introduce
Digital signal processing (DSP) is a specialized method of processing signals and data with the purpose of enhancing and modifying these signals. Digital signal processing is also used to analyze signals to determine specific information content. DSP is mainly used to process real-world signals. These signals can be converted and represented by digital sequences. We then process the signal using mathematical methods to extract specific information from the signal or transform the signal in some way.
DSP is very common in real-time embedded systems, where the timeliness and accuracy of calculations are equally important. DSPs are very common in these environments because they are designed to perform common signal processing operations very quickly. The programmability of DSPs allows applications to evolve over time, providing numerous advantages to application vendors. DSP programming requires familiarity with the application, DSP hardware architecture, and code generation tools for writing efficient real-time software that meets system deadlines.
This article, the first of two, will explore some important software and system optimization techniques for DSPs and will explain some guidelines for developing efficient embedded applications using powerful processors.
The first rule of optimization – don’t!
Before starting any optimization work, you must know where you are going. From a performance perspective, all software is different! You must first understand where the bottleneck is. Once you've described your application, it's time to start tweaking the code. Describing an application means measuring how long each part of the code takes (or how much memory it uses, or how much power it consumes). Some parts of the software are executed only once (such as initialization) or a limited number of times. It is unwise to spend a lot of time optimizing this part of the code because the overall savings gained by doing so are relatively limited. It is likely that some parts of the software will be executed many times, and even though the code itself is short, the fact that the code is executed often indicates that the overall cycle of the code is time-consuming. If you can save even a cycle or two from this part of the code, the savings can be significant. This is where you should spend your time working as you tune and optimize your process.
memory dependencies
The processor stores instructions and data in memory. Although many innovative methods have been created to obtain instructions and data from memory, there is always a performance penalty when accessing instructions and data. This is pure overhead. As long as the time spent waiting for instructions or data access can be reduced, the overall performance of the application can be improved no matter what. For example, a hardware cache system will move as many instructions as possible as close to the CPU as possible so that they can be accessed quickly, often in just one cycle, which has been proven to improve overall performance. DSPs have on-chip memory that stores data and instructions. But data and instructions are not automatically placed in on-chip memory. Programmers have to manage this, and when managed effectively, DSPs can take advantage of on-chip memory to significantly improve performance.
There are several levels in the embedded system memory hierarchy (see Figure 1). The first level is the chip register. This part of memory is used to store temporary and intermediate data. The compiler uses registers when dispatching instructions. This memory is the fastest and most expensive (the more registers on a device, the larger the device, which means fewer devices on the silicon wafer, which means using more silicon to get the same number of devices, You should know what I mean). The next level of memory is the cache system. It is also fast and expensive, and is used to move instructions and data closer to the CPU before the instructions and/or data are used. The next level down from memory is "external" or "off-chip" memory. This memory will be slower and less expensive than other memory types. This is generally where data and instructions are saved when they are not in use (longer storage life). Accessing information from this memory involves more handshaking and control, and therefore requires more time. The main goal of a real-time embedded designer is to keep whatever you're going to use as close to the CPU as possible. This means taking information from external memory into faster memory and using techniques such as direct memory access (DMA), as well as compilation or architectural techniques.

To enhance the performance of processors using the concept of pipelining, hardware architecture techniques are used. The principles of an assembly line processor are no different than an automobile assembly line. Each car is put together step by step on the assembly line. Many vehicles are on the assembly line at the same time, each at a different point in the assembly process. At the end of the assembly line a new car will appear, followed by another new car, and so on. It has long been discovered that it is much more cost-effective to start assembly of the next new car before the previous one is completed. The same is true in pipelined processors. Pipeline processors can start a new task before the previous task is completed. Completion rate is the rate at which new instructions are coming in. As shown in Figures 2a and 2b, the completion time of the instructions does not change. But the completion rate of instructions increased.
To further improve performance, we can use multiple pipelines. This approach, called superscalar, further exploits the concept of parallelism (see Figure 2c). Some high-performance digital signal processors today (such as the Intel i860) have a superscalar design.

Figure 2. Non-pipelined, pipelined and superscalar execution schedules

DSPs with multiple independent execution units take advantage of parallel execution of multiple independent instructions simultaneously, which will provide immediate performance improvements. The key is to find "n" different instructions that are independent of each other. Sometimes we do this in hardware, sometimes in software (compilation). Very Long Instruction Word (VLIW) processors, such as TI's C6200 DSP family, use compilation technology to schedule up to eight independent instructions on eight independent processor execution units. Data dependencies between instructions often limit this to below the maximum rate, but significant performance can still be achieved. In many cases, we can restructure the algorithm to take advantage of the architecture, thereby realizing the benefits of multiple execution units.
Compared with pipeline processors, superscalar architectures can provide more parallel processing capabilities. However, if an algorithm or function cannot take advantage of this parallelism, then the extra pipeline will go unused, reducing the amount of parallelism that can be achieved. An algorithm written to run quickly on a pipelined processor may not necessarily run equally efficiently on a superscalar processor. For example, we can look at the algorithm shown in Figure 4a. The algorithm was written to take advantage of pipeline processors. This is a common way to compute polynomials on serial processors because it eliminates the need to compute p**8, p**7, etc. This saves cycles and registers to store intermediate values.
But in the case of superscalar devices, this is not the best way to evaluate the expression. Parentheses in an algorithm limit the compiler's ability to evaluate expressions sequentially. This also makes parallel functionality unavailable. If we decompose this expression into several independent expressions, the compiler can arrange these independent expressions in any convenient order on the parallel pipeline of the superscalar device. Computations performed in this way utilize fewer instruction cycles and more registers (as shown in Figure 4b).
The above examples illustrate why programmers must understand the device architecture, compiler, and algorithms to determine the fastest way to perform any particular function. We'll discuss other ways to accelerate function computation using the high-performance devices mentioned above.
rp = (((((((R8*p + R7) * p + R6) * p + R5) * p + R4) * p + R3) * p + R2) * p + R1) * p
Figure 4a)
p2 = p * p
p3 = p * p * p
.
.
p8 = p * p * p * p * p * p * p * p
---------------------------------------------
R1p1 = R1 * p
R2p2 = R2 * p2
.
.
R8p8 = R8 * p8
----------------------------------------------
rp = 0.0F
rp += R1p1
.
.
rp += R8p8
图 4b)
图4. a)、编写可快速运行于流水线处理器上的算法。B)、 相同算法经修改后在超标量处理器上快速运行。
直接存储器存取
直接存储器存取 (DMA)是无 CPU 介入情况下访问存储器的一种方式。外设用于向内存直接写入并导出数据,这就减轻了 CPU 的负担。DMA 就是另一种类型的CPU,其唯一作用就是快速移动数据,其优势则在于 CPU 可以向 DMA 发出一些指令移动数据,随后就可以再进行原本的工作。DMA 在 CPU 运行的同时移动数据(图 5)。这实际就是另一种利用器件内置并行功能的方法。DMA 在复制大量数据时非常有用。较小的数据块无法受益,因为还要考虑到 DMA 的设置和开销时间,反倒不如直接使用 CPU 合适。但如果明智使用的话,DMA 可以节约大量时间。

图 5. 使用 DMA 而非 CPU 能够显著提升性能
由于访问外部存储器会带来很大的性能损失,且占用 CPU 的代价不菲,因此只要有可能,就应采用 DMA。最好是在实际需要数据前就启动 DMA 操作。这让CPU 同时也有工作可做,且不用强制应用等待数据的移动。随后,当确实需要数据时,数据就已经就位了。应用应当进行检查,以确认操作成功,这将要求检查寄存器。如果操作提前完成,这将对寄存器进行一次查询,但不会产生大量工作,占用宝贵的处理时间。
DMA 的常见用法是将数据移入或移出芯片。CPU 访问片上存储器的速度大大快于其访问片外或外部存储器的速度。将尽可能多的数据放于芯片上是提高性能的最佳途径。如果被处理的数据不能全部同时放于芯片上(如大型阵列),那么数据可使用 DMA 成块地移入或移出芯片。所有数据传输都可在后台进行,同时 CPU 对数据进行实际处理。片上存储器的智能管理和布局可以减少数据必须移入、移出存储器的次数。就如何使用片上存储器开发出智能计划,在这项工作上投入时间和精力是值得的。总体而言,规则就是使用 DMA 将数据移入、移出片上存储器并在芯片上生成结果(图 6)。由于成本和空间原因,大多数 DSP 不具备很多芯片上存储器。这要求编程人员协调算法,以高效利用现有的片上存储器。
为使用 DMA 测量代码确实会产生一些性能损失。根据应用使用 DMA 的多少,代码大小会上升。如果全面启用 DMA,我们曾遇到过代码大小增长 50% 的情况。使用 DMA 还增加了复杂性和应用的同步化。只有在要求高吞吐量的情况下才应使用 DMA。但是,片上存储器的智能布局和使用以及明智地使用 DMA 能够消除大多数访问片外存储器所带来的性能损失。

图 6. 使用 DMA 将数据移入、移出芯片的模板
等待状态与探询
就像存储器和CPU一样,可将DMA视为资源。在DMA操作进行过程中,应用可以等待DMA传输完成,也可以继续处理应用的另一部分,直到数据传输完成为止。每种方法都有其优势和劣势。如果应用等待DMA传输完成,那么它必须探询DMA硬件状态寄存器,直至对比特的设置完成。这要求CPU在循环操作中检查DMA状态寄存器,从而导致浪费宝贵的CPU周期。 如果传输较短,那么这只需几个周期就可完成,等等也是值得的。如果数据传输较长,应用工程师可能希望使用同步化机制,如在传输完成时发出信号标志一样。在这种情况下,应用会在传输发生时通过系统等待信号标志。该应用将与另一个准备运行的应用进行交换。任务交换也会导致开销,因此如果任务交换产生的开销大于对DMA完成进行简单探询带来的开销,那么就不应进行任务交换。等待时间取决于被传输数据的数量。
图7显示了检查传输长度并执行DMA探询操作(如果只需要传输几个字的话)或信号标志等待操作(对较大型数据传输而言)的一些代码。数据大小"平衡"长度取决于处理器以及接口结构,应当建立起原型,以确定最佳大小。
图8显示了等待操作的代码。在这种情况下,应用将进行SEM_pend操作,以等待DMA传输的完成。通过暂时中止当前执行的任务并交换到另一项任务以进行其他处理,可使应用能够进行其他有意义的工作。当操作系统中止一项任务而开始执行另一项任务时,会导致一定量的开销。开销量的大小取决于DSP和操作系统。
图9显示了探询操作的代码。在该例中,应用将继续探询DMA完成状态寄存器以获知操作是否完成。这要求使用CPU来进行探询操作。这样做使CPU无法进行其他有意义的工作。如果传输足够短,那么CPU只需在短时间内探寻状态寄存器,这种方法也就可以更有效。
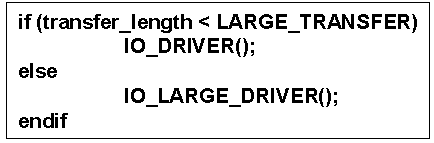
图7. 检查传输长度并调用驱动程序功能的代码片段,其将探询DSP状态寄存器中的DMA完成位,抑或等待操作系统信号标志。
最后决策建立于数据传输数量以及CPU探询必须进行多少周期的基础上。如果探询所需时间少于操作系统交换任务并开始执行新任务的开销,那么这种方法就会更有效。

图 8. 等待 DMA 完成信号标志的代码片段?
图9. 探询 DMA 是否完成的代码片段
内存的管理
DSP 最重要的资源之一就是其本身片上或内部的存储器。这是大多数计算将发生的地方,因为访问该存储器比访问片外或外部存储器要快得多。由于许多 DSP 因为决定不可预见性的缘故都不具备数据高速缓冲存储器,因此软件设计人员将 DSP 内存看作是一种由程序员管理的高速缓冲存储器。与程序员不能控制的处理器硬件高速缓冲存储器数据以提高性能不同,DSP 内部数据存储器在DSP程序员的完全控制之下。使用 DMA,数据可以在后台进出内存,基本或完全不受DSP CPU的干预。如果管理正确有效的话,内存会成为非常有价值的资源。
It is very important to arrange the use of memory and manage where data enters memory at all times. Given the limited amount of memory used for many applications, not all program data can be stored in memory during application execution time. Over time, data is moved into memory, processed, possibly reused, and moved to external storage when no longer needed. Figure 10 shows a possible memory map of the internal DSP memory during application execution. As the application executes, different data structures are moved into on-chip memory and eventually moved off-chip to external memory or overwritten in memory when not needed.

Figure 10. DSP memory that must be managed by the programmer
Conclusion
Direct memory access (DMA) is a method of accessing memory without CPU intervention. Peripherals are used to write and export data directly to memory, which relieves the load on the CPU. DMA is just another type of CPU. Its only function is to move data quickly. The advantage is that the CPU can issue some instructions to the DMA to move the data, and then the original work can be resumed. Programmers should take full advantage of DMA's capabilities, especially for data-intensive number processing applications common in DSP systems. DMA can greatly reduce the burden on the CPU and help manage data efficiently.
Next time, we'll discuss some other DSP optimization techniques that take advantage of the DSP device architecture and use the compiler to schedule efficient code, which can also significantly improve performance. Specific topics will include software pipelining and loop unrolling techniques.
bibliography
TMS320C62X Programmer's Guide, Texas Instruments, 1997;
"Computer Architecture, a Quantitative Approach" by John L Hennesey and David A Patterson, Copyright 1990 Morgan Kaufmann Publishers, Palo Alto, CA.
Previous article:Application of scheduler in DSP programming
Next article:Application of scheduler in DSP programming
Recommended ReadingLatest update time:2024-11-16 23:49

- Popular Resources
- Popular amplifiers
 Siemens PLC Project Tutorial
Siemens PLC Project Tutorial




- Huawei's Strategic Department Director Gai Gang: The cumulative installed base of open source Euler operating system exceeds 10 million sets
- Analysis of the application of several common contact parts in high-voltage connectors of new energy vehicles
- Wiring harness durability test and contact voltage drop test method
- Sn-doped CuO nanostructure-based ethanol gas sensor for real-time drunk driving detection in vehicles
- Design considerations for automotive battery wiring harness
- Do you know all the various motors commonly used in automotive electronics?
- What are the functions of the Internet of Vehicles? What are the uses and benefits of the Internet of Vehicles?
- Power Inverter - A critical safety system for electric vehicles
- Analysis of the information security mechanism of AUTOSAR, the automotive embedded software framework
 Professor at Beihang University, dedicated to promoting microcontrollers and embedded systems for over 20 years.
Professor at Beihang University, dedicated to promoting microcontrollers and embedded systems for over 20 years.






- Innolux's intelligent steer-by-wire solution makes cars smarter and safer
- 8051 MCU - Parity Check
- How to efficiently balance the sensitivity of tactile sensing interfaces
- What should I do if the servo motor shakes? What causes the servo motor to shake quickly?
- 【Brushless Motor】Analysis of three-phase BLDC motor and sharing of two popular development boards
- Midea Industrial Technology's subsidiaries Clou Electronics and Hekang New Energy jointly appeared at the Munich Battery Energy Storage Exhibition and Solar Energy Exhibition
- Guoxin Sichen | Application of ferroelectric memory PB85RS2MC in power battery management, with a capacity of 2M
- Analysis of common faults of frequency converter
- In a head-on competition with Qualcomm, what kind of cockpit products has Intel come up with?
- Dalian Rongke's all-vanadium liquid flow battery energy storage equipment industrialization project has entered the sprint stage before production
- Allegro MicroSystems Introduces Advanced Magnetic and Inductive Position Sensing Solutions at Electronica 2024
- Car key in the left hand, liveness detection radar in the right hand, UWB is imperative for cars!
- After a decade of rapid development, domestic CIS has entered the market
- Aegis Dagger Battery + Thor EM-i Super Hybrid, Geely New Energy has thrown out two "king bombs"
- A brief discussion on functional safety - fault, error, and failure
- In the smart car 2.0 cycle, these core industry chains are facing major opportunities!
- The United States and Japan are developing new batteries. CATL faces challenges? How should China's new energy battery industry respond?
- Murata launches high-precision 6-axis inertial sensor for automobiles
- Ford patents pre-charge alarm to help save costs and respond to emergencies
- New real-time microcontroller system from Texas Instruments enables smarter processing in automotive and industrial applications
- [Anxinke NB-IoT Development Board EC-01F-Kit] V. Comprehensive Test
- 【Beetle ESP32-C3】VII. Network timing and weather request (Arduino)
- If anyone has a Concise Mechanical Manual, please send me a copy. I'd be very grateful.
- Here is the camera information on the national competition list
- 【Intelligent courtyard integrated control system】 Environmental parameter acquisition unit hardware
- A collection of digital IC front-end design learning materials, one-click download without points
- RF Components Test Technology Seminar for 5G - You are invited to attend!
- What suitable domestic chips are recommended?
- EEWORLD University Hall----Application of Infineon Industrial Semiconductors in the Motor Drive Industry
- A legendary figure in the world of microwave and radio frequency






 京公网安备 11010802033920号
京公网安备 11010802033920号