1 Introduction
This article aims to study MPEG-4 video decoding technology based on ARM microprocessor, which is mainly used in handheld mobile devices. Using embedded systems to implement MPEG-4 video decoding, processor selection is the key. The RISC processor commonly used in embedded systems is the ARM core, mainly because it has the characteristics of small size, low power consumption, low cost, and high cost performance, which is very important for mobile applications. The ARM7 series microprocessors are low-power 32-bit RISC processors that are most suitable for consumer applications with higher price and power consumption requirements. This decoder is positioned in low-resolution and low-frame-rate applications, so it is chosen to implement the decoding function on the ARM7TDMI core. To achieve higher frame rate and resolution decoding, the software can be applied directly to higher-end processors.
2 Optimization and implementation of MPEG-4 video decoding algorithm
The MPEG-4 standard can be divided into a set of sub-standards, and each part of the standard has its own most suitable application scenarios. MPEG-4 SVP is a special, simple MPEG-4 implementation, and SVP stands for Simple Visual Profile. This part is specially formulated for wireless video transmission applications in handheld products. Since this decoder is used in handheld mobile device video decoding, MPEG-4 SVP is selected as the decoding algorithm.
This article selects ARM7TDMI as the core processor to develop the MPEG-4 video decoder. During the actual development process, a lot of optimization work was done based on the structure of ARM7TDMI and the algorithm characteristics of MPEG-4, ensuring the accuracy of decoding and greatly improving the speed of decoding. The specific functions of the decoder are listed in Table 1.
Table 1 MPEG-4 video decoder function table based on ARM7TDMI
|
Function |
System implementation |
| Compression standard | MPEG-4 SVP |
| Enter image resolution | QCIF (176×144, if you choose a higher-end processor, you can support higher resolutions) |
| Decoding frame rate | 15fps (if you choose a higher-end processor, you can support higher frame rates) |
| VOP type | IVOP+PVOP |
| DC/AC inverse prediction | support |
| Inter4V mode | support |
| Inverse quantization method | H.263(MPEG optional) |
| Reverse scan mode | Zigzag scan + horizontal alternating scan + vertical alternating scan |
| Output image format | 4:2:0 YUV |
2.1 Decoder algorithm
The decoding process is actually the process of recovering VOP data from the video encoding stream. Figure 1 describes a video decoding process. The decoder mainly contains two parts: motion decoding and texture decoding. The I frame only contains texture information, so only the texture information can be decoded to restore the I frame. The P frame not only contains texture information, but also contains motion information, so the motion information must be decoded to obtain the motion vector and perform motion compensation. In addition, texture decoding must be performed to obtain the residual value, and the two parts are combined to reconstruct the P frame.
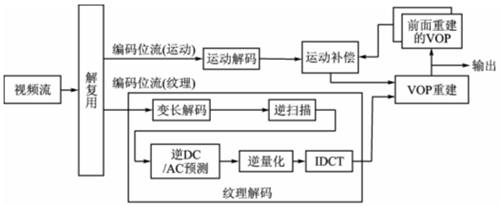
Figure 1 MPEG4 SVP decoding process
The implementation of the decoder mainly provides a simple interface function for calling during decoding. This interface function provides 5 entries according to different needs and stages of decoding. Among the 5 interface functions: 4 are called during initialization, preprocessing and subsequent processing; the remaining 1 is the implementation function of frame decoding. Figure 2 is a flow chart of the main program of frame decoding.

Figure 2 Flow chart of the main program of frame decoding.
The calculation of the decoding process mainly focuses on the following modules: IDCT, motion compensation MC, inverse quantization, inverse scanning, inverse prediction and variable length decoding VLD. Table 2 gives the characteristic information of the decoding process before optimization.
As can be seen from Table 2, the above operation modules occupy a large proportion in the decoding process. The effect of optimizing each of the above modules will be directly reflected in the real-time efficiency of the decoder.
Table 2 Characteristic information of the decoding process before optimization
|
Name of each unit |
Proportion of time occupied by each unit/% |
|
IDCT |
40 |
|
Inverse quantization, inverse scan and inverse prediction |
twenty four |
|
Data analysis and variable length decoding |
14 |
2.2 ARM平台下算法的优化
ARM结构是基于RISC原理的,指令集和相关的解码机制都比CISC要简单得多。它能高效地输出指令,快速送出实时中断响应;它还进行了管道设置,处理和存储系统的所有部分可以持续地运转。在典型的情况下,当一条指令被执行时,其后续指令正在被解码;而第三条指令便从存储器中取出。ARM7TDMI并不具有指令或数据的高速缓存,主要被用于控制核心,而非数据处理。但通过对其特性的灵活运用,可以使其非常容易地应用于视频解码过程。对MPEG4视频解码器的算法优化主要从以下几方面入手:
(1) 算法的优化
这里是指高级C语言转化算法以简化计算量, 用最佳算法实现解码中的各模块。
① IDCT算法的选择
IDCT运行次数多,运算量很大,其变换的快慢直接影响解码的速度。本文采用一种称为AAN的快速算法。其一维8点的DCT变换通过16点DFT来实现,而16点DFT又可通过FFT实现;二维8×8的DCT运算仅需80次乘法和464次加法操作,大大减小了这部分的运算量。用AAN算法实现IDCT运算时,实际上是用IDFT取代IDCT,所以首先要得到DFT系数。方法是逆量化后直接将DCT系数分别乘以尺度因子,也就是说将尺度变换与逆量化结合。
② 除法运算的消除
一个除法操作须花费60~120个周期进行处理,而一个乘法操作最多需要4个周期。在除法可以被乘法代替而不丧失准确性的计算中,这样做是非常有好处的。在反向DC系数预测过程中,DC系数重构后,立即对其进行逆量化,从而消除除法运算。
③ 存储访问的减少
在任何实现中尽可能减少存储访问都是非常有价值的。由于ARM7TDMI内没有缓存,每次访问都是对外部存储器进行的,所以这样做尤为重要。通过在任何可能的地方结合解码过程,访问的次数即可减少。I帧中反向DC系数预测与DC系数逆量化的结合、逆扫描与变长解码的结合,以及逆量化与IDCT的结合,P帧中变长解码、逆扫描与反量化的结合,对于每个非零系数只需一次读入和一次存储。同时,像素重建也在IDCT之后立即进行。这样对每个系数来说,又减少了一次读入和存储。
(2) 根据ARM7TDMI芯片结构的优化
这里的优化主要体现在节约寄存器资源。任何一种芯片的寄存器资源都是有限的,ARM7TDMI的通用寄存器总数为31个,对于小规模应用程序是足够了,但在MPEG4解码过程中往往会用到较多的寄存器,所以仍须节俭。方法如下: 其一,在可能的情况下尽量少用寄存器,比如可对一个寄存器多次使用。其二,根据具体情况选择最优的变量类型,在局部变量中,使用int类型效率最高;而对于全局变量,使用short类型,则可减小Flash的使用量。
(3) 汇编/结构层的优化
尽管编译器可以产生汇编代码,但为了使代码效率更高,根据ARM7TDMI的特性对模块IDCT、IQ、VLD、DC/AC预测和MC进行手工汇编编码。下面详细阐述不同的优化方法及其所使用的模块。
① 内部循环的解开
循环的解开其实也是为了增强程序中的并行处理能力。对于解循环,不能在解开的循环中保留线性过程,即指令在执行过程中的结果不能作为后续指令的输入数据;否则也就失去了并行处理能力,解循环也就失去了意义。
② 乘法和除法尽量用移位运算来完成
对于2的幂次乘法或除法使用移位将会提高不少效率,一条除法指令使用的周期数远远多于移位指令。
③ 尽可能将循环内部的负荷放到循环外面
这点很重要,因为许多循环内部包括一条或几条运算语句,这些语句将被重复运算,因此如果事先设定一个变量,然后赋上那几条运算语句的值,并替换到循环外部,则会极大地节省芯片资源,特别是对于循环中含有除法运算的情况。在逆量化循环运算中,存在着大量冗余计算,原因在于逆量化运算中参数的重复计算,而对于每帧解码VOP,这些参数是唯一的。因此,可将这些参数的计算放到逆量化循环外面,则每帧只须计算一次。这样即可节约大量的指令周期。
④ 功能参数的优化数量
在ARM编译的过程中,子程序的参数是通过寄存器R0~R3来传递的。如果所传递的参数多于4个,那么超出的参数将被压入栈内;当它们在函数中被第一次访问时,便会从栈中弹出。通过把参数的数量减少到4个或者少于4个,则可直接使用,而无需任何的调入,因为这些值都可从寄存器中获得。
⑤ 利用LDM和STM减少存储器的访问
批量加载/存储指令可以实现在一组寄存器和一块连续的内存单元之间传输数据。LDM为加载多个寄存器;STM为存储多个寄存器。这种特性非常有用,因为与单字加载/存储相比,它在执行周期上花费更少。因此它在IDCT中得到了有效的利用,用于同一时刻取出一行的所有系数。同样在运动补偿过程中,一组数据字在指令的一次执行中获得,并且暂时存储在多个寄存器中以便日后使用。
⑥ 指令的有条件执行
有条件执行的特性被ARM7TDMI的所有算法和数据移位指令支持。这是一项可选的特性。它在指令被执行时设置标记。有条件执行通常用于循环退出条件和饱和条件,可以节省退出循环中的一个指令CMP。对于循环次数很多的情况,即使是一个指令的减少也有很大的好处。在变长解码中就很好地利用了这种特性。
⑦ 一种用于运动补偿的有效优化方法
解码过程中处理的像素是8位。如果运动补偿是在字节或像素的基础上执行,那么字节加载和存储将被使用,它是存储器访问中代价最高的操作。因为ARM7TDMI是32位微处理器,存储器可以按字读取数据,因此设计出一种有效的运动补偿方法,即在字数据的基础上进行操作。利用这种方法,便可以用一种非常有效的方式同时对4像素进行运动补偿。
下面以水平方向的半像素补偿为例,讲述补偿的过程。补偿的原理如图3所示。
首先读入一个字到寄存器中,从低到高的数据依次对应的是像素0、像素1、像素2和像素3;然后将读码流指针增加1字节,再读取下一个字到另一寄存器中,从低到高的数据依次对应的为像素1、像素2、像素3和像素4。示意图如图4所示。

图3 半像素内插示意图 图4 4像素补偿原理示意图
Half-pixel compensation can be achieved by x=(A+B+1-rounding_control)/2. In the formula: A and B are two adjacent pixel data in the reference frame; rounding_control can be 0 or 1.
The above two registers are added and shifted according to the compensation formula, but a carry may occur when the corresponding pixels are added two by two. In order to solve this problem, the protection bit must be set. The specific method is as follows:
- If any one of the above two registers (such as register 1) is ANDed with 0xFEFEFEFF, then the lowest bit of pixels 1, 2, and 3 in register 1 will be cleared to 0, that is, the lowest bit of the next byte will be set to the previous one. Byte protection bit. For the third byte, because the register itself has a carry status flag, there is no need to set it separately.
- If rounding_control is 0, add register 2 to 0x01010101, and then "AND" with 0xFEFEFEFF to set the carry protection bit; if rounding_control is 1, directly "AND" register 2 with 0xFEFEFEFF.
- Add the results of the above two steps to determine the carry status flag. If there is a carry, the highest bit of the addition result, which is the 31st bit of the register, is set to 1, and finally shifted right by 1 bit. The result is the compensated 4 pixel values.
In the process of compensating 4 pixels at the same time, a carry will occur only when the highest bits of two adjacent pixels are both 1. Using this compensation method actually sacrifices part of the accuracy, but here it only increases the affected pixel value by 1, so the impact is not large, and the compensation speed can be greatly improved. In the process of compensating 4 pixels at the same time, register loading requires 3 cycles and storage requires 2 cycles. There are two loading and one storage operations. The intermediate addition and shift operations require 6 instruction cycles, totaling 14 cycles. . If the above four pixels are compensated separately, 5 loading operations and 4 storage operations are required, a total of 23 cycles. In addition, the intermediate calculation requires 12 cycles, so a total of 35 cycles are required. It can be seen that it is worth sacrificing some accuracy in exchange for compensation speed.
For half-pixel compensation in the vertical and horizontal directions, the principle is the same as in the horizontal direction.
3 Experimental results and data analysis
Through optimization, the decoding performance of MPEG4 has been greatly improved. C algorithm optimization and ARM code optimization were performed on each module in the ADS1.2 environment, and the results are listed in Table 3. Statistics are based on the number of cycles required to call a module function.
Table 3 Individual statistics of each module on the emulator (using QCIF format image news)
|
Optimized module name |
C optimization (cycles)/piece |
ARM optimization (cycles)/piece |
Optimization rate/% |
|
DC/AC Forecast |
703 |
534 |
24.04 |
|
Reverse scan/VLD |
1 730 |
1 118 |
35.38 |
|
Inverse quantization/IDCT |
6 032 |
2 562 |
57.53 |
|
motion compensation |
17 143 |
8 471 |
50.59 |
These modules are functions that are often called during the decoding process. Therefore, the optimization of these functions will significantly improve the decoding speed.
Table 4 compares the bandwidth required for different sequences of 15-frame QCIF format video decoding before and after optimization. These images have different complexities and therefore different results.
Table 4 Optimization results for different sequences (15fps QCIF format)
|
Video sequence① |
Required bandwidth/MHz before optimization |
Required bandwidth/MHz after optimization |
|
news |
27.24 |
16.86 |
|
foreman |
64.83 |
48.78 |
|
miss_am |
27.71 |
15.95 |
|
carphone |
52.54 |
34.52 |
|
salesman |
28.06 |
16.56 |
|
trevor |
52.56 |
34.24 |
Note: ① is a standard video test sequence.
The decoding speed basically depends on the movement of the image and whether the color is rich. It can be seen from the above data that the decoding speed is different for different sequences. The reason why news, salesman and miss_am are very fast is because the background of the image is still and only the shoulders and head move. Therefore, the amount of encoded data of the P frame is smaller and the decoding speed is higher. In addition, if the image is very simple (monotone), its energy is concentrated on the DC coefficient (direct current component), and the AC coefficient will have multiple zeros, so the variable-length decoding speed will be higher, thus saving decoding time.
From the simulation speed analysis, through the optimization method of video decoding on ARM7TDMI summarized in this article, MPEG4 video decoding can save a lot of data processing time. It can be seen from the experimental results that this video decoder can better meet the requirements of real-time decoding in low resolution and low frame rate situations.
4 Embedded system implementation of MPEG4 video decoding
The main hardware platform to implement this decoder is Easy ARM2200, as shown in Figure 5. It is a powerful 32-bit ARM microcontroller development board, using the ARM7TDMIS core of Philips Company and the open-bus microcontroller LPC2210, with JTAG debugging function.

Figure 5 Easy ARM2200 development board
In addition to providing some common functional components such as keyboard, LED and RS232, the development board also has 4Mb SRAM, 16Mb FLASH, IDE hard disk interface, CF memory card interface, Ethernet interface and Modem interface.
This article chooses to debug the MPEG4 decoding program on the μClinux operating system. The debugging process is divided into the following steps:
- Establish μClinux development environment;
- Develop applications under μClinux;
- Add the application to the target system and debug it.
Figure 6 is a typical framework structure diagram of an embedded system based on μClinux.

Figure 6 Embedded system block diagram based on μClinux
(1) Establishing a μClinux development environment
In order to realize the development of application systems based on μClinux, it is necessary to establish or have a complete μClinux development environment. Establishing a μClinux development environment mainly includes the following three steps:
- Build a cross-compiler;
- Compile μClinux kernel;
- Load the kernel.
After completing all the above work, an embedded application development platform has been built. On this platform, embedded applications can be developed according to different needs.
(2) Develop applications under μClinux The
development of applications based on μClinux system is usually done on the standard Linux platform using the cross-compilation tool armelfgcc. ADS and armelfgcc are software development tools provided by ARM. They both support the ARM instruction set, but some pseudo-instruction sets are different. Therefore, in order to transplant the source code optimized in the ADS1.2 environment to the armelfgcc environment, it is necessary to modify the pseudo-instructions of the source code, and then use armelfgcc to compile the source file to generate a program that can be used in An executable program running on the target board.
(3) Add the application to the target system and debug it
. To debug on the hardware board, you must first add the executable program of the application software to the target system. There are many ways to achieve this. This article uses the network method to add user programs from the network to run in the target system through the Ethernet interface.
After completing the above work, the MPEG4 decoding program can be run on the μClinux system, and the decoding result data stream is dynamically transmitted to the PC through Ethernet. The frame rates for decoding several typical QCIF format images are listed in Table 5.
Table 5 Frame rate of MPEG4 video decoding in μClinux operating system
|
video sequence |
Actual decoded frame rate/frame/s |
|
news |
35 |
|
foreman |
16 |
|
miss_am |
37 |
|
carphone |
17 |
|
salesman |
36 |
|
trevor |
17 |
The observed findings are consistent with the previous software simulation results. For images such as the sequences news, miss_am, and salesman, which have small movements, the decoding frame rate is significantly higher; while for images such as foreman, carphone, and trevor, which have large movements, the decoding frame rate is lower.
Experimental results show that this system can achieve real-time decoding of embedded MPEG4 videos with low frame rate and low resolution.
5 Conclusion
This article focuses on the algorithm optimization and hardware implementation of MPEG4 real-time decoding based on the ARM development platform. Mainly completed the following aspects of work: For the ARM7TDMI architecture, algorithm optimization and code optimization were performed on key parts of decoding, thereby greatly improving the decoding speed; For the specific hardware platform - the Eeay ARM2200 development board based on ARM7TDMI, Established the μClinux development environment, developed applications on it, added them to the target system and debugged them, and finally completed the real-time implementation of the 15fps MPEG4 video decoding embedded system.
As people's requirements for visual media become higher and higher, video decoding technology based on embedded systems will have increasingly broad prospects.
Previous article:How to convert an LCD monitor into a TV
Next article:ARM-based MPEG4 video decoder
- Popular Resources
- Popular amplifiers
 TC52N2328ECTRT
TC52N2328ECTRT- Innovation is not limited to Meizhi, Welling will appear at the 2024 China Home Appliance Technology Conference
- Enjoy big-screen gaming anytime, anywhere: Making portable 4K UHD 240Hz gaming projector a reality
- AMD surpasses Intel: CPU shipments surge in Q3 this year
- Exynos is losing ground, Samsung plans to use Qualcomm chips in home appliances
- Intel and 50 partners unveiled a full range of 30 notebook and desktop AI PCs equipped with Intel Core Ultra (2nd Generation)
- Innovation leads the new trend of mobile refrigeration GMCC will present new products at 2024 CIAAR
- Lenovo and NVIDIA expand collaboration to jointly launch new liquid-cooled AI servers
- Ceiling fan solution based on XMC1302
- Gartner: Global AI PC shipments are expected to account for 43% of total PC shipments in 2025






- Innolux's intelligent steer-by-wire solution makes cars smarter and safer
- 8051 MCU - Parity Check
- How to efficiently balance the sensitivity of tactile sensing interfaces
- What should I do if the servo motor shakes? What causes the servo motor to shake quickly?
- 【Brushless Motor】Analysis of three-phase BLDC motor and sharing of two popular development boards
- Midea Industrial Technology's subsidiaries Clou Electronics and Hekang New Energy jointly appeared at the Munich Battery Energy Storage Exhibition and Solar Energy Exhibition
- Guoxin Sichen | Application of ferroelectric memory PB85RS2MC in power battery management, with a capacity of 2M
- Analysis of common faults of frequency converter
- In a head-on competition with Qualcomm, what kind of cockpit products has Intel come up with?
- Dalian Rongke's all-vanadium liquid flow battery energy storage equipment industrialization project has entered the sprint stage before production
- Allegro MicroSystems Introduces Advanced Magnetic and Inductive Position Sensing Solutions at Electronica 2024
- Car key in the left hand, liveness detection radar in the right hand, UWB is imperative for cars!
- After a decade of rapid development, domestic CIS has entered the market
- Aegis Dagger Battery + Thor EM-i Super Hybrid, Geely New Energy has thrown out two "king bombs"
- A brief discussion on functional safety - fault, error, and failure
- In the smart car 2.0 cycle, these core industry chains are facing major opportunities!
- The United States and Japan are developing new batteries. CATL faces challenges? How should China's new energy battery industry respond?
- Murata launches high-precision 6-axis inertial sensor for automobiles
- Ford patents pre-charge alarm to help save costs and respond to emergencies
- New real-time microcontroller system from Texas Instruments enables smarter processing in automotive and industrial applications
- Working principle of three-leg boost inductor
- Looking for a simple speed sensor or module
- Communication Principles of the University Hall
- French oled screen
- Help: Can’t add bookmarks to PDF files using Foxit Reader?
- Help: Tongji University Advanced Mathematics Volumes 1 and 2, electronic version, any edition
- L3GD20 three-axis gyroscope data sheet, driver code, package
- About SAR ADC front-end conditioning
- FPGA Experiment (IV) PWM Breathing Light Based on HDL Language
- Some acreage meters made with STM32 for DIY buddies to play with






 京公网安备 11010802033920号
京公网安备 11010802033920号