With the development and diversification of communication protocols, the protocol processing part PE generally adopts the existing commercial chip NP (Network Processor) to implement hardware forwarding, and the traffic management part needs to be customized according to the needs of the system or use commercial chips to complete. In many cases, NP chips, TM chips, and switching network chips cannot be selected from the same manufacturer. At this time, customizing TM becomes the lowest cost and most system-optimized solution, which is generally implemented using FPGA. The general structure of TM is shown in Figure 1.

Figure 1 General structure of TM
At present, the mainstream TM interface is in the form of SPI4-P2 interface. The signal rate of SPI4-P2 interface is high, and TCCS (Channel-to-channel skew, jitter of data channel, including clock jitter) is difficult to control. It is difficult to achieve a very high rate under normal circumstances. In order to achieve high rate and avoid TCCS problem, SPI4-P2 interface puts forward DPA (dynamic phase adjustment) requirements on the receiving end in many cases. For the SPI4-P2 interface form, the IP Core of Altera can be directly used. Altera's mainstream FPGAs all implement the hardware DPA function. Taking Stratix II devices as an example, the interface data rate of 16Gb/s can be achieved by using SPI4-P2 IP Core with DPA enabled.
The SEG module is a data segmentation block. According to the data structure requirements of the switching network, it is responsible for segmenting IP packets or data packets into fixed-size data blocks in the direction of the switching network, which is convenient for later storage scheduling and switching network operation processing. The SEG module can be implemented in conjunction with the SPI4-P2 IP Core. The RSM module corresponds to the SEG module, which reassembles the data blocks from the switching network into complete IP packets or data packets.
The BM (Buffer Management) module is a buffer management module that manages the buffer unit of the TM and completes the DRAM access operation. The control part of the external DRAM can be implemented using the DDR SDRAM IP Core.
The QM module is a queue management module, which is responsible for completing the data queue management function of the port and receiving the data entry and exit requests when the BM module reads and writes DRAM. The performance indicators such as the number of data flows, the number of service types, and the number of ports that the TM can support are reflected in the QM module.
The Scheduler module is a scheduling module that schedules packets based on their type, priority, and bandwidth allocated to the port. TM traffic shaping, QOS, and other functions are implemented through the scheduling module.
The CELL_EDIT module completes the packaging of output data, packaging the data read from DRAM and sending it out.
In TM, different management strategies need to be implemented for data packets of different service levels based on data service strategies. At the same time, it is necessary to ensure that the data packets of streaming media are not out of order. Data packets are large and small, and the number of data blocks divided by the SEG module is also large and small. Therefore, there must be an effective data structure based on the linked list method to manage these data. The QM module manages the queue based on the business and data flow, and the management of the packet is completed by the BM module. [page]
The packet-based data structure in the BM module consists of two parts: BRAM and PRAM. BRAM is a data buffer, corresponding to the off-chip DRAM. BRAM is responsible for storing data units. Relative to the data units divided by the SEG module, there are corresponding storage units BCELL in the BRAM. BCELL is divided by address space in the BRAM. Each BCELL is the same size. BCELL is the smallest access unit of BRAM. In the actual system, the size of the data unit divided by the SEG module is generally 64 to 512B.
PRAM is a pointer buffer, and PRAM corresponds to the off-chip SSRAM. The address space inside PRAM is also divided into PCELLs, and PCELLs correspond to BCELLs one by one. Each PCELL corresponds to a BCELL, and the corresponding PCELL and BCELL have the same address.
The address of PCELL corresponds to the address of BCELL of the corresponding unit. The basic information in PCELL is the next hop pointer. The relationship between PRAM and BRAM is shown in Figure 2.

Figure 2 PRAM and BRAM relationship diagram
There are two types of linked lists in PRAM. PQ List represents the linked list of stored data packets. To facilitate data reading, PQ List needs to record the first data block address of the data packet, that is, the first pointer Pq_Hptr. To facilitate new data writing, PQ List needs to record the last data block address of the data packet, that is, the tail pointer Pq_Tptr. PQ List also needs to record the length of the linked list as the weight calculation for scheduling by the scheduling module.
Free List represents the idle address queue. In order to easily identify and manage idle addresses and avoid address conflicts, all idle addresses are managed in a linked list in BM. This linked list is the idle address queue. The idle address queue has different forms depending on the system requirements. Generally, the structure of the idle address queue is similar to that of the PQ List, consisting of the idle address first pointer Free_Hptr and the idle address tail pointer Free_Tptr. All operations of the BM module revolve around the idle address queue Free List. [page]
Based on the data flow structure of the BM module, the BM module is generally divided into the Write CONtrol module, the Free List control module, the Read Control module, the PRAM Control module, and the BRAM Control module. The structure of the BM is shown in Figure 3.

Figure 3 BM structure diagram
The Write Control module obtains the free address from the Free List module, submits a write request to the BRAM Control module, and updates the content in the PRAM. The Free List control module is responsible for managing the free address list, providing the Write Control module with the write BRAM address and PRAM address, and recovering the address released after the Read Control module reads the data block. The Read Control module reads the data unit to be sent through the BRAM Control module according to the scheduling result of the scheduler, and writes the released buffer unit address into the free address list. The PRAM Control module is the control module of the external SSRAM and can be directly completed using the reference design. The BRAM Control module is an external DRAM control module, which is generally divided into two sub-modules: Datapath and Controler. The Datapath module is specifically responsible for the data interface part, completing the DQ, DQS processing of the DRAM interface and the corresponding delay adjustment. The Controler module is responsible for completing the DRAM control requirements.
In the BM module, the bandwidth of BRAM and PRAM are usually the bottlenecks of TM. The bandwidth of PRAM is mainly limited by the number of accesses, while the bandwidth of BRAM is limited by the interface bandwidth. For example, for a 10G TM, the effective bandwidth of BRAM must be guaranteed to be 20G. Assuming that the interface utilization can only reach 65% at worst (considering the N+1 problem that occurs when the SEG module splits the cells), the interface bandwidth must be guaranteed to reach 30G. When using a 64-bit DRAM interface, the interface rate cannot be lower than 500MB/s, which puts higher requirements on the design of the Datapath module. In actual systems, BRAM mainly uses DDR SDRAM and DDR II SDRAM.
When using Stratix II FPGA and BRAM using DDR II SDRAM, the test shows that the DDR II SDRAM interface rate can reach 800MB/s. Under normal use, the DDR II SDRAM interface rate can be guaranteed to reach 667MB/s. For a 64-bit DRAM interface, the interface rate can reach 42.7GB/s, which is fully sufficient for a 10G TM system.
The BM module is a buffer management module. The basic unit of the buffer is BCELL. Based on the management of BCELL, the operations on the BM involve the operations of the idle address queue and the linked list. The most basic operations are write operations and read operations. The write operation of the BM module is initiated by the Write Control module. [page]
For the Write Control module, if there is a data unit that needs to be written, it first applies for a free address from the Free List module. The Free List gives the first pointer a to the Write Control module as the write address of the data block, and at the same time reads the content corresponding to the first pointer a in the PRAM to obtain the next hop address b, and uses the next hop address b as the new free address first pointer.
PQ List updates the tail pointer n to the newly written address a, and updates the content of address n in PRAM, adding a as the next hop to address n. In order to save operation cycles, the content of NULL retains the original value and is no longer updated. In this way, a BRAM write operation requires a PRAM read operation and a PRAM write operation.
The QM module receives the dequeuing information from the scheduling module and transmits the dequeued PQ linked list information to the BM module for reading operation.

Figure 4 BM module write operation
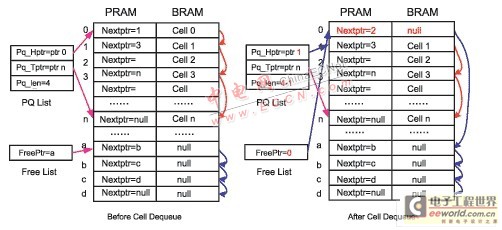
Figure 5 Free List stack structure for read operation
The read operation of the BM module is initiated and completed by the Read Control module. When a data unit needs to be read out, the corresponding data unit address needs to be recycled into the free address queue Free List. For different system requirements, the free address queue Free List has different forms. The simpler operation is to use the Free List as a stack.
The Read Control module reads the corresponding BRAM content from the first address 0 of the PQ List, and reads the corresponding next hop address 1 in the PRAM, and updates address 1 to the new first address. The Free List updates the first pointer a to the newly released address 0, and writes the next hop pointer a to address 0. In this way, a BRAM read operation requires a PRAM read operation and a PRAM write operation. [page]
In actual operation, the idle address queue in the form of a stack will put part of the idle address queue into the on-chip buffer. This can save a write operation of the PRAM when the BRAM releases the address to enter the idle address queue when reading, and save a read operation of the PRAM when applying for the idle address when writing the BRAM. The built-in idle address queue table under the PRAM stack structure is shown in Figure 6.

Figure 6 Built-in free address queue table under PRAM stack structure
Taking the read operation of FIG. 5 as an example, when the Read Control module reads the content in the corresponding BRAM from the first address 0 of the PQ List, it reads the corresponding next hop address 1 in the PRAM at the same time, and updates address 1 to the new first address. At this time, address 0 is the address that has been released. According to the operation requirements of the free queue, address 0 needs to enter the free address queue. During the write operation, address 0 is read out and provided to the Write Control module for writing BRAM. Based on the structure of FIG. 6, after being released, address 0 no longer updates the free address queue Free List in the PRAM, but is directly written into the on-chip buffer. When the Write Control module applies for an address, it is read out from the on-chip buffer and provided to the Write Control module. Only when the on-chip Free List buffer is almost full, the free address queue Free List in the PRAM is updated, or when the on-chip Free List buffer is empty, the free address queue Free List in the PRAM is read. Based on the structure of FIG. 6, two PRAM operations can be saved in a read-write cycle, and one PRAM operation can be saved in the worst case. However, based on the stack structure, the addresses at the top of the stack are frequently called repeatedly, and the addresses at the bottom of the stack are rarely used, which will affect the service life of the DRAM. To ensure the service life of the DRAM, some systems make the free address queue Free List into a linked list to ensure that the storage space of each DRAM can be used evenly. The Free List linked list structure of the read operation is shown in Figure 7.

Figure 7 Free Lis linked list structure for read operation
The Read Control module reads the content in the corresponding BRAM from the first address 0 of the PQ List, and at the same time reads the corresponding next hop address 1 in the PRAM, and updates address 1 as the new first address.
Compared with the stack mode, the Free List adds a tail pointer d. When reclaiming an address, the Free List maintains the head pointer a unchanged, updates the tail pointer d to the newly released address 0, and writes the next hop pointer 0 to address d. In this way, a BRAM read operation also requires a PRAM read operation and a PRAM write operation. For the linked list free address queue Free List, two PRAM write operations and two PRAM read operations must be performed in each read and write cycle, and the PRAM efficiency is not high. [page]
In view of the efficiency of the two free address queues and their impact on DRAM, a compromise method is adopted in many systems. That is, a linked list method is used in PRAM to manage the free address queue Free List, and a stack mode is used in the chip to build another free address queue Free List. In this case, each read and write cycle requires three PRAM operations.
In actual systems, the bandwidth of BRAM and PRAM are generally the bottlenecks of TM. PRAM is mainly limited by the number of accesses, while BRAM is limited by the interface bandwidth.
In the 10G TM system, the bit width of the on-chip data bus is set to 128 bits, the system clock is set to 150MHz, and the size of the BCELL is set to 64B. In this case, the read and write operations are both 4 clock cycles. Under the requirements of the 10G system, the read and write operation cycles are 7 clock cycles. It has been calculated before that under the conditions of the 10G TM system, the BRAM uses 64-bit DDR II SDRAM, and the interface clock uses 250MHz to meet the requirements of the data interface. PRAM uses 32-bit ZBT SRAM, the interface clock uses the system clock, each PCELL is 64 bits, and each read and write cycle requires 6 clock cycles to complete. In the actual system, Altera FPGA is used, and the design of BM can meet the requirements of 10G TM line speed operation.
In the TM system of the 40G core network, the bit width of the on-chip data bus is 256 bits, and the system clock uses 250MHz (200MHz can be selected in the 40GE system). Using DDR II SDRAM, the interface clock uses 333MHz, and the 192-bit BRAM can meet the 40G TM requirements. At this time, BCELL can be 96B, 192B, or 384B, and 192B is selected here. When BCELL uses 192B, the read and write operations are also 6 clock cycles. Under the requirements of the 40G system, the read and write operation cycles are 9 clock cycles. PRAM uses 48-bit QDR SRAM, the interface clock uses 150MHz, each PCELL is 96 bits, and the PRAM can be operated up to 5 times in each read and write clock cycle. In the case of using Altera FPGA, BRAM uses 192-bit DDR II SDRAM, PRAM uses 48-bit QDR SRAM, and the BM design can meet the requirements of 40G TM line speed operation.
Previous article:FPGA global clock resource related primitives and their use
Next article:Improved Nagao filter based on texture analysis
Recommended ReadingLatest update time:2024-11-16 21:58

- Popular Resources
- Popular amplifiers
-
 Analysis and Implementation of MAC Protocol for Wireless Sensor Networks (by Yang Zhijun, Xie Xianjie, and Ding Hongwei)
Analysis and Implementation of MAC Protocol for Wireless Sensor Networks (by Yang Zhijun, Xie Xianjie, and Ding Hongwei) - MATLAB and FPGA implementation of wireless communication
- Intelligent computing systems (Chen Yunji, Li Ling, Li Wei, Guo Qi, Du Zidong)
- Summary of non-synthesizable statements in FPGA
 Analysis and Implementation of MAC Protocol for Wireless Sensor Networks (by Yang Zhijun, Xie Xianjie, and Ding Hongwei)
Analysis and Implementation of MAC Protocol for Wireless Sensor Networks (by Yang Zhijun, Xie Xianjie, and Ding Hongwei)




- Huawei's Strategic Department Director Gai Gang: The cumulative installed base of open source Euler operating system exceeds 10 million sets
- Analysis of the application of several common contact parts in high-voltage connectors of new energy vehicles
- Wiring harness durability test and contact voltage drop test method
- Sn-doped CuO nanostructure-based ethanol gas sensor for real-time drunk driving detection in vehicles
- Design considerations for automotive battery wiring harness
- Do you know all the various motors commonly used in automotive electronics?
- What are the functions of the Internet of Vehicles? What are the uses and benefits of the Internet of Vehicles?
- Power Inverter - A critical safety system for electric vehicles
- Analysis of the information security mechanism of AUTOSAR, the automotive embedded software framework
 Professor at Beihang University, dedicated to promoting microcontrollers and embedded systems for over 20 years.
Professor at Beihang University, dedicated to promoting microcontrollers and embedded systems for over 20 years.






- Innolux's intelligent steer-by-wire solution makes cars smarter and safer
- 8051 MCU - Parity Check
- How to efficiently balance the sensitivity of tactile sensing interfaces
- What should I do if the servo motor shakes? What causes the servo motor to shake quickly?
- 【Brushless Motor】Analysis of three-phase BLDC motor and sharing of two popular development boards
- Midea Industrial Technology's subsidiaries Clou Electronics and Hekang New Energy jointly appeared at the Munich Battery Energy Storage Exhibition and Solar Energy Exhibition
- Guoxin Sichen | Application of ferroelectric memory PB85RS2MC in power battery management, with a capacity of 2M
- Analysis of common faults of frequency converter
- In a head-on competition with Qualcomm, what kind of cockpit products has Intel come up with?
- Dalian Rongke's all-vanadium liquid flow battery energy storage equipment industrialization project has entered the sprint stage before production
- Allegro MicroSystems Introduces Advanced Magnetic and Inductive Position Sensing Solutions at Electronica 2024
- Car key in the left hand, liveness detection radar in the right hand, UWB is imperative for cars!
- After a decade of rapid development, domestic CIS has entered the market
- Aegis Dagger Battery + Thor EM-i Super Hybrid, Geely New Energy has thrown out two "king bombs"
- A brief discussion on functional safety - fault, error, and failure
- In the smart car 2.0 cycle, these core industry chains are facing major opportunities!
- The United States and Japan are developing new batteries. CATL faces challenges? How should China's new energy battery industry respond?
- Murata launches high-precision 6-axis inertial sensor for automobiles
- Ford patents pre-charge alarm to help save costs and respond to emergencies
- New real-time microcontroller system from Texas Instruments enables smarter processing in automotive and industrial applications
- Take a look at the antique filter
- Fudan Micro offline programmer information and MCU application notes
- [GD32E503 Review] Part 9: Simple Oscilloscope
- Bring your girlfriend home to meet your parents
- [Fudan Micro FM33LG0 series development board review] Development board microcontroller printf Chinese and English printing test
- Control the state of multiple IOs through the serial port
- Mobile phone RF is moving towards integrated chips
- EEWORLD University ---- Make your home safer - Intelligent building security system
- TI 2022 exciting technical live replays are ready for you!
- Phase-locked loop CD4046 application introduction






 京公网安备 11010802033920号
京公网安备 11010802033920号