

The most comprehensive and detailed explanation of Linux inter-process communication methods on the entire network is here, you can't miss it!
The most complete and detailed explanation of inter-process communication methods on the entire network is here! Don't miss it if you want to learn! It uses a combination of pictures and text + code examples to take you to an in-depth understanding of each communication method, ensuring that you will understand it at a glance!
introduction
Everyone should know that there are many processes running in the operating system. Simply put, a process is a running instance of a program. For example, if you open a browser, a music player, and a chat software, these three programs are three independent processes. But the question is, if processes want to "talk" to each other and exchange information with each other, what should they do? This is the problem that inter-process communication (IPC) is to solve.
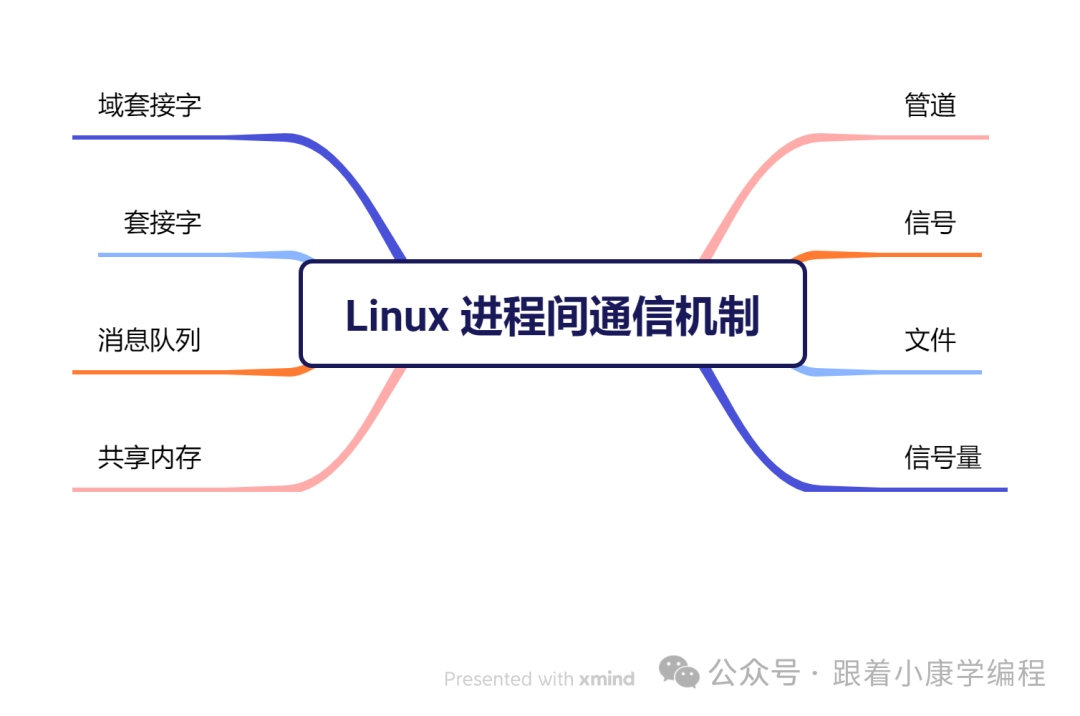
All inter-process communication methods in Linux:
1. Pipe
Pipes are a mechanism used in Linux for inter-process communication. They are of two types: anonymous pipes and named pipes .
Anonymous pipes:
Concept : An anonymous pipe is a communication mechanism for one-way data transmission between related processes (such as parent-child processes). It exists in memory and is usually used for temporary communication. If two-way communication is required, two pipes are generally required.
Simple diagram:
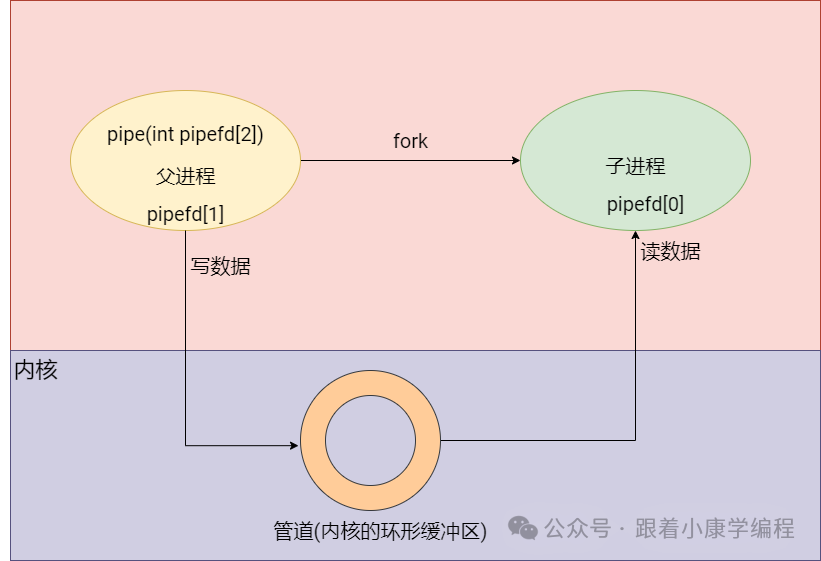
Usage scenario : Suitable for simple data transmission between related processes, such as parent-child processes.
Simple example:
#include <unistd.h>
int main() {
int pipefd[2];
pipe(pipefd); // 创建匿名管道
if (fork() == 0) { // 子进程
close(pipefd[1]); // 关闭写端
//读取数据
read(pipefd[0],buf,5);
// ...
} else { // 父进程
close(pipefd[0]); // 关闭读端
// 写入数据
write(pipefd[1],"hello",5);
// ...
}
}
Famous pipelines:
Concept: A named pipe (FIFO, First-In-First-Out) is a special type of file used to implement communication between unrelated processes. Unlike anonymous pipes, a named pipe has an actual path name in the file system. This allows any process with appropriate permissions to open and use it, not just limited to related processes.
Simple diagram:
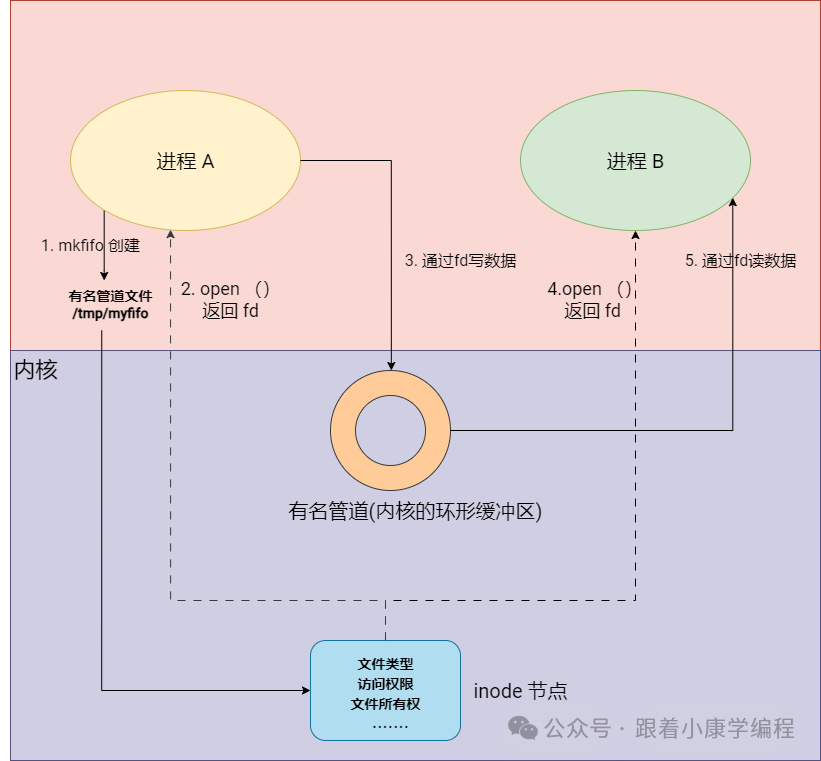
Brief description :
A named pipe is a special file in Linux that allows different processes to communicate with each other by reading and writing this file.
Usage scenario : used for communication between any two processes on the local machine, especially when these processes are not related by blood.
Simple example:
// server.c
int main() {
const char *fifoPath = "/tmp/my_fifo";
mkfifo(fifoPath, 0666); // 创建有名管道
char buf[1024];
int fd;
// 永久循环,持续监听有名管道
while (1) {
fd = open(fifoPath, O_RDONLY); // 打开管道进行读取
read(fd, buf, sizeof(buf));
// 打印接收到的消息
printf("Received: %s\n", buf);
close(fd);
}
return 0;
}
// client.c
int main() {
const char *fifoPath = "/tmp/my_fifo";
char buf[1024];
int fd;
printf("Enter message: "); // 获取要发送的消息
fgets(buf, sizeof(buf), stdin);
fd = open(fifoPath, O_WRONLY); // 打开管道进行写入
write(fd, buf, strlen(buf) + 1);
close(fd);
return 0
}
2. Signals
Concept : In Linux, a signal is a mechanism for inter-process communication (IPC) that allows the operating system or one process to send simple messages to another process. Signals are mainly used to deliver notifications about system events, such as interrupt requests, program exceptions, or other important events. Each signal represents a specific type of event, and the process can perform corresponding actions based on the received signal.
Signals are asynchronous, meaning they can be sent to a process at any point in time, usually independent of the normal control flow of the process. The use of signals provides a way for a process to handle external events and errors.
You can use the command
kill -l
to check which signals are supported by the Linux system?
~$ kill -l
1) SIGHUP 2) SIGINT 3) SIGQUIT 4) SIGILL 5) SIGTRAP
6) SIGABRT 7) SIGBUS 8) SIGFPE 9) SIGKILL 10) SIGUSR1
11) SIGSEGV 12) SIGUSR2 13) SIGPIPE 14) SIGALRM 15) SIGTERM
...
Use scenarios :
-
Exception handling : When a program encounters a runtime error, such as division by zero, illegal memory access, etc., the operating system will send an appropriate signal to the process, such as SIGFPE (floating point exception) or SIGSEGV (segment fault). By default, the program will terminate.
-
External interruption : The user can interrupt a process running in a terminal by special keyboard input (most commonly Ctrl+C). This generates a SIGINT signal, which usually causes the program to terminate.
-
Process control : For example, use the kill command to send a signal to terminate or pause a process.
-
Timers and timeouts : A program can set a timer, and when the timer expires, it will receive a SIGALRM signal. This is often used to limit the execution time of certain operations to ensure that they do not take too much time.
-
Child process status change : When a child process ends or stops, its parent process will receive a SIGCHLD signal. This allows the parent process to monitor the status changes of its child process (from running to normal exit).
Simple example:
void signal_handler(int signal_num) {
printf("Received signal: %d\n", signal_num);
}
int main() {
signal(SIGINT, signal_handler); // 注册信号处理函数
// 无限循环,等待信号
while (1) {
sleep(1); // 暂停一秒
}
return 0;
}
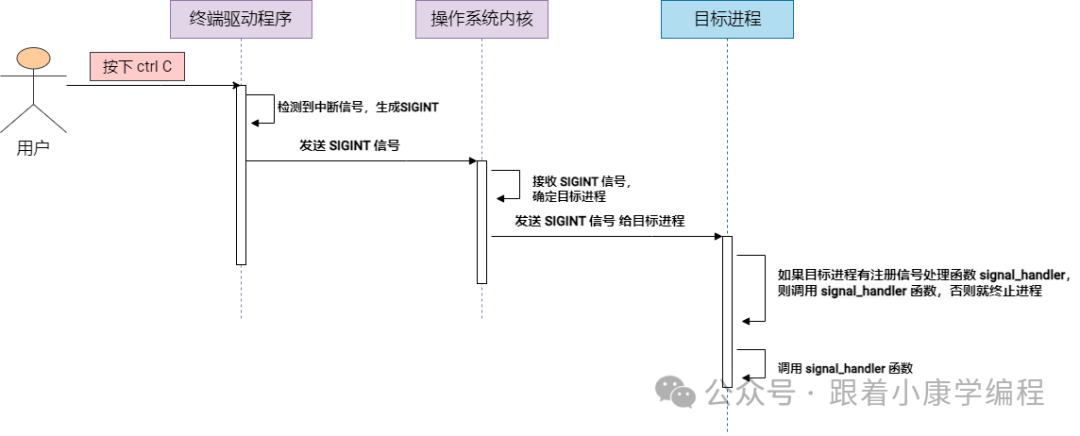
In this example, the program sets a signal handler to handle the SIGINT signal (usually generated by Ctrl+C). When the signal is received, the signal_handler function will be called.
The following is a simple graphic illustration of the execution process of the above code for your convenience :
3. Files
concept :
Files are a basic persistent storage mechanism in Linux systems and can be used for inter-process communication . Multiple processes can share information by reading and writing to the same file.
Simple diagram:
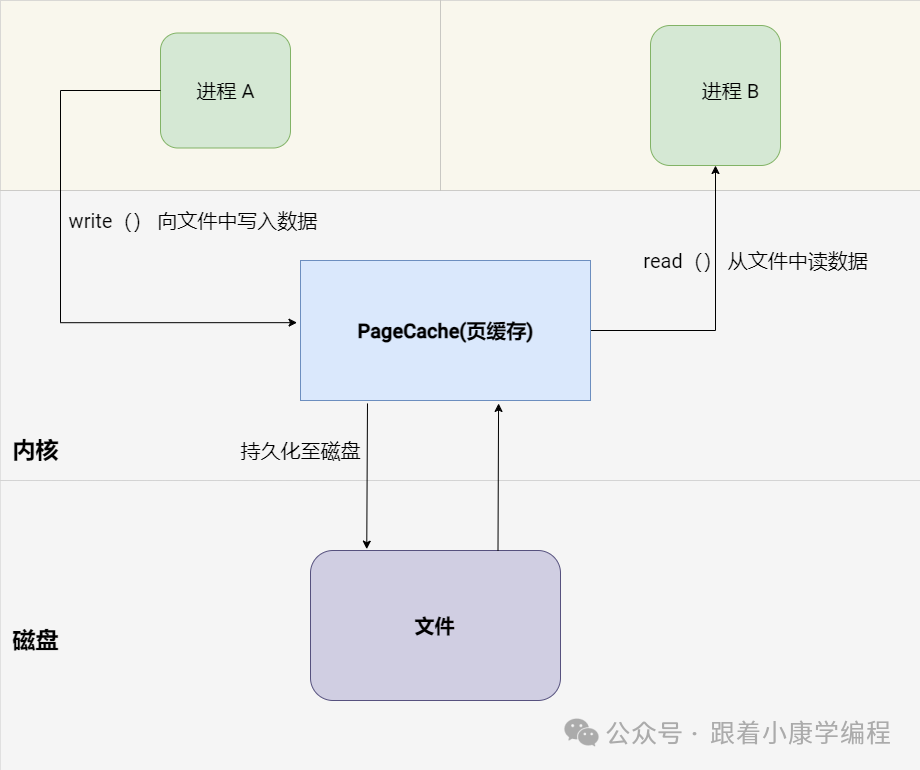
Use scenarios:
-
Data Exchange:
Processes can exchange data by reading and writing to the same file. For example, one process writes result data and another process reads the data for further processing.
-
Persistent storage:
Files are used to save data that needs to be retained after the application is restarted, such as user data, application status, etc.
Simple example:
// 写进程: 向文件中写入数据
int main() {
const char *file = "/tmp/ipc_file";
int fd = open(file, O_RDWR | O_CREAT, 0666);
write(fd, "Hello from Process A", 20); // 向文件写入数据
close(fd); // 关闭文件
return 0;
}
// 读进程: 从文件中读取数据
int main() {
const char *file = "/tmp/ipc_file";
int fd = open(file, O_RDWR | O_CREAT, 0666);
char buf[50];
read(fd, buf, 20); // 从文件中读取数据
close(fd); // 关闭文件
return 0;
}
Note: If there are multiple writing processes operating the same file at the same time, data race and consistency issues will occur. To solve this problem, you can use file locks or other synchronization mechanisms to coordinate access to files to ensure data integrity and consistency.
Linux file locks
What is a file lock?
In layman's terms, file lock is a mechanism used in Linux system to control multiple processes from accessing the same file at the same time. It acts like a lock on a door, ensuring that only one process can write to the file at the same time, thus avoiding confusion caused by multiple processes writing data at the same time.
What is file lock used for?
-
Prevent data overwriting : When one process is writing a file, the file lock can prevent other processes from writing at the same time, thus preventing the data from being overwritten.
-
Ensure the integrity of write operations :
Locking files ensures that only one process can write to them at a time, which helps maintain the integrity of the data being written.
Implement file lock:
In Linux, file locking can be implemented using the fcntl or flock system calls.
Sample Code
Use fcntl to implement file locks, thereby ensuring that multiple processes do not interfere with each other when operating the same file, maintaining data consistency and integrity. The following is a specific example:
int main() {
const char *file = "/tmp/ipc_file";
int fd = open(file, O_RDWR | O_CREAT, 0666);
// 设置文件锁
struct flock fl;
fl.l_type = F_WRLCK; // 设置写锁
fl.l_whence = SEEK_SET;
fl.l_start = 0;
fl.l_len = 0; // 锁定整个文件
if (fcntl(fd, F_SETLKW, &fl) == -1) {
perror("Error locking file");
return -1;
}
write(fd, "Hello from Process A", 20); // 执行写操作
// 释放锁
fl.l_type = F_UNLCK;
fcntl(fd, F_SETLK, &fl);
close(fd);
return 0;
}
4. Semaphores
Concept : A semaphore is a mechanism that provides synchronization between processes or between different threads of the same process. It is a counter that is used to control access to shared resources. When the counter value is greater than 0, it means that the resource is available; when the value is 0, it means that the resource is occupied. A process must reduce (wait) the semaphore before accessing a shared resource and must increase (post) the semaphore after accessing it.
There are two types of semaphores, one is POSIX semaphores and the other is System V semaphores. Since POSIX semaphores provide a simpler, easier to understand and use API, and are widely supported and optimized in modern operating systems, I will focus on POSIX semaphores here.
Simple diagram:
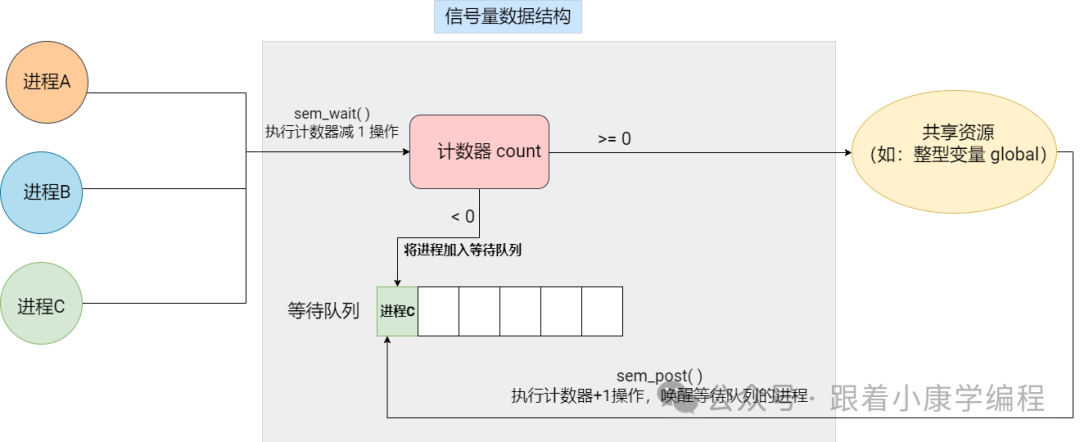
Classification:
Anonymous semaphore
concept:
Anonymous semaphores are in-memory semaphores that are not associated with any file system name. They are typically used to synchronize threads within a single process, or between processes that have a common ancestor.
Features:
-
Scope : limited to the process that created it or its child processes.
-
Lifecycle : The semaphore has the same lifecycle as the process that created it, and disappears when the process terminates.
Use scenarios :
-
Mutually exclusive access : In a multi-threaded program, ensure that only one thread can access a shared resource at the same time.
-
Synchronous operation : coordinate the execution order of multiple threads, one thread starts execution after another thread completes its task. For example, when there is no task in the task queue of the thread pool, the thread must wait, and when a thread adds a task to the queue, it needs to wake up other threads to consume the task.
Named semaphores
Concept: A named semaphore has a unique name in the file system, allowing different independent processes to access the same semaphore through this name to achieve inter-process synchronization.
Features:
-
Scope : can be used across different processes. They have a globally unique name in the file system, and any process that knows this name can access the same semaphore.
-
Lifecycle : The lifecycle can exceed the process that created them. Even if the process that created them has ended, as long as the name of the named semaphore exists in the file system, they continue to exist.
Use scenarios :
-
Inter-process mutual exclusion: Multiple independent processes share resources, such as files or memory-mapped areas, and need mutually exclusive access to avoid conflicts.
-
Synchronous operation : coordinate the execution order of multiple processes, so that one process starts executing after another process completes its task. For example, in the producer-consumer model, consumers can only consume data when the producer adds data to the queue and the queue is not empty, otherwise they can only wait.
Let's look at an example of process mutual exclusion:
The following is a simplified example of using named semaphores to implement mutually exclusive access to the same log file by two independent processes.
Write to process 1 (process1.c)
int main() {
FILE *logFile = fopen("logfile.txt", "a"); // 打开日志文件
// 打开或创建有名信号量
sem_t *sem = sem_open("/log_semaphore", O_CREAT, 0644, 1);
// 获取信号量
sem_wait(sem);
// 写入日志
fprintf(logFile, "Log message from Process 1\n");
fflush(logFile);
// 释放信号量
sem_post(sem);
// 关闭信号量和文件
sem_close(sem);
fclose(logFile);
return 0;
}
Write process 2 (process2.c)
int main() {
FILE *logFile = fopen("logfile.txt", "a"); // 打开日志文件
// 打开或创建有名信号量
sem_t *sem = sem_open("/log_semaphore", O_CREAT, 0644, 1);
// 获取信号量
sem_wait(sem);
// 写入日志
fprintf(logFile, "Log message from Process 2\n");
fflush(logFile);
// 释放信号量
sem_post(sem);
// 关闭信号量和文件
sem_close(sem);
fclose(logFile);
return 0;
}
The difference between anonymous semaphore and named semaphore API interfaces:
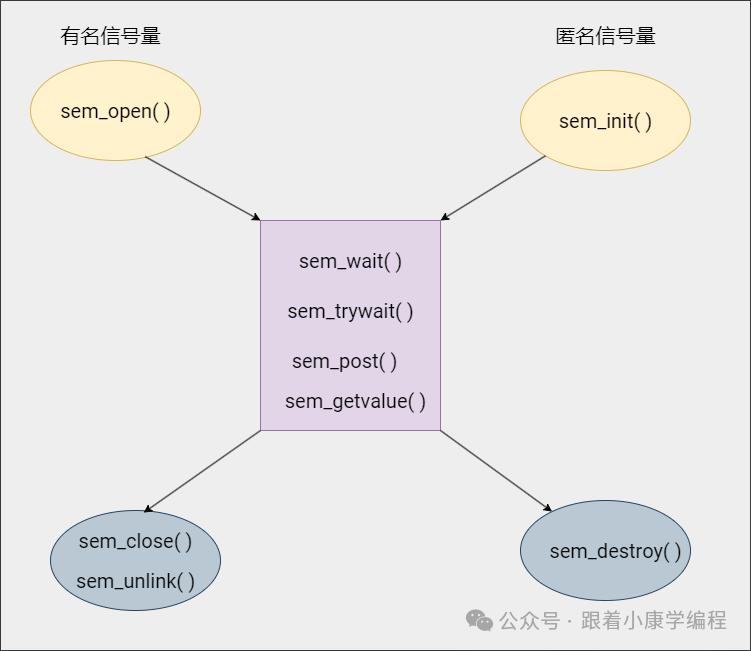
5. Shared Memory
Concept : In Linux, shared memory is a form of inter-process communication (IPC). When multiple processes need to access the same data, using shared memory is an efficient way. It allows two or more processes to access the same physical memory area, which makes data transmission unnecessary through kernel space, thereby improving communication efficiency.
Before explaining shared memory, we need to understand memory mapping technology?
Memory Mapping is a technology that maps file or device data to the process memory address space, allowing the process to directly read and write this part of memory, just like accessing ordinary memory. This technology can not only be used for file I/O operations to improve file access efficiency, but also is the basis for implementing shared memory.
In Linux systems, memory mapping can be achieved through the mmap system call. Mmap allows files to be mapped into the address space of a process, and can also be used to create anonymous mappings (i.e. shared memory areas that are not based on any files).
In Linux, shared memory can be divided into the following categories.
a. Anonymous shared memory
Working principle :
Anonymous shared memory is not directly associated with any specific file system file, and its content exists only in memory. This means that when all processes using it end, the data in the memory area disappears. This feature makes anonymous shared memory very suitable for scenarios that require temporary sharing of data but do not need to store the data persistently on disk.
Simple diagram:

Note : In Linux, anonymous shared memory is mainly designed for communication between related processes, such as between parent and child processes . This is because references to anonymous shared memory (for example, the memory address returned when created by mmap) will not automatically appear in other processes, but need to be passed to related processes through some form of inter-process communication (such as Unix domain sockets). However, it is slightly more complicated to implement it through Unix domain sockets, so we generally recommend anonymous shared memory for communication between related processes.
Create and use :
In Linux systems, anonymous shared memory is usually created through the mmap() function, and the MAP_ANONYMOUS flag must be specified when calling it. In addition, the PROT_READ and PROT_WRITE permissions must be set to ensure that the memory area is readable and writable. The MAP_SHARED flag can also be selected when creating it so that this memory can be shared among multiple processes.
The sample code snippet is as follows:
#include <sys/mman.h>
void* shared_memory = mmap(NULL, size, PROT_READ | PROT_WRITE, MAP_SHARED | MAP_ANONYMOU
Here, size is the size of the memory area you want to map. After the mmap() call is successful, a pointer to the shared memory area is returned.
Use scenarios :
Large amounts of data exchange : When two or more processes need to exchange large amounts of data, using shared memory is more efficient than traditional inter-process communication methods such as pipes or message queues.
When it comes to shared memory, we have to discuss the issue of shared memory synchronization?
When using shared memory, since multiple processes can directly and simultaneously access the same physical memory area, data contention and consistency issues may occur if not properly controlled.
Data race : When multiple processes try to modify the same data item in shared memory at the same time, the final result may depend on the specific order of the operations of each process, which may lead to unexpected results.
Consistency issues : Without a proper synchronization mechanism, one process may read shared memory while another process is writing data, resulting in incomplete or inconsistent data.
Solution strategy: Use semaphore
Semaphore is a common synchronization mechanism used to control concurrent access to shared resources. By increasing (releasing resources) or decreasing (occupying resources) the value of the semaphore, access to shared memory areas can be effectively controlled to prevent data races and ensure data consistency.
A simple example of using semaphores to solve the anonymous shared memory synchronization problem :
int main() {
// 创建有名信号量
sem_t *sem = sem_open("/mysemaphore", O_CREAT, 0666, 1);
// 创建匿名共享内存
int *counter = mmap(NULL, sizeof(int), PROT_READ | PROT_WRITE, MAP_SHARED | MAP_ANONYMOUS, -1, 0);
*counter = 0; // 初始化计数器
pid_t pid = fork();
if (pid == 0) {
// 子进程
for (int i = 0; i < 10; ++i) {
sem_wait(sem); // 等待信号量
(*counter)++; // 递增计数器
printf("Child process increments counter to %d\n", *counter);
sem_post(sem); // 释放信号量
sleep(1); // 模拟工作负载
}
exit(0);
} else {
// 父进程
for (int i = 0; i < 10; ++i) {
sem_wait(sem); // 等待信号量
printf("Parent process reads counter as %d\n", *counter);
sem_post(sem); // 释放信号量
sleep(1); // 模拟工作负载
}
// 等待子进程结束
wait(NULL);
sem_close(sem);
sem_unlink("/mysemaphore");
munmap(counter, sizeof(int)); // 释放共享内存
}
return 0;
}
b. File-based shared memory
Working principle:
File-based shared memory is implemented by mapping the actual file on the disk to the address space of one or more processes. Once the file is mapped to memory, the process can directly read and write the file content just like accessing ordinary memory, and the operating system is responsible for synchronizing memory modifications back to the disk file. This mechanism not only improves the efficiency of data access, but also realizes persistent storage of data.
Compared with anonymous shared memory, which is only suitable for related processes, file-based shared memory is particularly suitable for data sharing between non-related processes .
Simple diagram:
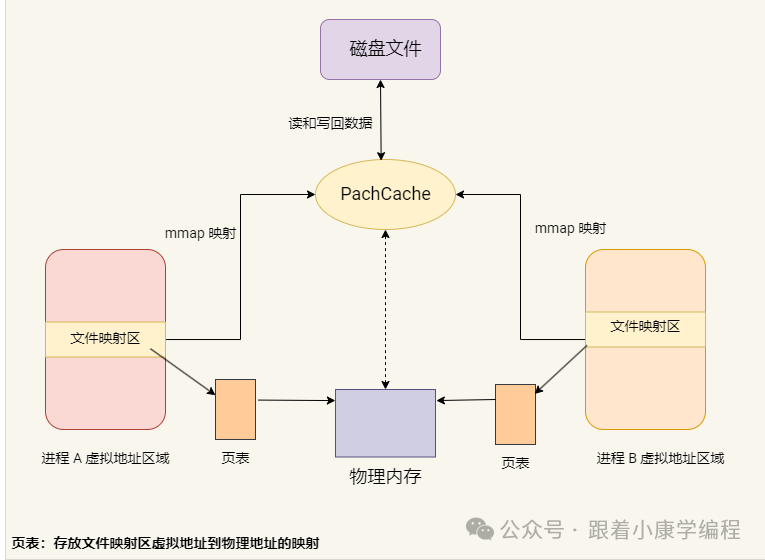
Create and use:
To create file-based shared memory, you first need to open (or create) a file, and then use mmap() to map the file into memory. Unlike anonymous shared memory, you need to provide a file descriptor instead of the MAP_ANONYMOUS flag.
The sample code snippet is as follows:
#include <sys/mman.h>
#include <fcntl.h>
size_t size = 4096; // 共享内存区域大小
int fd = open("shared_file", O_RDWR | O_CREAT, 0666);
ftruncate(fd, size); // 设置文件大小
void* shared_memory = mmap(NULL, size, PROT_READ | PROT_WRITE, MAP_SHARED, fd, 0);
Here, shared_file is the name of the file being mapped and size is the expected size of the file. The file size is adjusted to match the shared memory requirements via ftruncate(). mmap() returns a pointer to the shared memory area on success.
Use scenarios:
Large amounts of data exchange : File-based shared memory is also suitable for scenarios where multiple processes need to exchange large amounts of data. Unlike anonymous shared memory, this data can be persistently stored on disk.
When using file-based shared memory, it is also necessary to solve the synchronization problem of shared data among multiple processes to ensure data consistency and integrity.
Solution :
-
Semaphore : A semaphore can be understood as a counter that controls the number of processes that simultaneously access a shared resource (such as shared memory). If the semaphore count is greater than 0, it means that the resource is available, and the process can access the resource and reduce the count by 1; if the semaphore count is 0, it means that the resource is not available and the process must wait. When the resource is used up, the process increases the semaphore count to indicate that the resource is available again.
-
File lock : File lock allows a process to lock the file on which the shared memory is based, preventing other processes from accessing it at the same time. If a process wants to write to the shared memory, it can add an exclusive lock, so that other processes can neither read nor write; if it only needs to read, the process can add a shared lock, so that other processes can also add a shared lock to read the data, but cannot write. In Linux, the implementation of file locks mainly relies on two system calls: fcntl and flock. I have also mentioned the explanation of fcntl and flock in the previous article.
In simple terms :
-
Semaphores are used to ensure that only a limited number of processes can operate on the shared memory at the same time.
-
File locks are used to prevent other processes from interfering when a process reads or writes shared memory.
Let's look at an example of using named semaphores to solve file-based shared memory synchronization problems . This simple example demonstrates two processes: one process writes data to shared memory, and the other process reads data from shared memory. The two processes use the same named semaphore to synchronize access to the shared memory area.
Sample code:
First, make sure you have a file called shared_file and a semaphore called /mysemaphore.
Write process :
int main() {
const char* filename = "shared_file";
const size_t size = 4096;
// 打开共享文件
int fd = open(filename, O_RDWR | O_CREAT, 0666);
// 映射文件到内存
void* addr = mmap(NULL, size, PROT_READ | PROT_WRITE, MAP_SHARED, fd, 0);
// 打开有名信号量
sem_t *sem = sem_open("/mysemaphore", O_CREAT, 0666, 1);
// 等待信号量,写入数据
sem_wait(sem);
strcpy((char*)addr, "Hello from writer process!");
sem_post(sem);
// 清理
munmap(addr, size);
close(fd);
sem_close(sem);
return 0;
}
Reading process:
int main() {
const char* filename = "shared_file";
const size_t size = 4096;
// 打开共享文件
int fd = open(filename, O_RDONLY);
// 映射文件到内存
void* addr = mmap(NULL, size, PROT_READ, MAP_SHARED, fd, 0);
// 打开有名信号量
sem_t *sem = sem_open("/mysemaphore", O_CREAT, 0666, 1);
// 等待信号量,读取数据
sem_wait(sem);
printf("Read from shared memory: %s\n", (char*)addr);
sem_post(sem);
// 清理
munmap(addr, size);
close(fd);
sem_close(sem);
return 0;
}
Note : The initial value of the semaphore above is 1. In fact, the semaphore here acts as a mutex lock.
c. Posix shared memory
POSIX shared memory provides an efficient way to allow multiple processes to communicate through shared memory areas. Compared with file-based shared memory, POSIX shared memory does not need to directly map files on the disk, but instead creates named shared memory objects to achieve data sharing between processes. Although these objects are logically similar to files (because they can be created and opened through shm_open), they actually exist directly in memory, providing faster data access speed.
Posix shared memory interface :
shm_open() // 创建或打开一个共享内存对象
shm_unlink() // 删除一个共享内存对象的名称
ftruncate() // 调整共享内存对象的大小
mmap() // 将共享内存对象映射到调用进程的地址空间
munmap() // 解除共享内存对象的映射
The following is a simplified example of using POSIX shared memory to communicate between two unrelated processes. One process writes data and the other reads the data.
Example demonstration :
Writing process (writer.c)
#define SHM_NAME "/example_shm" // 共享内存名称
#define SHM_SIZE 4096 // 共享内存大小
#define SEM_NAME "/example_sem" // 信号量名称
int main() {
// 创建或打开共享内存对象
int shm_fd = shm_open(SHM_NAME, O_CREAT | O_RDWR, 0666);
ftruncate(shm_fd, SHM_SIZE);
// 映射共享内存到进程地址空间
void *ptr = mmap(0, SHM_SIZE, PROT_WRITE | PROT_READ, MAP_SHARED, shm_fd, 0);
// 创建或打开有名信号量,初始值为 1
sem_t *sem = sem_open(SEM_NAME, O_CREAT, 0666, 1);
// 等待信号量,开始写入数据
sem_wait(sem);
const char *message = "Hello from writer process!";
sprintf(ptr, "%s", message);
printf("Writer wrote to shared memory: %s\n", message);
sem_post(sem); // 释放信号量
// 清理资源
munmap(ptr, SHM_SIZE);
close(shm_fd);
sem_close(sem);
return 0;
}
Reading process (reader.c)
#define SHM_NAME "/example_shm" // 共享内存名称
#define SHM_SIZE 4096 // 共享内存大小
#define SEM_NAME "/example_sem" // 信号量名称
int main() {
// 打开已经存在的共享内存对象
int shm_fd = shm_open(SHM_NAME, O_RDONLY, 0666);
// 映射共享内存到进程地址空间
void *ptr = mmap(0, SHM_SIZE, PROT_READ, MAP_SHARED, shm_fd, 0);
// 打开有名信号量
sem_t *sem = sem_open(SEM_NAME, 0);
// 等待信号量,开始读取数据
sem_wait(sem);
printf("Reader read from shared memory: %s\n", (char*)ptr);
sem_post(sem); // 释放信号量
// 清理资源
munmap(ptr, SHM_SIZE);
close(shm_fd);
sem_close(sem);
return 0;
}
d. System V shared memory
System V shared memory is a traditional inter-process communication (IPC) mechanism that allows multiple processes to communicate through a shared memory area. Unlike POSIX shared memory, System V shared memory uses the IPC key value key_t to identify and manage shared memory segments instead of naming them. This mechanism provides a set of low-level APIs for controlling shared memory, allowing for more fine-grained operations such as permission control, querying and managing shared memory status, etc.
System V shared memory interface :
shmget() // 创建或获取共享内存段的标识符
shmat() // 将共享内存段附加到进程的地址空间
shmdt() // 分离共享内存段和进程的地址空间
shmctl() // 对共享内存段执行控制操作
Example demonstration :
The following is an example of using System V shared memory and System V semaphores to synchronize communication between two unrelated processes. One process writes to the shared memory and the other reads the shared memory, and the synchronization control is performed through semaphores.
Semaphore initialization (semaphore_init.c)
#define FILE_PATH "sharedfile" // ftok生成key所用的文件路径
int main() {
// 生成信号量键值
key_t sem_key = ftok(FILE_PATH, 'B');
// 创建信号量集,包含一个信号量
int sem_id = semget(sem_key, 1, 0666 | IPC_CREAT);
// 初始化信号量的值为 1
semctl(sem_id, 0, SETVAL, 1);
printf("Semaphore initialized.\n");
return 0;
}
Writing process (writer.c)
#define SHM_SIZE 1024 // 共享内存大小
#define FILE_PATH "sharedfile" // ftok生成key所用的文件路径
int main() {
// 生成共享内存和信号量的键值
key_t shm_key = ftok(FILE_PATH, 'A');
key_t sem_key = ftok(FILE_PATH, 'B');
// 创建共享内存段
int shm_id = shmget(shm_key, SHM_SIZE, 0666 | IPC_CREAT);
// 将共享内存段附加到进程的地址空间
char *shm_ptr = (char*) shmat(shm_id, NULL, 0);
// 创建信号量集,只有一个信号量
int sem_id = semget(sem_key, 1, 0666 | IPC_CREAT);
// 等待信号量
struct sembuf sem_op = {0, -1, 0}; // P 操作
semop(sem_id, &sem_op, 1);
// 向共享内存写入数据
strcpy(shm_ptr, "Hello from writer process!");
printf("Writer wrote to shared memory: %s\n", shm_ptr);
// 释放信号量
sem_op.sem_op = 1; // V 操作
semop(sem_id, &sem_op, 1);
// 分离共享内存段
shmdt(shm_ptr);
return 0;
}
Reading process (reader.c)
#define SHM_SIZE 1024 // 共享内存大小
#define FILE_PATH "sharedfile" // ftok生成key所用的文件路径
int main() {
// 生成共享内存和信号量的键值
key_t shm_key = ftok(FILE_PATH, 'A');
key_t sem_key = ftok(FILE_PATH, 'B');
// 获取共享内存段
int shm_id = shmget(shm_key, SHM_SIZE, 0666);
// 将共享内存段附加到进程的地址空间
char *shm_ptr = (char*) shmat(shm_id, NULL, 0);
// 获取信号量集
int sem_id = semget(sem_key, 1, 0666);
// 等待信号量
struct sembuf sem_op = {0, -1, 0}; // P 操作
semop(sem_id, &sem_op, 1);
// 读取共享内存中的数据
printf("Reader read from shared memory: %s\n", shm_ptr);
// 释放信号量
sem_op.sem_op = 1; // V 操作
semop(sem_id, &sem_op, 1);
// 分离共享内存段
shmdt(shm_ptr);
return 0;
}
To facilitate your study, I have summarized these types of shared memory :
| type | the difference | Applicable scenarios | How to use |
|---|
| Anonymous shared memory |
No file support is required, processes share data directly through memory pages, usually through
mmap()
memory mapping |
Shared memory needs to be created and destroyed quickly, and does not need to be persistent |
mmap()
,
sem_open()
|
|---|
| File-based shared memory | Using files as a medium, processes share memory through the file system, which is suitable for scenarios that require persistence | Shared data needs to be persistent or used across devices |
mmap()
,
open()
,
sem_open()
|
|---|
| POSIX shared memory | POSIX standard interface, more modern, supports more fine-grained control and permission management | On POSIX-compliant systems, suitable for modern applications, providing better concurrency control |
shm_open()
,
mmap()
|
|---|
| System V Shared Memory | Traditional System V interface, supports larger shared memory segments, but the interface is old | Old systems may need to be compatible with old versions of code, suitable for large-scale data sharing |
shmget()
,
shmat()
|
|---|
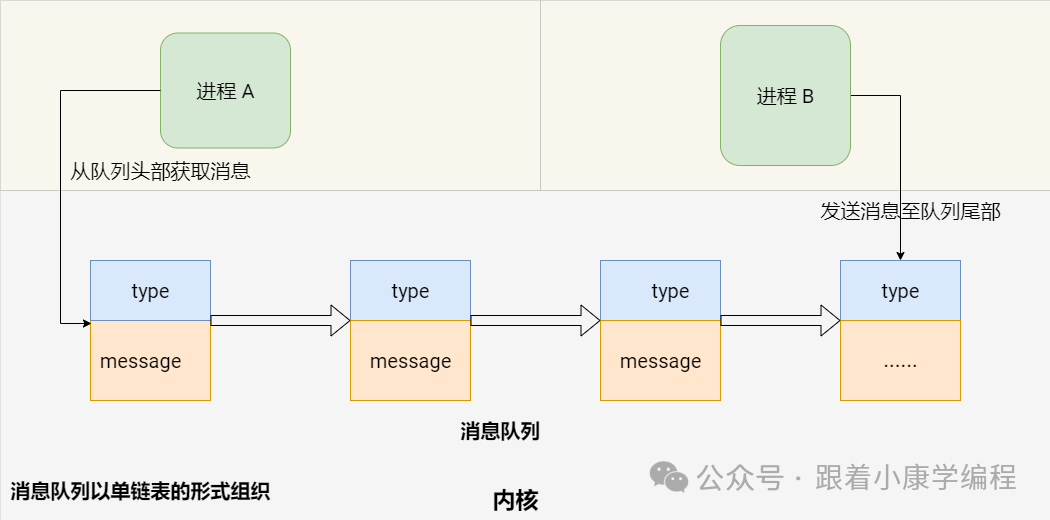
6. Message Queues
concept :
A message queue is an IPC mechanism that allows one or more processes to write messages to it and one or more processes to read messages. Each message is identified by a message queue identifier (ID) and can carry a specific type. Message queues allow different processes to send and receive records or data blocks in a non-blocking manner. These records can be of different types and sizes.
Message queue diagram:
Use scenarios :
-
Inter-process communication: In applications involving multiple running processes, message queues provide an efficient way to pass information. It allows processes to exchange data without directly connecting to each other, thus simplifying the communication process.
-
Asynchronous data processing: Message queues enable processes to process information asynchronously. One process (i.e., producer) can send tasks or data to a queue and continue other operations, while another process (i.e., consumer) can take the data out of the queue and process it when ready. This model effectively separates the data generation and consumption process, improving the efficiency and responsiveness of the application. For example, in actual applications, some systems may have a dedicated process responsible for logging, and other processes can send log messages to a message queue, which is asynchronously written to the log file by the dedicated process.
The following is a simple example using System V message queues:
struct message {
long mtype;
char mtext[100];
};
// 发送消息至消息队列
int main() {
key_t key = ftok("queuefile", 65); // 生成唯一键
int msgid = msgget(key, 0666 | IPC_CREAT); // 创建消息队列
struct message msg;
msg.mtype = 1; // 设置消息类型
sprintf(msg.mtext, "Hello World"); // 消息内容
msgsnd(msgid, &msg, sizeof(msg.mtext), 0); // 发送消息
printf("Sent message: %s\n", msg.mtext);
return 0;
}
// 从消息队列中获取消息
int main() {
key_t key = ftok("queuefile", 65);
int msgid = msgget(key, 0666 | IPC_CREAT);
struct message msg;
msgrcv(msgid, &msg, sizeof(msg.mtext), 1, 0); // 接收消息
printf("Received message: %s\n", msg.mtext);
msgctl(msgid, IPC_RMID, NULL); // 销毁消息队列
return 0;
}
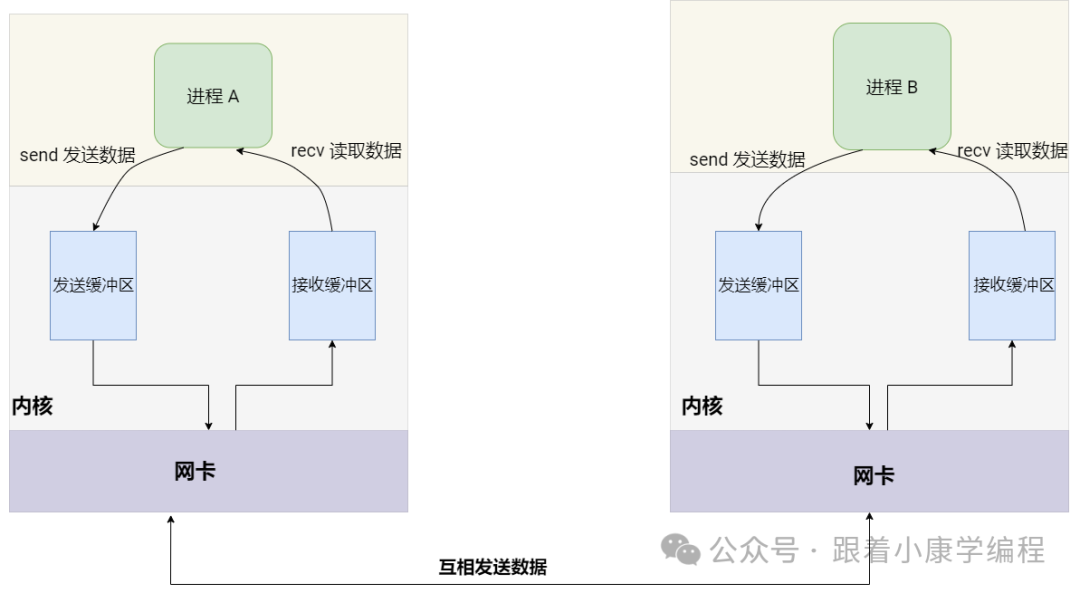
7. Sockets
concept :
Sockets are a communication mechanism for exchanging data between different processes. In Linux, sockets can be used for inter-process communication (IPC) on the same machine or network communication on different machines. Sockets support a variety of communication protocols, the most common of which are TCP (a reliable, connection-oriented protocol) and UDP (a connectionless, unreliable protocol).
Simple diagram:
Use scenarios:
Network communication : Data is exchanged between processes on the same host or on different hosts through network sockets.
Simple example: - Using TCP sockets for communication
Server (server.c)
int main() {
int server_fd, new_socket;
struct sockaddr_in address;
int addrlen = sizeof(address);
char buffer[1024] = {0};
// 创建套接字
server_fd = socket(AF_INET, SOCK_STREAM, 0);
// 定义套接字地址
address.sin_family = AF_INET;
address.sin_addr.s_addr = INADDR_ANY;
address.sin_port = htons(8080);
// 绑定套接字到地址和端口
bind(server_fd, (struct sockaddr *)&address, sizeof(address));
// 监听套接字
listen(server_fd, 3);
while (1) {
// 接受客户端连接
new_socket = accept(server_fd, (struct sockaddr *)&address, (socklen_t*)&addrlen);
// 读取客户端数据
read(new_socket, buffer, 1024);
printf("Message from client: %s\n", buffer);
// 关闭客户端连接
close(new_socket);
}
// 关闭服务器套接字
close(server_fd);
return 0;
}
Client (client.c)
int main() {
int sock = 0;
struct sockaddr_in serv_addr;
// 创建套接字
sock = socket(AF_INET, SOCK_STREAM, 0);
// 定义服务器地址
serv_addr.sin_family = AF_INET;
serv_addr.sin_port = htons(8080);
// 连接到服务器
connect(sock, (struct sockaddr *)&serv_addr, sizeof(serv_addr));
// 发送数据到服务器
char *message = "Hello from the client!";
send(sock, message, strlen(message), 0);
// 关闭套接字
close(sock);
return 0;
}
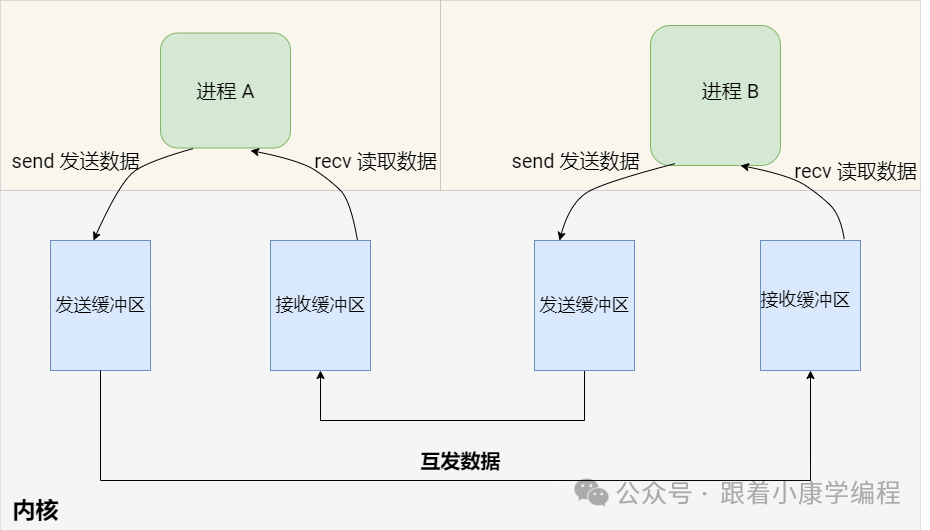
8. Unix Domain Sockets
concept :
Unix Domain Sockets are a mechanism for data communication between processes on the same machine. Compared to network sockets, they provide a more efficient way of local communication because the data does not need to go through the network protocol stack . Domain sockets support two modes: stream (similar to TCP) and datagram (similar to UDP).
Special note : In domain socket communication, "not going through the network protocol stack" means that data transmission does not require IP layer routing, does not require TCP/UDP and other transport layer protocol packet and depacket processing, and does not require the participation of the network interface layer. This is different from network sockets, which are used for cross-network communication and need to go through the complete network protocol stack processing, including data encapsulation, transmission, routing and decapsulation.
Simple diagram:
Use scenarios:
-
Local inter-process communication :
When you need to efficiently exchange data between different processes on the same machine.
-
Alternatives to pipes and message queues :
When more complex bidirectional communication than pipes and message queues can provide is required.
Simple example: - Communicate using Unix domain sockets
Server side (server.c)
int main() {
int server_fd, client_socket;
struct sockaddr_un address;
// 创建套接字
server_fd = socket(AF_UNIX, SOCK_STREAM, 0);
// 设置地址
address.sun_family = AF_UNIX;
strcpy(address.sun_path, "/tmp/unix_socket");
// 绑定并监听
bind(server_fd, (struct sockaddr *)&address, sizeof(address));
listen(server_fd, 5);
while (1) {
// 接受客户端连接
client_socket = accept(server_fd, NULL, NULL);
// 读取客户端发送的数据
char buffer[100];
read(client_socket, buffer, sizeof(buffer));
printf("Received: %s\n", buffer);
// 关闭客户端套接字
close(client_socket);
}
// 关闭服务器套接字并删除 socket 文件
close(server_fd);
unlink("/tmp/unix_socket");
return 0;
}
Client (client.c)
int main() {
int sock;
struct sockaddr_un address;
// 创建套接字
sock = socket(AF_UNIX, SOCK_STREAM, 0);
// 设置地址
address.sun_family = AF_UNIX;
strcpy(address.sun_path, "/tmp/unix_socket");
// 连接服务器
connect(sock, (struct sockaddr *)&address, sizeof(address));
// 发送数据到服务器
char *message = "Hello from the client!";
write(sock, message, strlen(message));
// 关闭套接字
close(sock);
return 0;
}
Note :
-
The address of a Unix domain socket is a path in the file system, not an IP address and port.
-
Unix domain sockets are typically used for communication between processes on the same machine, and are not suitable for network communication.
-
When using Unix domain sockets, you need to ensure that the path to the socket file is accessible and clean up the socket file after the communication is completed.
Tips : The code examples above are just a basic guide to help you quickly understand the basic usage of each inter-process communication method. If you want to learn more deeply and get complete code examples, please follow my official account " Learn Programming with Xiaokang ". Reply " process " in the background of the official account to get the complete code resources! (It is estimated that the complete code can be obtained on October 2. In order to ensure the correctness of the code, the author needs 2-3 days to write it.)
Want to find me faster? Search " Learn Programming with Xiaokang " on WeChat , or scan the QR code below to follow me and grow with a group of programming friends who love learning!
Summarize
There are many ways to communicate between processes in Linux, from the simplest pipe to the complex socket, each of which has its own unique application scenario. Through the study of this article, I hope you have a systematic understanding of these communication methods. Whether it is a small application or dealing with complex inter-process data transmission, finding a suitable IPC method can easily solve the problem.
If you feel like you've got it, congratulations! If you don't fully understand it, that's ok, feel free to leave a comment in the comments section and we can discuss it together to make sure you understand it!
at last
If you find this article helpful, please give me a like and a thumbs up, and share it with friends in need!
-
Subscribe to my official account : I will regularly update more Linux and C++ related programming materials, share advanced skills and practical experience, and help you learn useful knowledge every day.
-
More exciting content is waiting for you to discover : click to follow and receive the latest technical articles as soon as possible. Let’s walk hand in hand on the road to becoming a programming master!
-
Interaction and feedback : If you have any questions or suggestions, please leave a message. I look forward to communicating with you!
What can I learn by following?
I not only provide high-quality programming knowledge, but also combine practical projects and common interview questions to bring you a comprehensive learning path. If you are learning programming, preparing for interviews, or want to improve your skills at work, this is definitely a good helper for you to improve yourself.
How to follow my official account?
It's very simple! Scan the QR code below to follow us.

In addition, Xiaokang has recently created a technical exchange group. If you encounter any problems or have any misunderstandings while reading, you are welcome to join the group or ask in the comment section. I will try my best to reply to you if I can solve them.
Scan Xiaokang’s personal WeChat and note “ join the group ”.






 京公网安备 11010802033920号
京公网安备 11010802033920号