supported by the Mitrionics SDK and SGI RASClib. In previous projects, we had to transfer data to SRAM on the board before processing, but this seriously affected performance because the loading of data and unloading of results was very expensive. In addition, it became clear that IR tasks in particular require a lot of on-chip and on-board memory to achieve maximum efficiency.
Additionally, to fully utilize FPGAs, future platforms must have two key features: the ability to transfer data directly between FPGAs and the ability to shut down the host processor (or control multiple FPGAs with one host processor). The ability to shut down the host processor is particularly important: On Altix platforms, the Itanium processor cannot be shut down even when it is completely idle. However, an idle Itanium processor can consume up to 90% of the power required when it is active. So, while FPGA acceleration offers significant energy savings, our current system still has limited overall energy savings even when the host memory is idle while the accelerator is running.
Another important area of developing FPGA-accelerated systems is software. Our experience clearly shows that the main complexity lies in the interface between the FPGA and the host system: the actual FPGA application development in Mitrion-C is very efficient; the framework for building query and service documents is also relatively easy to develop using the Lemur tool suite. However, developing the code to interface the host application to the FPGA using RASClib is very complex and very difficult to debug due to concurrency issues. Therefore, the development of the interface code occupies the vast majority of development time.
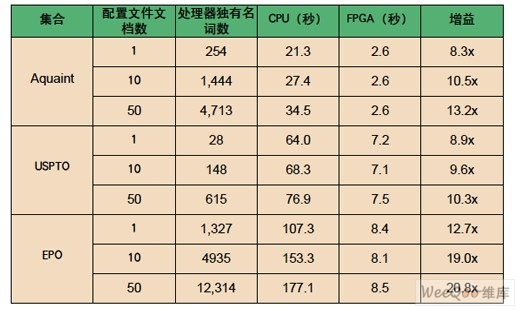

Figure 5 - Time (in seconds) versus number of documents in the configuration file
The final issue with FPGA high-level programming is compile speed. Developers accustomed to languages such as C++ or Java believe that even very complex applications should have short build times. Current FPGA tools take almost a full day to perform synthesis and place routing for anything other than the most basic designs. Very long build times can severely impact productivity, so they should be reduced to typical software build times to make FPGA acceleration more attractive.
Customized hardware platform
我们用这个项目探讨了 FPGA 加速的可能性,并展示了 FPGA 作为数据中心绿色环保技术的巨大潜力。我们希望进一步扩展这项研究,调查文档处理所需的全系列工作任务,如语法分析、词干、索引、搜索以及过滤等。我们清楚地认识到,现有系统在节能潜力方面很有限,我们希望研究能以业界最高效率专门执行信息检索任务的可定制硬件平台。这样,我们就能显著加速算法的执行,同时大幅度降低能耗,从而开发出更加环保、速度更快的数据中心。
Previous article:Research on high-speed communication system based on FPGA
Next article:FPGA Timing Closure
Recommended ReadingLatest update time:2024-11-16 19:39

- Popular Resources
- Popular amplifiers
-
 Analysis and Implementation of MAC Protocol for Wireless Sensor Networks (by Yang Zhijun, Xie Xianjie, and Ding Hongwei)
Analysis and Implementation of MAC Protocol for Wireless Sensor Networks (by Yang Zhijun, Xie Xianjie, and Ding Hongwei) - MATLAB and FPGA implementation of wireless communication
- Intelligent computing systems (Chen Yunji, Li Ling, Li Wei, Guo Qi, Du Zidong)
- Summary of non-synthesizable statements in FPGA
 Analysis and Implementation of MAC Protocol for Wireless Sensor Networks (by Yang Zhijun, Xie Xianjie, and Ding Hongwei)
Analysis and Implementation of MAC Protocol for Wireless Sensor Networks (by Yang Zhijun, Xie Xianjie, and Ding Hongwei)




- Huawei's Strategic Department Director Gai Gang: The cumulative installed base of open source Euler operating system exceeds 10 million sets
- Analysis of the application of several common contact parts in high-voltage connectors of new energy vehicles
- Wiring harness durability test and contact voltage drop test method
- Sn-doped CuO nanostructure-based ethanol gas sensor for real-time drunk driving detection in vehicles
- Design considerations for automotive battery wiring harness
- Do you know all the various motors commonly used in automotive electronics?
- What are the functions of the Internet of Vehicles? What are the uses and benefits of the Internet of Vehicles?
- Power Inverter - A critical safety system for electric vehicles
- Analysis of the information security mechanism of AUTOSAR, the automotive embedded software framework
 Professor at Beihang University, dedicated to promoting microcontrollers and embedded systems for over 20 years.
Professor at Beihang University, dedicated to promoting microcontrollers and embedded systems for over 20 years.






- Innolux's intelligent steer-by-wire solution makes cars smarter and safer
- 8051 MCU - Parity Check
- How to efficiently balance the sensitivity of tactile sensing interfaces
- What should I do if the servo motor shakes? What causes the servo motor to shake quickly?
- 【Brushless Motor】Analysis of three-phase BLDC motor and sharing of two popular development boards
- Midea Industrial Technology's subsidiaries Clou Electronics and Hekang New Energy jointly appeared at the Munich Battery Energy Storage Exhibition and Solar Energy Exhibition
- Guoxin Sichen | Application of ferroelectric memory PB85RS2MC in power battery management, with a capacity of 2M
- Analysis of common faults of frequency converter
- In a head-on competition with Qualcomm, what kind of cockpit products has Intel come up with?
- Dalian Rongke's all-vanadium liquid flow battery energy storage equipment industrialization project has entered the sprint stage before production
- Allegro MicroSystems Introduces Advanced Magnetic and Inductive Position Sensing Solutions at Electronica 2024
- Car key in the left hand, liveness detection radar in the right hand, UWB is imperative for cars!
- After a decade of rapid development, domestic CIS has entered the market
- Aegis Dagger Battery + Thor EM-i Super Hybrid, Geely New Energy has thrown out two "king bombs"
- A brief discussion on functional safety - fault, error, and failure
- In the smart car 2.0 cycle, these core industry chains are facing major opportunities!
- The United States and Japan are developing new batteries. CATL faces challenges? How should China's new energy battery industry respond?
- Murata launches high-precision 6-axis inertial sensor for automobiles
- Ford patents pre-charge alarm to help save costs and respond to emergencies
- New real-time microcontroller system from Texas Instruments enables smarter processing in automotive and industrial applications
- Have fun in moderation, fools have fun together
- Thank you for having you +EEWORLD
- TI FAST algorithm study notes: "Low-speed and high-performance motor control"
- [HPM6750 Review Part 2] CoreMark Verification (Comparison between external flash xip and internal sram)
- This week's review information is here~
- "Head First Design Pattern (Chinese Edition)", a must-read for programmers!
- Huawei RF Basic Knowledge Training Full Solution PDF
- TI's AXC level translator
- I would like to ask the experts to help explain the filtering principle of this picture, as well as the calculation of inductance and capacitance parameters.
- Disassembly preview, does anyone know what this is?






 京公网安备 11010802033920号
京公网安备 11010802033920号