1 Overview of Speech Recognition System-on-Chip
With the development of digital signal processing technology, speech recognition system-on-chip has become a hot topic of research. However, the contradiction between complex systems and hardware requirements has limited its application and promotion to a certain extent. In this paper, we adopt the corresponding recognition strategy [1] to reasonably arrange the algorithm flow and complete the on-chip implementation of a high-performance specific person and non-specific person recognition system.
2 Hardware Platform
When selecting a DSP, factors such as computing speed, cost, power consumption, hardware resources, and program portability need to be considered comprehensively. This system uses the TMS320VC5507 fixed-point DSP produced by Texas Instruments (TI) as the core processor [2], and uses PLL clock generator, JTEG standard test interface, asynchronous communication serial port, DMA controller, general purpose input and output GPIO port, and multi-channel buffered serial port (McBSPs) and other major on-chip peripherals. The system hardware platform is shown in Figure 1.
The VC5507 DSP chip adopts an advanced multi-bus structure, including 64 K×16 bit on-chip RAM and 64 KB ROM; the on-chip shieldable ROM contains bootloader and interrupt vector table, etc.; the pipeline structure is used to improve the overall speed of instruction execution. Unlike the C54x series DSP, the storage space of the VC5507DSP includes unified data, program space and I/O space, and the addressing space can reach 16 MB; the chip contains two arithmetic logic units (ALUs), and at the highest clock frequency of 200 MHz, the instruction cycle can reach 5 ns and the maximum speed can reach 400 MIPS.
The memory uses the M5M29GB/T320VP series Flash chip produced by Mitsubishi. The total capacity of the chip is 2 MW, divided into 128 sectors, and connected to the DSP through the external memory interface (EMIF) and read and write timing; it uses a single power supply of 2.7 V to 3.6 V. This series of Flash supports block programming operations [3], and the read and write speed is much faster, which is conducive to improving real-time performance.
Funding project: National Natural Science Foundation of China 60572083
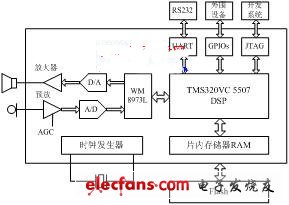
Figure 1 Speech recognition system hardware block diagram
The A/D and D/A converters use the WM8973L chip produced by Wolfson in the UK. This chip supports 16-bit A/D and D/A conversion, has programmable input and output gain control, and can set a variety of sampling frequencies from 8 to 96 kHz through software [4].
3 Software Structure
3.1 System Overview
The specific person recognition system uses 12-dimensional MFCC parameters as the feature parameters of the recognition engine. Both training and recognition are implemented in real time on the chip. The system framework is shown in Figure 2 (a). In the training stage, the feature parameters of each entry are extracted in real time on the chip and stored in the Flash as a template library. In the recognition stage, the feature parameters of the entry to be recognized are extracted in real time, and after endpoint detection, the dynamic time warping (DTW) algorithm is used to match it with all templates in the template library, and the template with the smallest distortion is selected as the recognition result. When the vocabulary changes, only the Flash storage method needs to be adjusted, and the algorithm itself does not need to be changed.
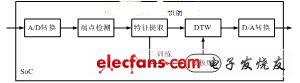
(a) Specific person system
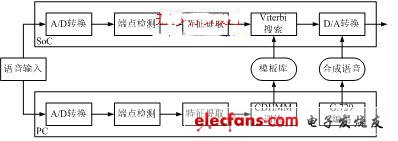
(b) Person-independent system
Figure 2 Identification system framework
The input feature vector of the non-specific person recognition system is 27-dimensional, including 12-dimensional MFCC, 12-dimensional MFCC first-order difference, first-order logarithmic energy, first-order difference energy, and second-order difference energy. The system uses the factor-based CDHMM model as the basic recognition framework and adopts the frame synchronization search algorithm of Viterbi decoding for recognition. The HMM model training is performed on a PC in advance, while the Viterbi search is implemented in real time on a DSP chip. The entire system has a two-layer structure, as shown in Figure 2 (b).
The training phase mainly completes the following tasks: Given an HMM model and a set of observation vectors, an iterative algorithm is used to adjust the model parameters so that the likelihood of the new model and the given set of observation vectors is maximized. First, the initial model is used to estimate the posterior probability of the observation vector being output by all possible state sequences of the hidden layer. Then, based on the estimation results of the previous step, the new HMM model is estimated using the maximum likelihood criterion, and the obtained parameters are used for the next iteration. The recognition phase uses Viterbi search, and the constructed recognition network includes information such as state number and state connection relationship. In order to reduce the memory usage of network search, the method of establishing a separate network for each entry is adopted, so that the search process of each entry can be performed independently in memory [5].
3.2 Voice transmission and interrupt program design
Due to hardware limitations, the system's multi-task scheduling is completed by the interrupt service mechanism. In addition to Reset and non-maskable interrupt (NMI), two DMA channel interrupts are also set. DMA channel 2 is responsible for sending the voice data recorded by the microphone to the DSP core for calculation and processing; DMA channel 3 is responsible for transmitting the playback voice data to the speaker output.
In the memory, there are two 128W receiving buffers and sending buffers. Taking the receiving end as an example, for 8 kHz sampled speech, a 16-bit sampled data is received every 0.125 ms and stored in one of the receiving buffers. After 16 ms, the receiving buffer is full, and the DMA controller sends an interrupt request to the CPU to perform VAD, feature extraction and other operations. At the same time, the other receiving buffer continues to receive voice data. This data transmission method is also called Ping-Pong transmission. Two buffers are set for receiving and sending respectively. Using the waiting time slot, when the data transmission in one buffer is completed and an interrupt is generated, the other buffer continues to work. This double buffer transmission method can significantly improve the real-time performance of the system.
3.3 Endpoint Detection
The speech signal input to the hardware platform often contains a lot of silence or noise before and after. In order to save hardware resources, it is necessary to introduce an endpoint detection algorithm. In order to take into account both real-time performance and hardware resource occupancy rate, and to prevent the recognition performance from being affected by too strict speech segmentation, a four-stage speech real-time detection method based on circular buffer technology is adopted. The speech energy of each frame is compared with the threshold, and the speech energy is stored in a circular buffer of length and the current position is recorded. The algorithm flow is shown in Figure 3, where,,,,, are pre-set thresholds, which are obtained through a large number of tests. When it is detected that the speech energy of consecutive frames is higher than the threshold, the circular buffer is disconnected from the current position, and the rewind frame is used as the speech starting point.

(a) Basic process of endpoint detection
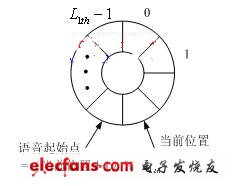
(b) Circular buffer design
Figure 3 Endpoint detection process based on circular buffer
3.4 Feature Extraction and DTW Template Matching of Specific Person Recognition System
Experiments show that using 12-dimensional MFCC coefficients as feature parameters can save memory space without greatly affecting the recognition rate. The feature parameters of each frame of speech are stored continuously in the memory data space. The dynamic time warping (DTW) algorithm is adopted, which is essentially a breadth-first template matching process, that is, comparing the feature vector sequence of the term to be recognized with each template to find a path with the minimum total distortion as the recognition result [6]. The DTW algorithm is simple, has a small amount of calculation, occupies little memory, can solve the problem of uneven speech speed, and is suitable for isolated word recognition systems with small vocabulary of specific people.
3.5 Multi-level Viterbi search and hardware resource consumption analysis of non-specific person recognition system
The bottleneck of the baseline system for non-specific person recognition is that the recognition time is too long. In fact, if the acoustic model is constructed reasonably, the likelihood of most wrong results is often far from the correct result. Therefore, the two-stage search strategy based on Viterbi decoding adopted by this system can greatly alleviate the problem of long recognition time.
The first stage is the fast matching stage. Using a relatively simple 208-state monophonic acoustic model, the top Nbest candidate terms with the highest matching degree are given and sent to the second stage. The main memory space occupied in the first stage is: all features of the terms, when using 27-dimensional features and the maximum effective speech length is 128 frames, 6.8 KB is required; the output score matrix, whose size is determined by the maximum effective speech length and the number of models, is the most important part of the memory overhead, and about 62 KB of memory is required here; the logarithmic likelihood of all terms, in the case of 200 words, is 0.8 KB.
The second stage is the precise matching stage. It uses a more complex 358-state biphone model to build a new recognition network based on the candidate terms in the first stage for search and recognition. In order to save memory usage, the upper limit of the number of candidate terms in the first stage is set to 8. In this way, the number of valid states that may appear in the second stage will not exceed 208, so that the output probability matrix that occupies the largest memory can reuse the memory occupied by the output probability matrix in the first stage, improving memory usage efficiency [7].
4 Experimental Results
The recording environment is an office environment, 8 kHz sampling, 16 bit quantization, the maximum duration of each word is 2 s, and the length of the circular buffer for endpoint detection is 7 W. The test speech of the specific person recognition system is a 100-word person noun list recorded by this laboratory, and the recognition results are shown in Table 1. The training set of the non-specific person recognition system is 863 male continuous speech data, and the test speech is a 200-word person noun list. The results of multi-candidate recognition in the first stage are shown in Figure 4. It can be seen that although the recognition rate of one candidate is less than 94%, as the number of candidate words increases, the correct recognition results are almost all included in the recognition results of the first few choices in the first stage. The recognition rate of the eight-candidate strategy selected in this paper can reach 99.5%. The final recognition results of the system are shown in Table 2. The recognition rate only drops from 98.5% of the baseline system to 97.5%, and the recognition time is only 30% of the baseline system.


Figure 4: Multi-candidate recognition rate of the first stage of the non-specific person system
5 Conclusion
This paper proposes a method for implementing a fixed-point DSP-based system-on-chip for speech recognition of specific and non-specific persons. By reducing the feature dimension and improving speech preprocessing and recognition algorithms, efficient use of hardware resources is achieved while ensuring recognition performance. Under the conditions of a computing speed of 288 MIPS and a working clock of 144 MHz, the recognition rates of the specific and non-specific person recognition systems are 98% and 97.5% respectively, and the recognition times are 0.13 times real-time and 0.34 times real-time respectively.
The innovation of this paper lies in: adopting a four-stage real-time endpoint detection algorithm based on circular buffer technology and a voice transmission method based on double buffer. In the processing of the core recognition algorithm, the appropriate feature dimension is selected and the recognition algorithm process is reasonably optimized. Under the premise of ensuring that the recognition performance is not affected, the hardware resource utilization rate and the real-time performance of the system are effectively improved.
Previous article:Design of Embedded Network Video Encoder Based on TM1300
Next article:FPGA Dilemma: Hybrid System Architecture to Solve
 ICCV2023 Paper Summary: Video Analysis and Understanding
ICCV2023 Paper Summary: Video Analysis and Understanding TMS320VC5507 Data Sheet
TMS320VC5507 Data Sheet MFCC Mel cepstrum parameters and matlab code
MFCC Mel cepstrum parameters and matlab code Accent issues in large vocabulary continuous speech recognition
Accent issues in large vocabulary continuous speech recognition Fundamentals of Analog Electronics Technology
Fundamentals of Analog Electronics Technology Punctual Atomic teaches you step by step how to learn STM32-M7
Punctual Atomic teaches you step by step how to learn STM32-M7 Xiaomei Ge’s FPGA introduction to practical special training class full HD record (2019)
Xiaomei Ge’s FPGA introduction to practical special training class full HD record (2019) Punctual Atomic teaches you step by step how to learn STM32-M4
Punctual Atomic teaches you step by step how to learn STM32-M4 Punctual Atomic teaches you step by step how to learn STM32-M3
Punctual Atomic teaches you step by step how to learn STM32-M3





- High signal-to-noise ratio MEMS microphone drives artificial intelligence interaction
- Advantages of using a differential-to-single-ended RF amplifier in a transmit signal chain design
- ON Semiconductor CEO Appears at Munich Electronica Show and Launches Treo Platform
- ON Semiconductor Launches Industry-Leading Analog and Mixed-Signal Platform
- Analog Devices ADAQ7767-1 μModule DAQ Solution for Rapid Development of Precision Data Acquisition Systems Now Available at Mouser
- Domestic high-precision, high-speed ADC chips are on the rise
- Microcontrollers that combine Hi-Fi, intelligence and USB multi-channel features – ushering in a new era of digital audio
- Using capacitive PGA, Naxin Micro launches high-precision multi-channel 24/16-bit Δ-Σ ADC
- Fully Differential Amplifier Provides High Voltage, Low Noise Signals for Precision Data Acquisition Signal Chain






- Innolux's intelligent steer-by-wire solution makes cars smarter and safer
- 8051 MCU - Parity Check
- How to efficiently balance the sensitivity of tactile sensing interfaces
- What should I do if the servo motor shakes? What causes the servo motor to shake quickly?
- 【Brushless Motor】Analysis of three-phase BLDC motor and sharing of two popular development boards
- Midea Industrial Technology's subsidiaries Clou Electronics and Hekang New Energy jointly appeared at the Munich Battery Energy Storage Exhibition and Solar Energy Exhibition
- Guoxin Sichen | Application of ferroelectric memory PB85RS2MC in power battery management, with a capacity of 2M
- Analysis of common faults of frequency converter
- In a head-on competition with Qualcomm, what kind of cockpit products has Intel come up with?
- Dalian Rongke's all-vanadium liquid flow battery energy storage equipment industrialization project has entered the sprint stage before production
- Allegro MicroSystems Introduces Advanced Magnetic and Inductive Position Sensing Solutions at Electronica 2024
- Car key in the left hand, liveness detection radar in the right hand, UWB is imperative for cars!
- After a decade of rapid development, domestic CIS has entered the market
- Aegis Dagger Battery + Thor EM-i Super Hybrid, Geely New Energy has thrown out two "king bombs"
- A brief discussion on functional safety - fault, error, and failure
- In the smart car 2.0 cycle, these core industry chains are facing major opportunities!
- The United States and Japan are developing new batteries. CATL faces challenges? How should China's new energy battery industry respond?
- Murata launches high-precision 6-axis inertial sensor for automobiles
- Ford patents pre-charge alarm to help save costs and respond to emergencies
- New real-time microcontroller system from Texas Instruments enables smarter processing in automotive and industrial applications
- Audi car engine regularly stops and cannot start. Oscilloscope detection solution
- FPGA design ideas and techniques: data interface synchronization
- After __wfi is run, is the MCU still running the code?
- CC2640 Questions and Answers
- Who is the source manufacturer of the 3651 orthogonal convex tooth sensor? Is there anyone who can be its agent?
- Which is faster for switching, MOS or Darlington?
- How to understand MOS tube parameters
- Various library files for TI DSP28335
- What do you think is a valuable life?
- C64x+ CACHE consistency maintenance operations






 京公网安备 11010802033920号
京公网安备 11010802033920号