

Break the bottleneck! Practical methods to comprehensively improve MySQL performance
Link: https://bbs.huaweicloud.com/blogs/365741



MySQL Optimization
Tuning ideas:
• 0. Hardware optimization
• 1. Disk io optimization
• 2. Optimization of operating system
• 3. Vertical disassembly and horizontal disassembly
• 4. Optimization of my.cnf parameters
• 5.MySQL query optimization
• 6. MySQL storage engine
Hardware Optimization
CPU: 64-bit, high frequency, high cache, high parallel processing capability
Memory: Large memory, high main frequency, try not to use SWAP
Hard disk: 15,000 rpm or higher is recommended, using RAID10, RAID5 disk array or SSD solid state disk
Network: The server comes with a Gigabit network card, and a 10G network card is recommended, using network card bond technology. The MySQL server should be in the same LAN as the web server that uses it, and unnecessary overhead such as firewall policies should be avoided as much as possible.
Note: NIC bond is achieved by binding multiple NICs into one logical NIC to achieve local NIC redundancy, bandwidth expansion and load balancing.
Disk io planning, io related technologies
1. RAID technology: RAID10 or RAID5
2. It is recommended to use 15,000 rpm or higher. If conditions permit, you can use SSD solid state disk
3. Swap partition: It is best to use raid0 or SSD
4. Disk partition: put the database directory into a disk or partition. Separate the hard disk or partition where the data is stored from the hard disk where the system is located.
5. Since binlog logs record operations frequently and the overhead is very high, binlog logs need to be placed on a separate hard disk partition.
Operating system optimization--kernel, number of TCP connections
The maximum number of TCP connections and the maximum limit of system open files
1. Set a limit on the number of TCP connections
1) Modify the kernel's restrictions on TCP connections:
The default local port number range set when the kernel is compiled may be too small, so this local port range limit needs to be modified.
The first step is to modify the /etc/sysctl.conf file and add the following lines to it:
# net.ipv4.ip_local_port_range = 1024 65000
This indicates that the system sets the local port range limit to between 1024 and 65000. Please note that the minimum value of the local port range must be greater than or equal to 1024; and the maximum value of the port range should be less than or equal to 65535. Save this file after modification.
The second step is to execute the sysctl command to make the changes take effect:
# sysctl -p
2) Maximum concurrent connections allowed in Linux:
View the number of concurrent connections to the current server:
Check how many connections are used:
# cat /proc/sys/net/ipv4/netfilter/ip_conntrack_count
The new version CentOS7 uses this:
# cat /proc/sys/net/netfilter/nf_conntrack_count
Check the total number:
# cat /proc/sys/net/ipv4/ip_conntrack_max
The new version CentOS7 uses this:
# cat /proc/sys/net/netfilter/nf_conntrack_max
Note: Make sure the module nf_conntrack is loaded, execute modprobe nf_conntrack
Temporarily increase the number of concurrent connections:
echo 524288 > /proc/sys/net/ipv4/ip_conntrack_max
The new version centos7 uses this:
echo 524288 > /proc/sys/net/netfilter/nf_conntrack_max
Permanently set the number of concurrent connections to increase:
Add net.ipv4.ip_conntract_max = 102400 to /etc/sysctl.conf
The new version centos7 uses this:
vi /etc/sysctl.conf and add: net.netfilter.nf_conntrack_max = 102400
Execute systcl -p to make the changes take effect:
# sysctl -p
3) In the concurrent process of Linux, the number of time_wait is too large, causing the connection to hang and wait. The following configuration needs to be added to the server:
Edit the file vi /etc/sysctl.conf and add the following content:
net.ipv4.tcp_syncookies = 1
net.ipv4.tcp_tw_reuse = 1
net.ipv4.tcp_tw_recycle = 1
net.ipv4.tcp_fin_timeout = 30
Then execute /sbin/sysctl -p to make the parameters take effect.
net.ipv4.tcp_syncookies = 1 means turning on SYN Cookies. When the SYN wait queue overflows, cookies are enabled to handle it, which can prevent a small amount of SYN attacks. The default value is 0, which means turning it off;
net.ipv4.tcp_tw_reuse = 1 means enabling reuse. Allowing TIME-WAIT sockets to be reused for new TCP connections. The default value is 0, which means closed.
net.ipv4.tcp_tw_recycle = 1 means enabling fast recycling of TIME-WAIT sockets in TCP connections. The default value is 0, which means closed.
net.ipv4.tcp_fin_timeout modifies the default TIMEOUT time
2. The maximum limit of system open files:
User Level:
(1) View the maximum open file limit for Linux system users
# ulimit -n
(2) Modify the open file limit
# vi /etc/security/limits.conf
mysql soft nofile 102400
mysql hard nofile 102400
mysql soft nproc 102400
mysql hard nproc 102400
mysql specifies the user whose open file limit is to be modified. The "*" sign can be used to modify the limit for all users. soft or hard specifies whether to modify the soft limit or the hard limit. 102400 specifies the new limit value to be modified, that is, the maximum number of open files (note that the soft limit must be less than or equal to the hard limit).
(3) Modify /etc/pam.d/login
# vi /etc/pam.d/login
session required /usr/lib64/security/pam_limits.so
This tells Linux that after the user completes the system login, the pam_limits.so module should be called to set the system's maximum limit on the number of various resources that the user can use (including the maximum number of files the user can open), and the pam_limits.so module will read the configuration from the /etc/security/limits.conf file to set these limit values.
Linux system level:
Check the Linux system's hard limit on the number of simultaneously open files
# sysctl -a | grep file-max
fs.file-max = 65535
This indicates that this Linux system allows a maximum of 65535 files to be opened simultaneously (including the total number of files opened by all users), which is a Linux system-level hard limit. All user-level open file limits will not exceed this value. Usually, this system-level hard limit is the optimal maximum number of files opened simultaneously calculated by the Linux system based on the system hardware resource status when it is started.
(1) Modify the file-max limit
# vi /etc/sysctl.conf
fs.file-max = 1000000
Execute sysctl -p to take effect
# sysctl -p
Disable unnecessary startup services
File system tuning,
Give the database a separate file system. It is recommended to use XFS, which is generally more efficient and reliable.
Consider enabling the noatime option when mounting the partition. #noatime#Do not record access times.
[root@cong11 ~]# vim /etc/fstab #Just add the noatime option to the mount item.
UUID=46cb104c-e4dc-4f84-8afc-552f21279c65 /data xfs defaults, noatime 0 0
To make the settings take effect immediately, run:
[root@cong11 ~]# mount -o remount /data/
[root@cong11 ~]# mount
. . .
/dev/sdb1 on /data type xfs (rw,noatime)
In this way, the system will no longer modify the atime attribute when reading files under this partition.
Minimization principle:
1) Minimize the installation system
2) Enable the principle of minimizing program services
3) Login minimization principle
4) Minimize permissions
Vertical disassembly, horizontal disassembly
1. Vertical disassembly: dedicated for special machine
For example: Now one server in the company is responsible for multiple roles such as web, ftp, database, etc.
After vertical disassembly: Database servers are dedicated to their own machines, avoiding performance degradation and instability that may be caused by additional services.
2. Horizontal disassembly:
Master-slave synchronization, load balancing, and high-availability clusters. When a single MySQL database cannot meet the increasing demand, you can consider adding multiple servers at the database logical level to achieve stable and efficient results.
Optimizing my.cnf parameters
General principles of optimization:
If you give MySQL too few resources, it will not be able to perform well; if you give MySQL too many resources, it may drag down the entire OS.
40% resources for OS, 60%-70% for MySQL (memory and CPU)
Cache the query
Most LAMP applications rely heavily on database queries. The general process of a query is as follows:
PHP sends a query request -> the database receives the instruction and analyzes the query statement -> determines how to query -> loads information from disk -> returns the result
If you query repeatedly, you will execute these repeatedly. MySQL has a feature called query cache, which can save the results of the query in a memory buffer. In the future, for the same SELECT statement, the results will be read directly from the buffer. This will greatly improve performance. However, the problem is that query cache is disabled by default.
Note: If a SQL query starts with select, the MySQL server will try to use the query cache for it. If two SQL statements differ by even one character (for example, different case or one extra space, etc.), the two SQL statements will use different caches.
Enable query caching:
[root@cong11 ~]# vi /etc/my.cnf add:
[mysqld] #Add this field
query_cache_size = 256M #Set the cache to 256M
query_cache_type=1 #1 is to enable MySQL query cache, 0 is not to cache
Note: Usually set to 32-512Mb. After setting, it is best to track for a period of time to see if it works well.
[root@cong11 ~]# systemctl restart mysqld
View: Query Cache
mysql> show status like 'qcache%';

Parameter Description:
1. Qcache_free_blocks: The number of adjacent memory blocks in the cache. A large number may indicate fragmentation.
If the number is large, you can execute:
mysql> flush query cache;
#Sort the fragments in the cache to get a free block.
2. Qcache_free_memory: The size of free memory in the cache. Through this parameter, we can more accurately observe whether the Query Cache memory size in the current system is sufficient and whether it needs to be increased or decreased.
3. Qcache_hits: Indicates how many times the query hits the cache. It increases each time a query hits the cache. The larger the number, the better the cache effect.
4. Qcache_inserts indicates the number of misses and insertions, which means that the new SQL request is not found in the cache and has to be processed. After the query is processed, the result is inserted into the query cache. The more such situations occur, the less the query cache is applied, and the less effective it is. Of course, when the system is just started, the query cache is empty, which is normal.
5. Qcache_lowmem_prunes: The number of cache deletions due to insufficient memory. The number of times the cache ran out of memory and had to be cleaned up to make room for more queries. The returned number is the longest; if the returned number is growing, it means that the fragmentation may be very serious or the cache memory is very low.
If Qcache_free_blocks is large, it means that the fragmentation is serious. If free_memory is small, it means that the cache is not enough.
6. Qcache_not_cached: The number of queries that are not suitable for caching, usually because these queries are not SELECT statements or use functions such as now().
7. Qcache_queries_in_cache: The number of queries (and responses) currently in the cache.
8. Qcache_total_blocks: The number of blocks in the cache.
Using MySQL query cache
mysql> create database aa;
mysql> use aa;
mysql> create table test3 (id int, name varchar(255));
mysql> insert into test3 values (1,'aaaa'), (2,'aaaa');
mysql> select * from test3;

mysql> show status like "qcache%"; #No hits

Query again:
mysql> select * from test3;
mysql> select * from test3;
mysql> show status like "qcache%"; #You can see that it is cached twice

Enforce limits on MySQL resource settings
You can enforce some limits in mysqld to ensure that system load does not lead to resource exhaustion.
[root@cong11 ~]# vi /etc/my.cnf
[mysqld]
max_connections=500
wait_timeout=10
max_connect_errors = 100
parameter:
max_connections: The maximum number of connections of MySQL. If the server has a large number of concurrent connection requests, it is recommended to increase this value to increase the number of parallel connections. Of course, this is based on the server's ability to support it. Because if the number of connections is large, MySQL will provide a connection buffer for each connection, which will consume more memory. Therefore, you should adjust this value appropriately and not blindly increase the value.
You can execute mysql> show variables like 'max_connections'; to view the maximum number of connections set for MySQL.
Note: If the value is too small, ERROR 1040: Too many connections will often appear.
wait_timeout: refers to the number of seconds (idle time) that MySQL waits before closing a non-interactive connection.
You can execute mysql> show variables like 'wait_timeout'; to view the value of wait_timeout.
max_connect_errors: is a security-related counter value in MySQL. It is responsible for blocking clients that have too many failed attempts to connect to prevent brute force password cracking. When the specified number of attempts is exceeded, the MYSQL server will prohibit the connection request from the host. The value of max_connect_errors has little to do with performance.
You can execute mysql> show variables like 'max_connect_errors'; to view the setting value of this parameter.
If a host has problems connecting to the server and gives up after retrying many times, the host will be locked out until you execute: mysql> FLUSH HOSTS;
test:
[root@cong11 ~]# vi /etc/my.cnf #Add the following content to the configuration file
[mysqld]
max_connections=500
wait_timeout=10
max_connect_errors = 100
verify:
mysql> show status like 'max_used_connections'; //Currently there is 1 connection

Open a MySQL connection with another client and execute a query. You can see that there are two:
mysql> show status like 'max_used_connections';

Table Cache:
Each table in the database is stored in a file. To read the contents of a file, you must first open the file and then read it. To speed up the process of reading data from the file, mysqld caches these open files. The maximum number of caches is specified by table_cache in /etc/my.cnf.
You can execute mysql> show variables like 'table_open_cache'; to view the setting value of this parameter.
[root@cong11 ~]# vim /etc/my.cnf #Add the following content to the table
[mysqld]
table_open_cache=512 #Cache up to 512 tables
[root@cong11 ~]# systemctl restart mysqld
mysql> show global status like 'open%_tables';

Open_tables indicates the number of open tables, and Opened_tables indicates the number of opened tables. If the number of Opened_tables is too large, it means that the table_open_cache value in the configuration may be too small.
The default value of table_cache ranges from 256 to 512 on machines with less than 2G of memory.
For a machine with 1G of memory, the recommended value is 128-256.
Note: Usually when setting the table_open_cache parameter, check the value of open_Tables during peak business hours. If the value of open_Tables is equal to the value of table_open_cache, and the value of opened_tables is increasing, then you need to increase the value of table_open_cache.
Keyword (index) buffer
key_buffer_size specifies the size of the index buffer, which determines the speed of index processing, especially the speed of index reading.
Execute mysql> show variables like 'key_buffer_size'; to view the setting value of the parameter.
[root@cong11 ~]# vim /etc/my.cnf //Add the following content to the table
[mysqld]
key_buffer_size=512M #Keyword buffer size
-
-
-
[root@cong11 ~]# systemctl restart mysqld
-
Check:
-
mysql> show status like '%key_read%';
-
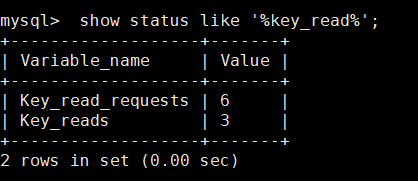

Key_reads represents the number of requests that hit the disk, Key_read_requests is the total number, and the number of read requests that hit the disk divided by the total number of read requests is the miss ratio.
Summarize:
MySQL has over 100 adjustable settings. It's almost impossible to remember so many, but fortunately you only need to remember a few of them to basically meet your needs. We can also use the "show status" command to check whether MySQL is running as we expect.
Query Optimization
1. Enable MySQL slow query log
The slow query log is used to record query statements that take longer than a specified time to execute. Through the slow query log, you can find out which query statements have low execution efficiency so that you can optimize them.
View the definition of the slow query log:
mysql> show variables like '%slow_query_log%';
mysql> show global variables like '%long%';


in:
slow_query_log: off closed state on open state
slow_query_log_file: slow query log storage location
long_query_time: Option to set a time value in seconds, accurate to microseconds. If the query time exceeds this time value (the default is 10 seconds), the query statement will be recorded in the slow query log. If it is set to 0, it means that all queries will be recorded.
Enable the slow query log function:
Method 1: Enable the slow query log through the configuration file vi /etc/my.cnf and add the following configuration items to the configuration file my.cnf:
slow_query_log = 1 # Enable slow query log
slow-query-log-file=/data/mysql/log/slow.log #This path has writable permissions for mysql users
long_query_time=1 #Record queries that take longer than 1 second
log-queries-not-using-indexes =1 # Queries that do not use indexes
Note: If you do not specify a storage path, the slow query log is stored in the data file of the MySQL database by default. If you do not specify a file name, the default file name is hostname-slow.log
Restart the mysqld service to make the modified parameters take effect. Execute:
systemctl restart mysqld
test:
mysql> create table test (id int,name varchar(20));
mysql> insert into test values (1, 'man');
mysql> select * from test;
# cat /data/mysql/log/slow.log

Method 2: Define directly by logging in to the MySQL server as follows:
mysql>set global slow_query_log=1; #Open slow query log
mysql>set global long_query_time=0.001; #Change time
2. Use explain execution plan
You can use explain before the select statement to obtain the execution plan of the query statement instead of actually executing the statement.

3. Use limit 1 when only one row of data is needed
4. Take only the columns you need and avoid using select *
5. Add index (primary key index/unique index/normal index/composite index)
6. No column operations: select id from tablename where age + 1 = 10. Any operation on the column will result in a table scan. When querying, try to move the operation to the right of the equal sign.
7. Keep SQL statements as simple as possible: one SQL statement can only be run on one CPU; split large statements into small ones to reduce lock time; one large SQL statement can block the entire database.
8. or is rewritten as in
9. Avoid %xxx queries
10. Try to avoid using != or <> operators in the where clause, otherwise the engine will abandon the use of the index and perform a full table scan.
Link: https://www.cnblogs.com/zxbin/p/17570316.html
Autumn
The recruitment has already begun. If you are not well prepared,
Autumn
It's hard to find a good job.
Here is a big employment gift package for everyone. You can prepare for the spring recruitment and find a good job!







 京公网安备 11010802033920号
京公网安备 11010802033920号