1 Introduction to TMS320F2812
TMS320F2812 is a high-performance, multi-functional, cost-effective 32-bit fixed-point DSP chip for control from TI. The chip is compatible with the TMS320LF2407 instruction system and can work at a maximum frequency of 150MHz. It has 18k×16-bit 0-wait cycle on-chip SRAM and 128k×16-bit on-chip FLASH (access time 36ns). Its on-chip peripherals mainly include 2×8-channel 12-bit ADC (fastest conversion time 80ns), 2-channel SCI, 1-channel SPI, 1-channel McBSP, 1-channel eCAN, etc. It also has two event management modules (EVA, EVB), including 6-channel PWM/CMP, 2-channel QEP, 3-channel CAP, and 2-channel 16-bit timers (or TxPWM/TxCMP). In addition, the device has three independent 32-bit CPU timers and up to 56 independently programmable GPIO pins, which can be expanded to 1M×16-bit program and data memory. The TMS320F2812 adopts Harvard bus structure, has password protection mechanism, and can perform dual 16×16 multiplication and addition and 32×32 multiplication and addition operations, thus taking into account the dual functions of control and fast calculation.
This paper focuses on the fast calculation that can be achieved through reasonable system configuration and programming of the TMS320F2812 fixed-point DSP chip.
2 TMS320F2812 basic system configuration
2.
1 TMS320F2812 clock
The on-chip peripherals of TMS320F2812 can be divided into the following four groups according to the input clock:
(1) SYSOUTCLK group: includes CPU timer and eCAN bus, which can be dynamically modified by PLLCR register;
(2) OSCCLK group: mainly watchdog circuit, the frequency division coefficient is set by the WDCR register;
(3) Low-speed group: There are SCI, SPI, McBSP, and the frequency division coefficient can be set by the LOSPCP register;
(4) High-speed group: including EVA/B and ADC, the frequency division coefficient can be set by the HISPCP register.
In order to make the system work faster, except for a few places such as timers and SCI that require low-speed clocks, other peripherals can work at 150MHz clock.
2.2 Storage Space
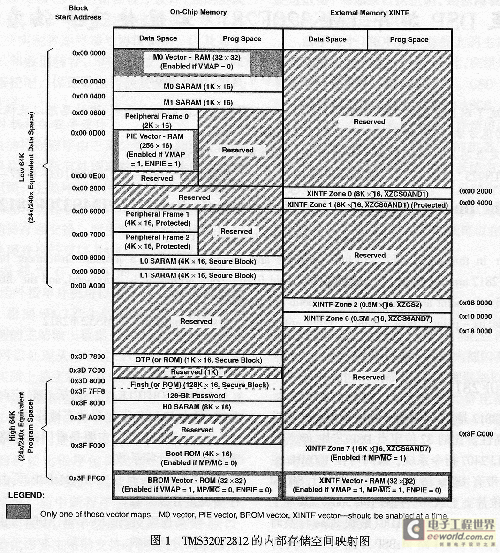
Figure 1 shows the internal storage space mapping diagram of TMS320F2812. TMS320F2812 is a Harvard structure DSP, which means that it can fetch instructions, read data, and write data at the same time in the same clock cycle. Logically, there are 4M×16-bit program space and 4M×16-bit data space, but physically, the program space and data space have been unified into a 4M×16-bit storage space. The order of priority of each bus from high to low is: data write, program write, data read, program read. The 256k×16-bit SARAM extended by CY7C1041 is located in Zone 6 (0x100000~0x13FFFF), and the access time is not less than 12ns; the 128k×16-bit FLASH space (0x3D8000~0x3F7FFF) has an instruction fetch time of not less than 36ns. In order to maximize the working speed of the device, while programming the FLASH register to make it work at a higher speed, the programs with strict time requirements (such as delay calculation subroutines, FIR filter subroutines, etc.) and variables (such as FIR filter coefficients, weight vectors of adaptive algorithms, etc.) can be moved to the H0, L0, L1, M0, and M1 spaces for operation.
2.3 Interruptions
The TMS320F28x series DSPs have a very rich set of peripherals on the chip, and each on-chip peripheral can generate one or more interrupt requests. The interrupt consists of two levels, one of which is the PIE interrupt and the other is the CPU interrupt. The CPU interrupt has 32 interrupt sources, including RESET, NMI, EMUINT, ILLEGAL, 12 user-defined software interrupts USER1 to USER12, and 16 maskable interrupts (INT1 to INT14, RTOSINT, and DLOGINT). All software interrupts are non-maskable interrupts. Since the CPU does not have enough interrupt sources to manage all on-chip peripheral interrupt requests, a peripheral interrupt expansion controller (PIE) is set up in the TMS320F28x series DSP to manage interrupt requests caused by on-chip peripherals and external pins.
There are 96 PIE interrupts, which are divided into 12 groups. Each group has 8 on-chip peripheral interrupt requests. The 96 on-chip peripheral interrupt request signals can be recorded as INTx.y (x=1,2,…,12; y=1,2,…,8). Each group outputs an interrupt request signal to the CPU, that is, the output INTx (x=1,2,…,…12) of PIE corresponds to the INT1~INT12 of the CPU interrupt input. Of the 96 possible PIE interrupt sources of the TMS320F28x series DSP, 45 are used by the TMS320F2812, and the rest are reserved for future DSP devices.
ADC, timer, SCI programming, etc. are all performed in interrupt mode, which can improve CPU utilization.
2.4 Reset Boot
Figure 2 shows the on-chip boot ROM space mapping of TMS320F2812. The boot program is configured at 0x3FFC00~0x3FFFBF in Figure 2. According to Figure 1, set VMAP=1, MP/MC=0, ENPIE=0, and the reset vector points to 0x3FFFC0 on the chip. The content of 0x3FFFC0 on the chip is 0x3FFC00, which points to the boot program in Figure 2. Configure GPIOF4 (SCITXDA)=1 in Table 2, then turn to 0x3F7FF6 in FLASH to start executing the program, and finally set the jump instruction at 0x3F7FF6 to point to the beginning of the user program to start running the user program. Since PIE interrupts are used in actual applications, in the user application, the PIE interrupt vector table should be initialized first, and then PIE should be enabled.
3 Programming Design
Programming is an important part of achieving normal system operation and fast calculation. Under the condition of reasonable system configuration, the key to fast calculation with fixed-point chip is to use integers instead of floating-point numbers for calculation and processing. When using C compiler, in order to generate the best code, the following principles should be followed:
(1) Convert division to multiplication and try to make the compiler generate MAC instructions to fully utilize the DSP's hardware multiplier resources for fast calculations. The MAC operands should be local variables that can be allocated to registers (or to an accumulator).
(2) Use static direct insertion functions whenever possible to save the additional overhead of function calls.
(3) For the upper limit of the FOR loop, using a constant or a variable with a constant attribute can generate a repeated instruction RPT.
3.1 ADC Programming
TMS20F2812 has a 12-bit ADC with two 8-to-1 multiplexers and dual sample/holds. The analog input range is 0-3V, the fastest conversion rate is 80ns, and a 10kSPS sampling rate is selected. It uses the EVA timer (0.1ms) automatic trigger method, can sample 4 channels at the same time, and use the interrupt method at the end of each conversion to record the sampling results (shift right 4 bits).
Conversion result = (212
-1) × (input analog signal - ADCLO) / 3
During ADC conversion, first initialize the DSP system, then set the PIE interrupt vector table, and then initialize the ADC module. Next, load the entry address of the ADC interrupt into the interrupt vector table and turn on the interrupt. Then start the 0.1ms timer and wait for the ADC interrupt. Finally, read the ADC conversion result in the ADC interrupt and start the next interrupt with software.
3.2 FIR filter programming
The target signal is very sensitive to some low-frequency interference, which will directly affect the validity of the positioning results and data. In order not to affect the calculation of the time-delay data after filtering, a linear phase FIR filter can be used. The filter coefficient h(i) is generated by MATLAB, and then solidified into the program after being shaped. The purpose of doing this (rather than calculating the filter coefficient separately) is to achieve fast filtering without increasing the positioning calculation time of the entire measurement system too much.
3.3 Transplantation of positioning algorithm
Since the positioning algorithm uses the adaptive delay estimation method, the amount of calculation is very large, and the performance requirements of the DSP chip are relatively high. TMS320F2812 has a 32-bit hardware multiplier and accumulator, and its RPT instruction is very suitable for loop calculations. The processing capacity can reach 150MIPS, so it has high performance. However, it is a fixed-point processing chip, and fixed-point algorithms are needed to solve the problem of large processing volume. Therefore, 16-bit integer variables (Q=12: determined by ADC conversion accuracy) should be used for the initial data and weight vector, and 32-bit integer variables (Q=20: try to meet the calculation accuracy without overflowing the result) should be used for the intermediate results generated in the loop calculation; as for the calculation of trigonometric functions, the table lookup method can be used and the table in Figure 2 can be used for fast calculation.
The C compiler has a floating-point library, so the results of floating-point and fixed-point arithmetic can be compared. For 4 channels of 1024-point data processing, it takes about 3.6 seconds to implement with floating-point arithmetic, while it only takes 1.3 seconds with fixed-point arithmetic.
In addition, the algorithm can be optimized. The first is to configure the frequently used intermediate variables to the memory with a waiting cycle of 0; the second is to use FLASH acceleration technology (enable the ENPIPE bit of the FOPT register to implement the FLASH pipeline mode of the pre-pointing mechanism), which can achieve a processing capacity of 100 to 120MIPS, which is much higher than its own 36ns reading capacity. It should be noted that due to the protection mechanism of TMS320F2812, the program that accesses the FLASH register must be moved to L0 and L1 for execution. Despite this, transplanting this algorithm with a relatively high time requirement to memory H0 can achieve a processing speed of up to 150MIPS, and the function memcpy() can be used to complete the program migration.
4 Conclusion
When the amount of calculation is large, floating-point DSP chips are usually selected. In fact, in order to make full use of the on-chip resources of fixed-point DSP chips, the method introduced in this article can also be used to select fixed-point chips to achieve higher calculation speeds, which can save hardware design costs and cycles, and reduce power consumption.
Previous article:Design of video processing system based on FPGA+DSP architecture
Next article:Parallel Processing Methods of DSP
 Algorithm Design (Jon Kleinberg Éva Tardos)
Algorithm Design (Jon Kleinberg Éva Tardos)




- Huawei's Strategic Department Director Gai Gang: The cumulative installed base of open source Euler operating system exceeds 10 million sets
- Analysis of the application of several common contact parts in high-voltage connectors of new energy vehicles
- Wiring harness durability test and contact voltage drop test method
- Sn-doped CuO nanostructure-based ethanol gas sensor for real-time drunk driving detection in vehicles
- Design considerations for automotive battery wiring harness
- Do you know all the various motors commonly used in automotive electronics?
- What are the functions of the Internet of Vehicles? What are the uses and benefits of the Internet of Vehicles?
- Power Inverter - A critical safety system for electric vehicles
- Analysis of the information security mechanism of AUTOSAR, the automotive embedded software framework
 Professor at Beihang University, dedicated to promoting microcontrollers and embedded systems for over 20 years.
Professor at Beihang University, dedicated to promoting microcontrollers and embedded systems for over 20 years.






- Innolux's intelligent steer-by-wire solution makes cars smarter and safer
- 8051 MCU - Parity Check
- How to efficiently balance the sensitivity of tactile sensing interfaces
- What should I do if the servo motor shakes? What causes the servo motor to shake quickly?
- 【Brushless Motor】Analysis of three-phase BLDC motor and sharing of two popular development boards
- Midea Industrial Technology's subsidiaries Clou Electronics and Hekang New Energy jointly appeared at the Munich Battery Energy Storage Exhibition and Solar Energy Exhibition
- Guoxin Sichen | Application of ferroelectric memory PB85RS2MC in power battery management, with a capacity of 2M
- Analysis of common faults of frequency converter
- In a head-on competition with Qualcomm, what kind of cockpit products has Intel come up with?
- Dalian Rongke's all-vanadium liquid flow battery energy storage equipment industrialization project has entered the sprint stage before production
- Allegro MicroSystems Introduces Advanced Magnetic and Inductive Position Sensing Solutions at Electronica 2024
- Car key in the left hand, liveness detection radar in the right hand, UWB is imperative for cars!
- After a decade of rapid development, domestic CIS has entered the market
- Aegis Dagger Battery + Thor EM-i Super Hybrid, Geely New Energy has thrown out two "king bombs"
- A brief discussion on functional safety - fault, error, and failure
- In the smart car 2.0 cycle, these core industry chains are facing major opportunities!
- The United States and Japan are developing new batteries. CATL faces challenges? How should China's new energy battery industry respond?
- Murata launches high-precision 6-axis inertial sensor for automobiles
- Ford patents pre-charge alarm to help save costs and respond to emergencies
- New real-time microcontroller system from Texas Instruments enables smarter processing in automotive and industrial applications
- [TI millimeter wave radar evaluation]_1_AWR1243BOOST unboxing
- Latest evaluation activity: i.MX series cross-border processor EasyARM-RT1052
- Mobile station development board STM32F767 Nucleo-144 is recommended!
- Component package disappeared after updating to PCB
- FPGA configuration peripheral circuit design conflicts and solutions
- The avr-iot discount purchase event that PIC held some time ago! Is it true that China cannot connect to Google's cloud service?
- Isn't this scope a prohibited item?
- Why does the power supply protect itself?
- Wireless Communication Principles Hotspot Technology
- FPGA board ARM board SOC board part-time






 京公网安备 11010802033920号
京公网安备 11010802033920号