

linux swap memory swap partition detailed introduction



Link: https://www.cnblogs.com/tomato-haha/p/17664414.html
Table of contents
1. What is SWAP and what does it do?
Why do we need memory recycling?
Two types of memory that will be recycled
2. What exactly is swappiness used to adjust?
So what role does swappiness play?
3. When will kswapd perform swap operations?
4. What is a memory watermark?
Related parameter settings
Swap related operation commands
5. What is the use of the swap partition priority?
at last
Q&A:
Overview
The swap discussed in this article is based on the Linux 4.4 kernel code. Linux memory management is a very complex system, and swap is just a small processing logic.
I hope this article can help readers understand how Linux uses swap. After reading this article, it should help you solve the following problems:
1. What exactly is swap used for?
2. What exactly is swappiness used to adjust?
3. When will kswapd perform a swap operation?
4. What is the memory watermark?
5. What is the use of the swap partition priority?
1. What is SWAP and what does it do?
When we talk about swap, we are referring to a swap partition or file. In Linux, you can use the swapon -s command to view the swap space currently in use on the system and related information:
[zorro@zorrozou-pc0 linux-4.4]$ swapon -s
Filename Type Size Used Priority
/dev/dm-4 partition 33554428 0 -1Functionally, the swap partition is mainly used to swap part of the data in the memory to the swap space when the memory is insufficient, so that the system will not cause OOM or more fatal situations due to insufficient memory.
Therefore, when there is pressure on memory usage and memory recycling begins to be triggered, swap space may be used.
The kernel's use of swap is actually closely related to memory recycling. So regarding the relationship between memory recycling and swap, we need to think about the following questions:
-
Why do we need memory recycling?
-
Which memory may be reclaimed?
-
When will the exchange take place during the recycling process?
-
How to exchange specifically?
Let us start from these issues and analyze them one by one.
Why do we need memory recycling?
There are two main reasons why the kernel needs to reclaim memory:
-
The kernel needs to provide enough memory for any sudden memory requests that come in at any time, so it is generally necessary for the kernel to ensure that there is enough free space.
In addition, although the Linux kernel uses the cache strategy, the kernel will use the page cache in the memory to cache some files in order to improve the reading and writing efficiency of the files.
Therefore, it is necessary for the kernel to design a mechanism for periodic memory recovery so that the use of cache and other related memory will not cause the system's remaining memory to be in a very low state for a long time.
-
When there is a request that is larger than the free memory, forced memory recycling will be triggered.
Therefore, the kernel implements two different mechanisms to deal with these two types of recycling needs:
-
One is to use the kswapd process to perform periodic checks on the memory to ensure that the remaining memory is as sufficient as possible under normal conditions.
-
The other is direct page reclaim , which triggers direct page reclaim when there is no free memory to meet the requirements during memory allocation.
The triggering paths for these two types of memory recycling are different:
-
One is that the kernel process kswapd directly calls the memory recycling logic to recycle memory;
See the main logic of kswapd() in mm/vmscan.c
-
The other is to enter the memory application logic of the slow path for recycling when memory is requested.
See the __alloc_pages_slowpath method in mm/page_alloc.c in the kernel code
The actual memory recycling process in these two methods is the same, and ultimately calls the shrink_zone() method to shrink the memory pages for each zone.
This method will call shrink_lruvec() to check the linked list of each organization page. After finding this clue, we can clearly see which pages the memory recycling operation targets.
These linked lists are mainly defined in an enum in mm/vmscan.c:

According to this enum, we can see that there are four linked lists that need to be scanned for memory recovery:
-
anon inactive
-
anon's active
-
Inactive file
-
Active of file
That is to say, the memory recycling operation mainly targets the file pages (file cache) and anonymous pages in the memory.
The kernel will use the LRU algorithm to process and mark whether it is active or inactive. We will not explain this process in detail here.
The entire scanning process is divided into several cycles:
-
First scan the cgroup groups on each zone;
-
Then the page list is scanned using the cgroup's memory as a unit;
-
The kernel will first scan the active list of anon, put the infrequent ones into the inactive list, then scan the inactive list and move the active ones back to the active list;
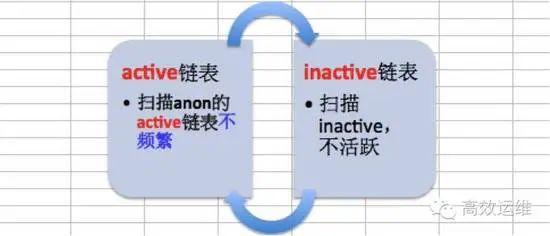
-
When swapping, swap out the inactive pages first;
-
If it is a file mapping page of a file, determine whether it is dirty data. If it is dirty data, write it back. If it is not dirty data, release it directly.

Two types of memory that will be recycled
It seems that the memory recycling behavior will recycle the use of two types of memory:
-
One is anonymous page memory of anon, and the main recovery method is swap;
-
The other is the file-backed file mapping page, the main means of release is writing back and clearing.
Because there is no need to swap file-based memory, its data is originally on the hard disk. To reclaim this part of the memory, just write it back when there is dirty data and clear the memory. If needed in the future, read it back from the corresponding file.
The memory uses a total of four linked lists to organize anonymous pages and file caches. The recycling process mainly scans and operates on these four linked lists.
2. What exactly is swappiness used to adjust?
Many people should know the file /proc/sys/vm/swappiness, which is used to adjust swap-related parameters. The default value of this file is 60, and the possible value range is 0-100.
This can easily give everyone a hint: I am a percentage!
So what does this file mean exactly? Let's take a look at the description first:
======
swappiness
This control is used to define how aggressive the kernel will swap memory pages. Higher values will increase agressiveness, lower values decrease the amount of swap.
A value of 0 instructs the kernel not to initiate swap until the amount of free and file-backed pages is less than the high water mark in a zone.
The default value is 60.
======
The values in this file are used to define how aggressively the kernel uses swap:
-
The higher the value, the more actively the kernel will use swap;
-
The lower the value, the less motivated to use swap.
-
If this value is 0, then memory will not be swapped until the total amount of free and file-backed pages used is less than the high water mark.
Here we can understand the meaning of the word file-backed, which is actually the size of the file mapping page mentioned above.
So what role does swappiness play?
Let's think about this from another perspective. Suppose we design a memory recycling mechanism that writes part of the memory to the swap partition, writes back and clears part of the file-backed memory, and takes out the remaining memory. How would we design it?
I think the following issues should be considered:
-
If there are two ways to reclaim memory (anonymous page swap and file cache clearing), then I should consider when to write back files more often and when to swap more often. In other words, it is about balancing the use of the two recycling methods to achieve the best result.
-
If the memory that meets the swap conditions is long, can we not swap out all of it? For example, if there is 100M of memory that can be swapped, but only 50M is needed at present, we only need to swap out 50M, and we don't need to swap out all of it.
By analyzing the code, we can find that the Linux kernel implements this logic in the get_scan_count() method, which is called by shrink_lruvec().
get_sacn_count() is used to process the above logic. swappiness is a parameter it needs. This parameter actually guides the kernel to decide whether to clear file-backed memory or to swap anonymous pages when clearing memory.
Of course, this is just a tendency. It means that if both are sufficient, you would prefer to use one of them. If they are not enough, then you still have to exchange them.
Take a quick look at the processing code of the get_sacn_count() function. The first process about swappiness is:

It is clearly noted here:
-
If swappiness is set to 100, anonymous pages and files will be reclaimed with the same priority.
Obviously, using the method of clearing files will help alleviate the IO pressure that may be caused by memory recovery.
Because if the data in the file-backed is not dirty data, it does not need to be written back, so no IO occurs. Once the exchange is performed, IO will definitely occur.
Therefore, the system sets the swappiness value to 60 by default. In this way, when reclaiming memory, the proportion of clearing file-backed file cache memory will be greater, and the kernel will be more inclined to clear the cache rather than swap.
-
If the swappiness value is 60, does it mean that when the kernel recycles, it will swap and clear the file-backed space in a ratio of 60:140? No.
When doing this ratio calculation, the kernel also refers to other information about the current memory usage. If you are interested in how this is done, you can read the implementation of get_sacn_count() in detail. This article will not explain it in detail.
The concept we need to clarify here is that the swappiness value is used to control whether more anonymous pages or file cache are recycled when memory is recycled.
-
If swappiness is set to 0, does that mean the kernel will not swap at all? The answer is no.
First of all, when the memory is really insufficient, swapping is still necessary.
Secondly, there is a logic in the kernel that causes swap to be used directly. The kernel code handles this as follows:

The logic here is that if global recycling is triggered and the condition zonefile + zonefree <= high_wmark_pages(zone) is met, the scan_balance mark is set to SCAN_ANON.
When scan_balance is processed later, if its value is SCAN_ANON, a swap operation will be performed on the anonymous page.
To understand this behavior, we must first understand what the high water mark (high_wmark_pages) is.
3. When will kswapd perform swap operations?
Let's go back to the two memory recycling mechanisms of kswapd cycle checking and direct memory recycling.
Direct memory recycling is easier to understand. When the requested memory is greater than the remaining memory, direct recycling will be triggered.
So what are the conditions that trigger recycling during the kswapd process periodic check?
From a design perspective, the kswapd process needs to periodically check the memory and start memory recycling when a certain threshold is reached.
This so-called threshold can be understood as the current memory usage pressure. That is, although we still have remaining memory, when the remaining memory is relatively small, that is, when the memory pressure is high, we should start trying to reclaim some memory. This can ensure that the system has enough memory as much as possible for sudden memory requests.
4. What is a memory watermark?
So how do you describe the pressure of memory usage?
The Linux kernel uses the concept of watermark to describe this pressure situation.
Linux sets three memory watermarks for memory usage: high, low, and min. Their meanings are:
-
If the remaining memory is above high, it means that there is a lot of remaining memory and the current memory usage pressure is not great;
-
The high-low range indicates that there is a certain pressure on the remaining memory;
-
Low-min means that the memory is beginning to have a large usage pressure and there is not much remaining memory;
-
min is the minimum watermark. When the remaining memory reaches this state, it means that the memory is under great pressure.
-
The kernel reserves memory smaller than the minimum size for use in specific situations and is generally not allocated.
Memory recycling behavior is based on the remaining memory watermark to make decisions:
When the system's remaining memory is lower than watermark[low], the kernel's kswapd starts to work and reclaims memory until the remaining memory reaches watermark[high].
If memory consumption causes the remaining memory to reach or exceed watermark[min], direct reclaim is triggered.
After understanding the concept of watermark, the formula zonefile + zonefree <= high_wmark_pages(zone) can be understood.
The zonefile here is equivalent to the total amount of file mapping in memory, and zonefree is equivalent to the total amount of remaining memory.
The kernel generally believes that if the zonefile still exists, it can try to obtain some memory by clearing the file cache, without having to use only swap to exchange anon's memory.
The whole concept of judgment is that in the state of global recycling (with global_reclaim(sc) mark), if the value of the current file mapping total memory + the remaining total memory is evaluated to be less than or equal to the watermark[high] mark, direct swap can be performed.
This is to prevent cache traps. For details, see the code comments.
The impact of this judgment on the system is that when swappiness is set to 0, swapping may occur even if there is remaining memory.
So how is the watermark correlation value calculated?
All memory watermarks are calculated based on the current total memory size and an adjustable parameter, which is:
/proc/sys/vm/min_free_kbytes
-
First of all, this parameter itself determines the value of watermark[min] for each zone in the system.
-
Then the kernel calculates the low water level and high water level values of each zone based on the size of the min and the memory size of each zone.
To understand the specific logic, please refer to the file in the source code directory:
mm/page_alloc.c
In the system, you can view the current system-related information and usage from the /proc/zoneinfo file.
We will find that the above memory management related logic is based on zone, where zone means the partition management of memory.
Linux divides memory into multiple areas, mainly:
-
Direct Access Area (DMA)
-
Normal
-
High Memory
The kernel's access to different memory areas may have different addressing and efficiency due to hardware structural factors. If it is on a NUMA architecture, the memory managed by different CPUs is also in different zones.
Related parameter settings
zone_reclaim_mode:
The zone_reclaim_mode mode is a mode added to the kernel in the late 2.6 version. It can be used to manage the option of reclaiming memory from within a memory area (zone) or from other zones when the memory inside the zone is exhausted. We can adjust this parameter through the /proc/sys/vm/zone_reclaim_mode file.
When applying for memory (in the kernel's get_page_from_freelist() method), if there is not enough memory available in the current zone, the kernel will decide whether to find free memory from the next zone or reclaim it within the zone based on the setting of zone_reclaim_mode. A value of 0 indicates that free memory can be found from the next zone, and a non-zero value indicates that memory is reclaimed locally.
The values that can be set in this file and their meanings are as follows:
-
echo 0 > /proc/sys/vm/zone_reclaim_mode: means turning off the zone_reclaim mode and reclaiming memory from other zones or NUMA nodes.
-
echo 1 > /proc/sys/vm/zone_reclaim_mode: indicates that the zone_reclaim mode is turned on, so that memory reclaim only occurs in the local node.
-
echo 2 > /proc/sys/vm/zone_reclaim_mode: When reclaiming memory locally, dirty data in the cache can be written back to the hard disk to reclaim memory.
-
echo 4 > /proc/sys/vm/zone_reclaim_mode: Memory can be reclaimed using swap.
Different parameter configurations will have different effects on the memory usage of other memory nodes in a NUMA environment. You can set them according to your own situation to optimize your application.
By default, zone_reclaim mode is disabled. This can improve efficiency in many application scenarios, such as file servers, or application scenarios that rely heavily on in-memory cache.
Such a scenario relies more on the memory cache speed than the process itself relies on the memory speed, so we would rather request memory from other zones than clear the local cache.
If you determine that the application scenario has a memory demand that is greater than the cache, and you want to avoid performance degradation caused by memory access across NUMA nodes, you can turn on the zone_reclaim mode.
At this time, the page allocator will give priority to reclaiming reclaimable memory that is easy to reclaim (mainly page cache pages that are not currently in use), and then reclaim other memory.
Turning on writeback in local recycling mode may trigger a large amount of dirty data writeback processing on other memory nodes. If a memory zone is full, the writeback of dirty data will also affect the process processing speed and create a processing bottleneck.
This will reduce the performance of processes related to a memory node, because the process can no longer use the memory on other nodes. However, it will increase the isolation between nodes, and the running of related processes on other nodes will not be degraded due to memory recycling on another node.
Unless there are changes to the memory limit policy or cpuset configuration for the local node, the limit on swap will effectively constrain swapping to only the area managed by the local memory node.
min_unmapped_ratio:
This parameter is only valid on NUMA kernels. The value represents the percentage of the total number of pages in each memory region on NUMA.
In zone_reclaim_mode, zone memory reclaim will only occur if the memory usage of the associated zone reaches this percentage.
When zone_reclaim_mode is set to 4, the kernel compares all file-backed and anonymous mapped pages, including pages occupied by swapcache and tmpfs files to see if the total memory usage exceeds this percentage.
With other settings, only the unmapped pages based on the general file are compared, and other related pages are not considered.
page-cluster:
Page-cluster is used to control the number of pages read continuously at a time when swapping in data from the swap space, which is equivalent to pre-reading the swap space. The continuity here refers to the continuity in the swap space, not the continuity in the memory address.
Because the swap space is usually on the hard disk, continuous reading of the hard disk device will reduce the addressing of the head and improve the reading efficiency.
The value set in this file is an exponent of 2. That is, if it is set to 0, the number of swap pages pre-read is 2 to the power of 0, which is equal to 1 page. If it is set to 3, it is 2 to the power of 3, which is equal to 8 pages.
At the same time, setting it to 0 also means turning off the pre-reading function. The default value of the file is 3. We can set the pre-reading page size according to our system load status.
Swap related operation commands
You can use mkswap to create a swap space from a partition or file. swapon can view the current swap space and enable a swap partition or file. swapoff can disable swap space.
We use an example file to demonstrate the entire operation process:
Create a swap file:

Enable the swap file:

To close the swap space:

5. What is the use of the swap partition priority?
When using multiple swap partitions or files, there is also a concept of priority.
When swapon, we can use the -p parameter to specify the priority of the relevant swap space. The larger the value, the higher the priority. The specifiable number range is -1 to 32767.
When using swap space, the kernel always uses the space with higher priority first, and then the space with lower priority.
Of course, if the priorities of multiple swap spaces are set to the same, then the two swap spaces will be used in parallel in a round-robin manner.
If two swaps are placed on two different hard disks, the same priority can have a similar effect to RAID0, increasing the read and write efficiency of swap.
In addition, you can also use mlock() when programming to mark the specified memory as not to be swapped out. For specific help, please refer to man 2 mlock.
at last
The recommendations for using swap are different for systems with different load states. Sometimes we want a larger swap size so that when memory is insufficient, the oom-killer will not be triggered, causing some key processes to be killed, such as database services.
Sometimes we don't want to swap, because when a large number of processes explode and cause the memory to explode, the IO will be killed due to swap, and the entire system will be stuck, unable to log in, and unable to process.
At this time, we hope that swap is not required, and even if oom-killer occurs, it will not cause much impact, but we cannot allow the server to crash like dominoes due to IO jams and be unable to log in. The stateless Apache running CPU calculations is a program with a process pool architecture like this.
so:
-
How to use swap?
-
Do you want it or not?
-
Setting large or small?
-
How should the relevant parameters be configured?
It depends on the situation of our own production environment.
After reading this article, I hope you can understand some in-depth knowledge of swap.
Q&A:
-
Is it possible to use swap in a system with a relatively large amount of remaining memory?
A: It is possible. If the condition "zonefile+zonefree<=high_wmark_pages(zone)" is triggered at a certain stage during the operation, swap may occur.
-
Is setting swappiness to 0 equivalent to turning off swap?
A: No, to turn off swap you need to use the swapoff command. swappiness is just a parameter used to balance cache recycle and swap when memory is reclaimed. Adjusting it to 0 means that memory is reclaimed by clearing the cache as much as possible.
-
A: If swappiness is set to 100, does it mean that the system will try to use less remaining memory and more swap?
No, setting this value to 100 means that when memory is recycled, the priority of reclaiming memory from cache and swapping is the same. That is, if 100M memory is currently required, there is a high probability that 50M memory will be cleared from cache, and then 50M anonymous pages will be swapped out, and the reclaimed memory will be used by the application. But this also depends on whether there is space in the cache and whether the swap can swap 50M. The kernel just tries to balance them.
-
When does the kswapd process start memory recycling?
A: kswapd decides whether to start reclaiming memory based on the memory water level mark. If the mark reaches low, it starts reclaiming until the remaining memory reaches high.
-
How to view the current system memory watermark?
A: cat /proc/zoneinfo.
Autumn
The recruitment has already begun. If you are not well prepared,
Autumn
It's hard to find a good job.
Here is a big employment gift package for everyone. You can prepare for the spring recruitment and find a good job!







 京公网安备 11010802033920号
京公网安备 11010802033920号