

Still worried about slow data transfer? Linux zero-copy technology can help you!
Preface
What is the ultimate pursuit of programmers? When the system traffic increases, the user experience remains smooth? That's right! However, in the scenario of large-scale file transfer and data transmission, the traditional "data handling" slows down the performance. In order to solve this pain point, Linux introduced the Zero Copy technology, which allows efficient data transmission without the CPU having to worry about it. Today, I will use the most popular language to explain the working principle, common implementation methods and practical applications of zero copy, and help you thoroughly understand this technology!
1. Traditional copying: the “old era” of data transfer
To understand zero copy, let's first look at how traditional data transfer works. Imagine that we need to read a large file from the hard disk and send it to the network. This sounds simple, but in fact, traditional data transfer involves multiple steps and takes up a lot of CPU resources.
1.1 A typical file transfer process (without DMA technology):
Suppose we want to read a large file from the hard disk and send it to the network. Here are the detailed steps of the traditional copy method:
-
Read data into kernel buffer : Using
read()the system call, data is read from the hard disk into the kernel buffer. At this point, the CPU needs to coordinate and execute related instructions to complete this step. -
Copy data to user buffer : Data is copied from kernel buffer to user space buffer. This step
read()is triggered by call, and CPU is fully responsible for this data copy. -
Writing data to the kernel buffer : Through
write()the system call, the data is copied back from the user buffer to the kernel buffer again. The CPU intervenes again and is responsible for data copying. -
Transfer data to the network card : Finally, the data in the kernel buffer is transferred to the network card and sent to the network. If there is no DMA technology, the CPU needs to copy the data to the network card.
1.2 Let's look at a picture, which is more intuitive:

1.3 “Four copies” of data transmission
During this process, the data is copied four times in the system:
-
Hard disk -> kernel buffer (CPU involved, responsible for data reading and transmission)
-
Kernel buffer -> user buffer (
read()call trigger, CPU is responsible for copying) -
User buffer -> kernel buffer (
write()call trigger, CPU is responsible for copying) -
Kernel buffer -> NIC (finally sends data, CPU participates in transmission)
1.4 Performance Bottleneck Analysis
The problems with this traditional copying method are obvious:
-
High CPU resource usage : Each
read()andwrite()call requires the CPU to copy data multiple times, which seriously occupies CPU resources and affects the execution of other tasks. -
Memory usage : When the amount of data is large, memory usage increases significantly, which may cause system performance to deteriorate.
-
Context switching overhead : Each
read()andwrite()call involves switching between user mode and kernel mode, which increases the burden on the CPU.
These problems are particularly evident when processing large files or high-frequency transmissions. The CPU is forced to act as a "porter", and performance is severely limited. So, is there a way to reduce the CPU's "porting" work? At this time, DMA (Direct Memory Access) technology comes on the scene.
2. DMA: A prelude to zero copy
DMA (Direct Memory Access) is a technology that allows data to be transferred directly between the hard disk and the memory without the CPU's byte-by-byte involvement. In simple terms, DMA is a "good helper" for the CPU, reducing its workload.
2.1 How does DMA help the CPU?
In traditional data transmission, the CPU needs to move data from the hard disk to the memory and then send it to the network, which consumes a lot of CPU resources. The emergence of DMA allows the CPU to do less work:
-
Hard disk to kernel buffer : Completed by DMA. The CPU only needs to issue instructions, and DMA will automatically copy the data to the kernel buffer.
-
Kernel buffer to network card : DMA can also handle this part, sending the data directly to the network card, and the CPU only needs to supervise the overall process.
With DMA, the CPU only needs to say: "Hey, DMA, move the data from the hard disk to the memory!" Then the DMA controller will take over the job and automatically transfer the data from the hard disk to the kernel buffer, and the CPU only needs to supervise it.
2.2 With DMA, let's take a look at the data transmission process:
To better understand the role of DMA in the entire data transfer, we use a diagram to illustrate:
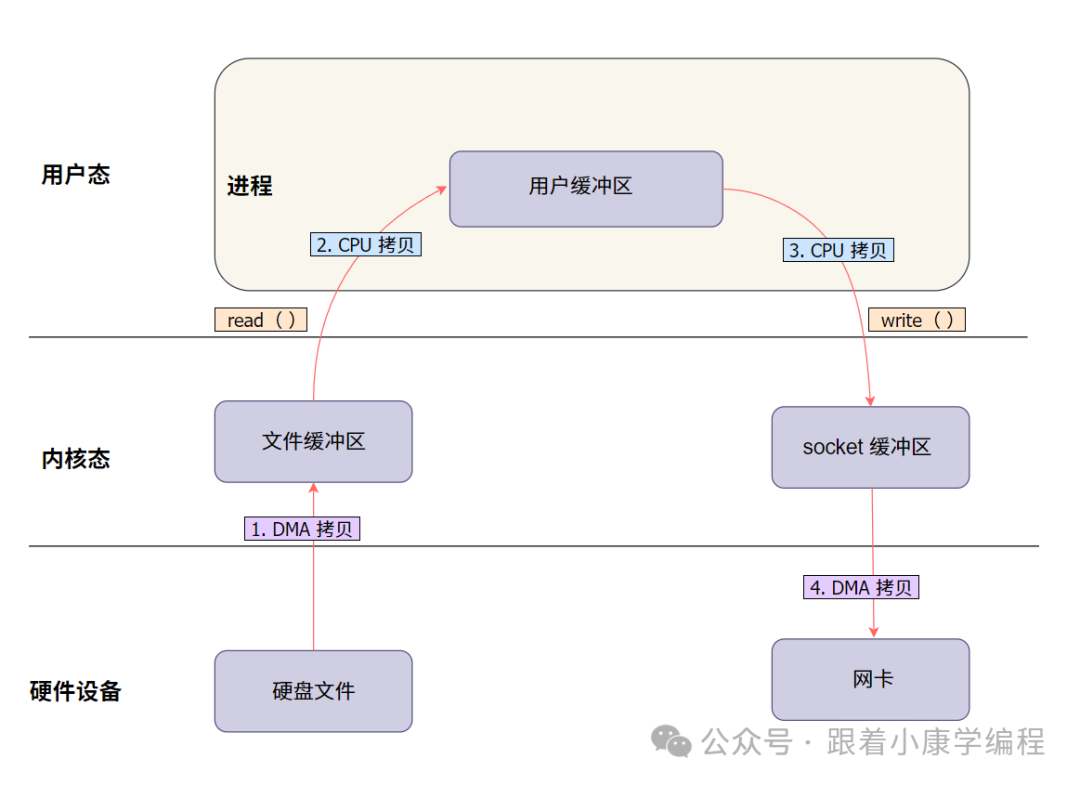
illustrate :
-
DMA is responsible for transmission from the hard disk to the kernel buffer and from the kernel to the network card.
-
The CPU still has to handle data transfers between the kernel and user buffers.
2.3 Which steps still require CPU participation?
Although DMA can help the CPU share some tasks, it cannot fully delegate all data copying work. The CPU still has to be responsible for the following two things :
-
Kernel buffer to user buffer : Data needs to be copied by the CPU to user space for use by the program.
-
The user buffer returns to the kernel buffer : After the program processes the data, the CPU has to copy the data back to the kernel in preparation for subsequent transmission.
It's like hiring a helper, but you still have to do some of the detailed work yourself. Therefore, when there is high concurrency or large file transfer, the CPU will still feel pressure from these copy tasks.
2.4 Summary
In summary, DMA does reduce the burden on the CPU in data transmission, allowing data to be transferred from the hard disk to the kernel buffer and from the kernel buffer to the network card without the involvement of the CPU. However, DMA cannot completely solve the problem of copying data between the kernel and user space. The CPU still needs to carry out two data transfers, especially in high concurrency and large file transfer scenarios, this limitation becomes particularly prominent.
3. Zero copy: Let data "go directly"
Therefore, in order to further reduce CPU involvement and improve transmission efficiency, Linux introduced the zero-copy technology. The core goal of this technology is to allow data to flow directly in the kernel space, avoiding redundant copies in the user space, thereby minimizing the CPU's memory copy operations and improving system performance.
Next, let's take a closer look at several major zero-copy implementations in Linux:

“Note : The implementation of zero-copy technology in Linux requires hardware support for DMA.
3.1 sendfile: the earliest zero-copy method
sendfile
It is the first zero-copy method introduced in Linux and is designed specifically for file transfer.
3.2 sendfile workflow
-
DMA (Direct Memory Access) loads file data directly into kernel buffers.
-
Data goes directly from the kernel buffer into the socket kernel buffer in the network protocol stack.
-
After the data is processed by the network protocol stack, it is sent directly to the network through the network card.
Through
sendfile
, the CPU only needs to copy data once during the entire transmission process, reducing CPU usage.
3.3 Simple diagram:
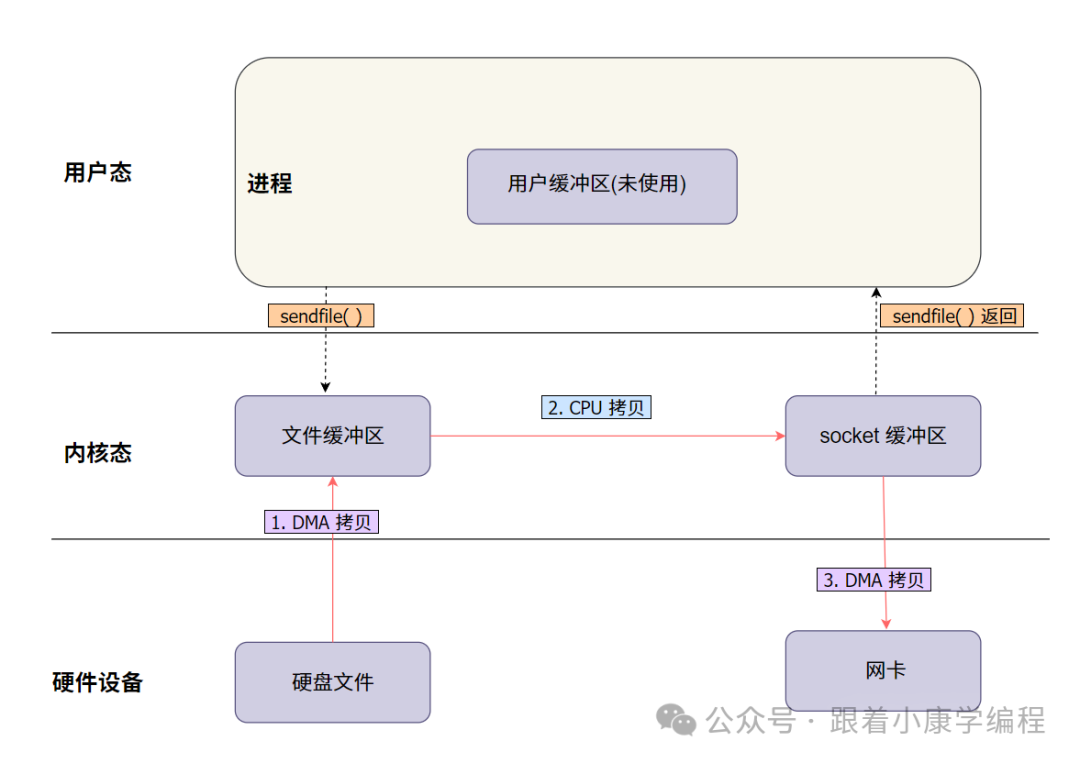
sendfile
Illustration:
-
Reading data from the hard disk : File data is read from the hard disk via DMA and directly loaded into the kernel buffer. This process does not require the participation of the CPU.
-
Copy data to the socket buffer of the network protocol stack : The data does not enter the user space, but directly enters the socket buffer in the network protocol stack from the kernel buffer, where it undergoes necessary protocol processing (such as TCP/IP encapsulation).
-
Data is sent through the network card : Data is ultimately sent directly to the network through the network card.
3.4 sendfile API Description
sendfile
The function definition is as follows:
ssize_t sendfile(int out_fd, int in_fd, off_t *offset, size_t count);
-
out_fd: Target file descriptor, usually a socket descriptor, used for network sending. -
in_fd: Source file descriptor, usually a file read from disk. -
offset: Offset pointer, used to specify the position of the file from which to start reading. IfNULL, reading starts from the current offset position. -
count: The number of bytes to transfer.
The return value is the number of bytes actually transferred. If an error occurs, it is returned
-1
and is set
errno
to indicate the cause of the error.
3.5 Simple code example
#include <sys/sendfile.h>
int main() {
int input_fd = open("input.txt", O_RDONLY);
int server_fd = socket(AF_INET, SOCK_STREAM, 0);
struct sockaddr_in address;
address.sin_family = AF_INET;
address.sin_addr.s_addr = INADDR_ANY;
address.sin_port = htons(8080);
bind(server_fd, (struct sockaddr *)&address, sizeof(address));
listen(server_fd, 3);
int client_fd = accept(server_fd, NULL, NULL);
sendfile(client_fd, input_fd, NULL, 1024);
close(input_fd);
close(client_fd);
close(server_fd);
return 0;
}
This example shows how to use
sendfile
to send a local file to a client connected over the network. With just one call
sendfile
, the data is
input_fd
transferred directly from to
output_fd
.
3.6 Applicable Scenarios
sendfile
It is mainly used to transfer file data directly to the network. It is very suitable for situations where large files need to be transferred efficiently, such as file servers, streaming media transmission, backup systems, etc.
In traditional data transmission methods, data needs to go through multiple steps:
-
First, the data is read from the hard disk into kernel space.
-
Then, the data is copied from kernel space to user space.
-
Finally, the data is copied from the user space back to the kernel and sent to the network card.
In summary : sendfile can make data transmission more efficient and reduce CPU intervention, which is particularly suitable for simple large file transfer scenarios. However, if you encounter more complex transmission requirements, such as moving data between multiple different types of file descriptors, splice provides a more flexible method. Next, let's see how splice achieves this.
4. splice: Pipeline zero copy
splice
It is another data transfer system call in Linux that implements zero copy. It is designed for efficient data movement between different types of file descriptors. It is suitable for transferring data directly in the kernel to reduce unnecessary copies.
4.1 Splice workflow
-
Reading data from a file : Use
splicethe system call to read data from an input file descriptor (such as a hard disk file), and the data goes directly into the kernel buffer via DMA (direct memory access). -
Transfer to network socket : Then,
splicecontinue to transfer the data in the kernel buffer directly to the file descriptor of the target network socket.
The entire process is completed in kernel space, avoiding round-trip copying of data from kernel space to user space, greatly reducing CPU involvement and improving system performance.
4.2 Simple diagram:
Similar to the sendfile diagram, but with a different interface.

splice
Illustration:
Data
splice
is transferred from the file descriptor to the network socket via . The data first enters the kernel buffer via DMA and then is directly transferred to the network socket. The entire process avoids the intervention of user space and significantly reduces the CPU's copy work.
4.3 splice interface description
splice
The function is defined as follows:
ssize_t splice(int fd_in, loff_t *off_in, int fd_out, loff_t *off_out, size_t len, unsigned int flags);
-
fd_in: Source file descriptor, data is read from here. -
off_in: Pointer to the source offset, if NoneNULLthen the current offset is used. -
fd_out: Destination file descriptor, data will be written here. -
off_out: Pointer to the target offset, if NoneNULLthen the current offset is used. -
len: The number of bytes to transfer. -
flags: Signs of control behavior, such asSPLICE_F_MOVE,SPLICE_F_MOREetc.
The return value is the number of bytes actually transferred. If an error occurs, it is returned
-1
and is set
errno
to indicate the cause of the error.
4.4 Simple code example
int main() {
int input_fd = open("input.txt", O_RDONLY);
int server_fd = socket(AF_INET, SOCK_STREAM, 0);
struct sockaddr_in address;
address.sin_family = AF_INET;
address.sin_addr.s_addr = INADDR_ANY;
address.sin_port = htons(8080);
bind(server_fd, (struct sockaddr *)&address, sizeof(address));
listen(server_fd, 3);
int client_fd = accept(server_fd, NULL, NULL);
splice(input_fd, NULL, client_fd, NULL, 1024, SPLICE_F_MORE);
close(input_fd);
close(client_fd);
close(server_fd);
return 0;
}
This example shows how to use
splice
to send a local file directly to a network socket for efficient data transfer.
4.5 Applicable Scenarios
splice
It is suitable for efficient and direct data transfer between file descriptors, such as transferring from files to network sockets, or transferring data between files, pipes, and sockets. In this case, data is transferred in kernel space without entering user space, which significantly reduces the number of copies and CPU involvement. In addition, splice is particularly suitable for scenarios that require flexible data flow and reduce CPU burden, such as log processing, real-time data stream processing, etc.
4.6 Differences between sendfile and splice
Although sendfile and splice are both zero-copy technologies provided by Linux for efficiently transferring data in kernel space, there are some significant differences in their application scenarios and functions:
Data flow mode :
-
sendfile: directly transfers the data in the file from the kernel buffer to the socket buffer, which is suitable for file-to-network transmission. Suitable for scenarios that require simple and efficient file-to-network transmission.
-
splice: More flexible, it can transfer data between any file descriptors, including files, pipes, sockets, etc. Therefore, splice can realize more complex data flow between files, pipes and sockets.
Applicable scenarios :
-
sendfile: Mainly used for transferring files to the network, it is very suitable for scenarios that require efficient file transfer, such as file servers and streaming media.
-
splice: More suitable for complex data flow scenarios, such as situations where multi-step transmission or flexible control of data flow is required between files, pipes, and networks.
flexibility :
-
sendfile: Used to send files to the network directly and efficiently. Although the operation is simple, the performance is very efficient.
-
splice: can be used in conjunction with pipelines to achieve more complex data flow control, such as processing data through a pipeline before sending it to the target location.
5. mmap + write: mapped zero copy
In addition to the above two methods,
mmap
+
write
is also a common zero-copy implementation method. This method mainly reduces the steps of data copying through memory mapping.
5.1 mmap + write workflow
-
Use
mmapthe system call to map the file into the virtual address space of the process, so that the data can be directly shared between the kernel space and the user space without the need for additional copy operations. -
Use
writethe system call to write the mapped memory area directly to the target file descriptor (such as a network socket) to complete the data transfer.
This method reduces data copying and improves efficiency, and is suitable for scenarios where data needs to be flexibly manipulated before being sent. In this way, data does not need to be explicitly copied from kernel space to user space, but is shared through mapping, thereby reducing unnecessary copying.
5.2 Simple diagram:

mmap + write
Illustration:
-
Use
mmapto map file data into the process's virtual address space, avoiding explicit data copying. -
Directly
writesend the mapped memory area data to the target file descriptor (such as a network socket).
5.3 mmap interface description
mmap
The function is defined as follows:
void *mmap(void *addr, size_t length, int prot, int flags, int fd, off_t offset);
-
addr: Specifies the starting address of the mapped memory, usuallyNULLdetermined by the system. -
length: The size of the memory area to be mapped. -
prot: Protection flag of the mapped area, for examplePROT_READ,PROT_WRITE. -
flags: Properties that affect the mapping, for exampleMAP_SHARED,MAP_PRIVATE. -
fd: File descriptor, pointing to the file that needs to be mapped. -
offset: The offset in the file, indicating where the mapping starts in the file.
MAP_FAILED
The return value is a pointer to the mapped memory area, which is returned and set
when an error occurs
errno
.
5.4 Simple code example
int main() {
int input_fd = open("input.txt", O_RDONLY);
struct stat file_stat;
fstat(input_fd, &file_stat);
char *mapped = mmap(NULL, file_stat.st_size, PROT_READ, MAP_PRIVATE, input_fd, 0);
int server_fd = socket(AF_INET, SOCK_STREAM, 0);
struct sockaddr_in address;
address.sin_family = AF_INET;
address.sin_addr.s_addr = INADDR_ANY;
address.sin_port = htons(8080);
bind(server_fd, (struct sockaddr *)&address, sizeof(address));
listen(server_fd, 3);
int client_fd = accept(server_fd, NULL, NULL);
write(client_fd, mapped, file_stat.st_size);
munmap(mapped, file_stat.st_size);
close(input_fd);
close(client_fd);
close(server_fd);
return 0;
}
This example shows how to use
mmap
to map a file into memory and then
write
send the data to a network-connected client via .
5.5 Applicable Scenarios
mmap
+
write
is suitable for scenarios that require flexible manipulation of file data, such as the need to modify or partially process the data before sending it. Compared with
sendfile
,
mmap
+
write
provides greater flexibility because it allows access to data content in user mode, which is very useful for application scenarios that require pre-processing of files, such as compression, encryption, or data conversion.
However, this approach also brings more overhead, because the data needs to be exchanged between user mode and kernel mode, which increases the cost of system calls. Therefore,
mmap
+
write
is more suitable for situations where some custom processing is required before data transmission, and is not suitable for purely efficient transmission of large files.
6. tee: Zero-copy data replication
tee
It is a zero-copy method in Linux that can copy data from one pipe to another pipe while retaining the data in the original pipe. This means that data can be sent to multiple targets at the same time without affecting the original data flow, which is very suitable for scenarios such as logging and real-time data analysis that require the same data to be sent to different places.
6.1 tee workflow
-
Copy data to another pipe :
teeThe system call can copy data from one pipe to another without changing the original data. This means that data can be used for different purposes in kernel space at the same time without being copied in user space.
6.2 tee interface description
tee
The function is defined as follows:
ssize_t tee(int fd_in, int fd_out, size_t len, unsigned int flags);
-
fd_in: Source pipe file descriptor, data is read from here. -
fd_out: Target pipe file descriptor, data will be written here. -
len: The number of bytes to copy. -
flags: Flags that control behavior, such asSPLICE_F_NONBLOCKetc.
The return value is the number of bytes actually copied. If an error occurs, is returned
-1
and is set
errno
to indicate the cause of the error.
6.3 Simple code example
int main() {
int pipe_fd[2];
pipe(pipe_fd);
int server_fd = socket(AF_INET, SOCK_STREAM, 0);
struct sockaddr_in address;
address.sin_family = AF_INET;
address.sin_addr.s_addr = INADDR_ANY;
address.sin_port = htons(8080);
bind(server_fd, (struct sockaddr *)&address, sizeof(address));
listen(server_fd, 3);
int client_fd = accept(server_fd, NULL, NULL);
// 使用 tee 复制数据
tee(pipe_fd[0], pipe_fd[1], 1024, 0);
splice(pipe_fd[0], NULL, client_fd, NULL, 1024, SPLICE_F_MORE);
close(pipe_fd[0]);
close(pipe_fd[1]);
close(client_fd);
close(server_fd);
return 0;
}
This example shows how to use
tee
to copy data in a pipe and
splice
send the data to a network socket through , thereby achieving efficient data transfer and replication.
6.4 Applicable Scenarios
tee
It is very suitable for scenarios where data needs to be sent to multiple targets at the same time, such as real-time data processing, logging, etc. Through
tee
, multi-target data replication can be achieved in the kernel space, improving system performance and reducing CPU burden.
Summary and comparison:
Below I summarize several zero-copy methods of Linux for your reference:
| method | describe | Zero copy type | CPU participation | Applicable scenarios |
|---|---|---|---|---|
| sendfile | Send file data directly to the socket without copying it to user space. | Completely zero copy | Very rarely, data is transferred directly. | Large file scenarios such as file servers and video streaming. |
| splice | Efficiently transfer data between file descriptors within kernel space. | Completely zero copy | Very little, entirely within the kernel. | Complex transmission scenarios between files, pipes and sockets. |
| mmap + write | Map the file to memory and use write to send data, flexibly process data | Partial Zero Copy | Medium, requires mapping and writing. | Scenarios where data needs to be processed or modified, such as compression and encryption. |
| tee | Copies data from one pipeline to another without consuming the original data. | Completely zero copy | Rarely, data is copied in the kernel. | Multi-target scenarios such as log processing and real-time data monitoring. |
at last:
I hope this article has given you a more comprehensive and clearer understanding of Linux's zero-copy technology! These technologies may seem a bit complicated, but once you master them, you will find that they are very simple and very practical in actual projects.
end
A bite of Linux
Follow and reply【 1024 】 to get a large amount of Linux information
Collection of wonderful articles
Recommended articles






 京公网安备 11010802033920号
京公网安备 11010802033920号