An autonomous robot navigating unknown terrain; a video decoder that changes decompression format based on signal strength; a broadband electronic countermeasures system; an adaptive image tracking algorithm for motor vehicles… these are among the emerging embedded or mission-critical applications that need to respond quickly to environmental transients. In the past, static decision-making worst-case allocations provided a solution for strict real-time constraints, but now flexibility is a requirement. The solution proposed by a French research project is an operating system distributed across FPGA resources to manage software and hardware threads.
Our goal is to design an architecture that supports new types of system partitions, allowing software and hardware components to follow the same execution model. This requires a highly flexible and extensible operating system.
In recent years, especially in embedded systems, with the increase in the density of system-on-chip (SoC), it is possible to increase the number of computing units by processing tasks and data in parallel to meet the requirements of design constraints. At present, this trend continues with the addition of heterogeneous computing cores. However, this technology has encountered an insurmountable complexity barrier because it requires a higher level of abstraction of the programming model.
To overcome these challenges, we propose to define a unified execution model that can be used regardless of whether threads are mapped to hardware or software. The hardware implementation of this execution model relies heavily on the use of dynamically reconfigurable logic. The fully distributed architecture combined with traditional multi-core software subsystems can combine the advantages of both software and hardware. The software part is good for intelligent event control and decision-making, while the hardware part excels in improving energy efficiency, throughput, and digital computing. By combining the two, we can achieve the best balance between performance and resource utilization, both for each specific application and for a specific state of an application.
The new FPGA platform is highly flexible, scalable, and highly integrated, capable of integrating a complete heterogeneous dynamic computing system on a single or two chips.
Adaptive hardware is very useful in applications such as missile electronics and software radio, where power consumption and system size are limited and the environment is highly sensitive. Dynamic reconfiguration technology can be used to implement a dedicated architecture that supports different application modes without increasing system power consumption or board size. Traditional solutions focus on the control part, which now seems to be unable to effectively meet the number of execution units and their heterogeneity requirements. Only a distributed solution that is both flexible and scalable can create a future-oriented architecture.
Despite the potential of this technology, dynamic reconfiguration is still a challenge for the industry. Engineers need a clear design approach that can fully exploit the advantages of dynamic reconfiguration without affecting the application description and, most importantly, without increasing the development cost. To combine dynamicity with high performance, we propose to abstract heterogeneity by adopting a multithreaded execution model. Developers can program applications as a collection of threads, regardless of whether the threads are executed on standard processors or dedicated hardware. In this case, dynamic reconfiguration plays a role in thread preemption and context switching. The FOSFOR (Flexible Reconfigurable Platform Operating System) project, sponsored by the French National Research Agency (ANR), is dedicated to developing this new generation of embedded, distributed real-time operating systems.
FOSFOR Architecture Foundation
Our goal is to design an architecture that supports new types of system partitioning, where software/hardware components follow the same execution model. This requires a highly flexible and extensible operating system that provides similar interfaces to both software and hardware domains. Unlike traditional approaches, this operating system is fully distributed and the entire platform is homogeneous from the application perspective. This means that application threads can be deployed either statically or dynamically in software (processors) or hardware (reconfigurable units) with indiscriminate access to distributed services.
To achieve high efficiency, we implement OS services in hardware right next to the reconfigurable region. We implement a communication layer between heterogeneous OS kernels to ensure that services are homogeneous from the application perspective. Therefore, deploying the OS as a large number of modules and execution units on the architecture can take full advantage of virtualization mechanisms, allowing application threads to run and communicate without foreseeing tasks.
From a programmer's perspective, the application is just a collection of threads. We can leverage the dynamic reconfiguration capabilities of Xilinx FPGAs to propose this new concept of hardware threads, and we can implement it in the same way as software threads. Our implementation leverages the performance benefits of dedicated compute IP blocks.
Besides considering the execution units in a multiprocessor SoC, the memory structure must also meet several requirements: data storage required by application threads, storage of the execution context of each thread, and data exchange between threads. For the storage of the execution context, we consider several possibilities. One way is to store the execution context centrally, thus providing a medium for distributing it to different execution units. We can identify three communication flows within the platform: application data, control signals, and reconfiguration/execution context. For high-bandwidth data paths between hardware threads, we use a dedicated network-on-chip (NoC).
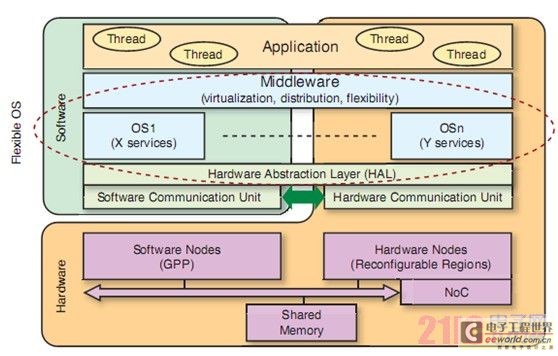
Figure 1: Generic FOSFOR architecture
Text in the figure:
Flexible operating system Software Threads Applications Middleware (virtualization, distribution, flexibility) Operating system 1 (X service) Operating system n (Y service) Hardware Abstraction Layer (HAL) Software Communication Unit Hardware Communication Unit Hardware Software Node (GPP) Hardware Node (Reconfigurable Region) On-Chip Network Shared Memory
Global Architecture
The global architecture is shown in Figure 1 and consists of:
A set of non-specialized (general purpose) processors (GPPs). GPPs are responsible for supporting the execution of software threads and a set of operating system services including thread scheduling. GPPs do not have to be homogeneous in terms of instruction set architecture and the number of services provided.
A set of dynamically reconfigurable partitions, also called reconfigurable regions (RRs). Dynamically reconfigurable partitions are responsible for executing a set of hardware threads in parallel or serially. Similar to GPPs, RRs also support the execution of operating system services due to the use of a hardware operating system (HwOS). These regions correspond to fine-grained (FPGA) or coarse-grained (reconfigurable processor) architectures.
Virtual communication channels that share one or more physical communication channels for control, data, and configuration. The control channel is responsible for distributing communication between operating system services to execution units (GPPs and RRs). The data channel is responsible for transmitting information about the environment (devices, sensors) and information exchange between threads. The configuration channel is responsible for transmitting the configuration of software threads (binary code) and hardware threads (partial bitstreams) between the configuration memory and the execution units.
Each processor has its own local memory. This memory is responsible for storing local data and, where applicable, software code. Shared memory connected to the data channel allows data sharing between threads on different processors. Each execution unit can access data and software execution resource programs stored on the shared memory. Each resource can also access the configuration memory to save and restore its execution context. With this structure, any thread or service can be implemented on any execution resource.
Inside the RR, only hardware tasks need to be dynamically reconfigured. The dynamic region (DR) responsible for hosting tasks is surrounded by the static region (SR) containing the hardware implementation of the operating system services and providing the communication medium inside and outside the RR. Internal data flow communication relies on a dedicated on-chip network. The interface between the DR and the SR uses bus macros and has a fixed location. To achieve this constraint and abstract the heterogeneity of the communication medium, we use a middleware solution to provide virtual access to the reconfigurable partitions. The RR is built according to the model defined in Figure 2. The FOSFOR prototype platform consists of dynamically reconfigurable FPGA devices that can directly support this architectural model. We chose the Virtex-5® device because it can reconfigure rectangular regions.
We define a scheduling/placement algorithm based on the pre-calculated resource requirements of application threads to ensure efficient utilization of FPGA elements (LUTs, registers, distributed memory, I/O) in each RR.

Figure 2 - Reconfigurable Region Structure
Text in the figure:
Control Context (bitstream) Static area Reconfigurable area Static area Data Hardware operating system Control dynamic area Thread Data On-chip network Hardware partition
Operating system, on-chip network and middleware To provide flexibility, the FOSFOR architecture uses at least two operating system instances: one software operating system running on each processor and responsible for handling software threads; the other is a hardware operating system that can manage hardware threads. In order to achieve the best balance between performance, development time and standardization, we use existing software operating systems and new hardware operating systems.
The hardware operating system takes advantage of the dynamic partial reconfiguration capability of Xilinx FPGAs to schedule hardware threads as flexibly as traditional operating systems schedule software threads.
The requirements for the software operating system are real-time behavior, the ability to handle multiple processors and provide basic inter-process communication services. We chose a free and open source operating system, RTEMS. For compatibility reasons, we chose the LEON Sparc soft-core processor, which is also free and open source, like the software node.
The hardware operating system (HwOS) uses the dynamic partial reconfiguration function of Xilinx FPGA to schedule hardware threads as flexibly as traditional operating systems schedule software threads. The hardware thread consists of two parts: dynamic and static. The dynamic part contains an IP module for executing thread functions and a finite state machine for synchronizing the service call order with the hardware operating system. The static part contains a control interface connected to the hardware operating system and a network interface for exchanging data with other hardware and software tasks.
To support multiple inter-thread data transfer needs, we developed a flexible on-chip network DRAFT. The communication services of traditional operating systems are sufficient to support communication between software threads. However, in our design, the operating system also needs to support communication between hardware threads. For this purpose, we designed a special DRAFT network. We synthesize hardware threads one by one for one or more DRs, and statically define each DR interface.
The static definition of the communication interface allows us to define a static on-chip network. Generally, hardware threads require high bandwidth and low latency, so the on-chip network must provide high performance. The topology we chose for DRAFT is an extension of the fat tree topology. The main goal of our design is to limit resource overhead while achieving high performance inter-thread communication.
The heterogeneity of hardware platforms is a major complexity barrier that designers face when deploying applications. In the FOSFOR project, this heterogeneity comes not only from different embedded processors in the software domain, but also from the integration of software and hardware computing models on a single platform.
This problem can be solved by using middleware to establish an abstraction layer between hardware and software and provide a homogeneous programming model. The middleware implements a set of virtual channels that allow threads to communicate without having to worry about the implementation area of the threads. These services are distributed across platforms and provide a flexible and extensible abstraction layer that completes the FOSFOR concept.
Performance Acceleration
The main reasons for building a hardware OS were performance and flexibility. This OS could have been pure software or pure hardware. Since each call to an OS primitive involves overhead, i.e. thread wait time, the faster the OS, the less time is wasted. To evaluate the overhead, we had to compare the timing of the hardware OS to the original software OS, RTEMS.
The hardware local run only takes tens of cycles, while the hardware global run takes hundreds of cycles to access shared memory. We evaluated that the local create-delete operation was 60 times faster than the software OS, and other operations were about 50 times faster.
The resource usage of the hardware operating system (Table 1) varies greatly, depending on the number of services activated and their functionality, such as the number of objects (semaphores, threads, etc.) we choose for each service. We use the Xilinx Virtex-5 FX100T to implement the system. The table lists the resources used by the hardware operating system. The remaining resources can be used to implement other system components and the hardware threads themselves.
|
Number of structures implemented
|
8
|
16
|
32
|
|
CLB Slice
|
2,408 (15%)
|
3,151 (20%)
|
4,327 (27%)
|
|
D Flip Flop
|
5,498 (8.5%)
|
6,650 (10.4%)
|
8,918 (13.9%)
|
|
BRAM
|
8 (3.5%)
|
16 (7%)
|
32 (14%)
|
Table 1 - Resource usage of the hardware operating system (Virtex-5 FX100)
Regarding network performance, in a configuration where DRAFT connects eight 32-bit word-width components with a buffer depth of four words and a frequency of 100MHz, the on-chip network can achieve a maximum data rate of up to 1,040Mbps for each connected component. The network topology and routing protocol ensure that there will be no contention and congestion. At least one communication path is always maintained between two interconnected components. The average latency of data through DRAFT is close to 45 clock cycles (450 nanoseconds), which meets the requirements of many applications.
Outlook
We propose an innovative operating system that can provide a homogeneous execution model based on multithreading on a heterogeneous multicore architecture consisting of multiple processors and dynamically reconfigurable hardware IP blocks. The hardware operating system is responsible for managing hardware threads, generally for thread creation and inhibition, as well as information flow and message queue services. In terms of communication, we propose to improve the fat tree topology on-chip network for data exchange, a dedicated bus for hardware thread management, and a communication layer for synchronization between operating systems.
From an industry perspective, the next step is to demonstrate the capabilities of the hardware added to ensure homogeneity of the execution model, which can really improve programming efficiency while keeping the performance overhead on the dedicated IP blocks low.
We will demonstrate our approach on a representative Thales application based on a search-and-track algorithm. Tracking threads will be mapped to reconfigurable partitions and created dynamically based on target detections.
Previous article:Research on the application of complex system based on single chip microcomputer with dual CPU
Next article:Intel demonstrates ultra-low-power processor powered by solar energy
- Popular Resources
- Popular amplifiers
-
 Research report on overall technical requirements of vehicle control operating system
Research report on overall technical requirements of vehicle control operating system - Research report on the standardization requirements of vehicle computing platforms
- ZxOS Zephyr-based Guest Operating System for Heterogeneous ISA Machines
- Beyond the Threaded Programming Model on Real-Time Operating Systems
 Research report on overall technical requirements of vehicle control operating system
Research report on overall technical requirements of vehicle control operating system- Molex leverages SAP solutions to drive smart supply chain collaboration
- Pickering Launches New Future-Proof PXIe Single-Slot Controller for High-Performance Test and Measurement Applications
- CGD and Qorvo to jointly revolutionize motor control solutions
- Advanced gameplay, Harting takes your PCB board connection to a new level!
- Nidec Intelligent Motion is the first to launch an electric clutch ECU for two-wheeled vehicles
- Bosch and Tsinghua University renew cooperation agreement on artificial intelligence research to jointly promote the development of artificial intelligence in the industrial field
- GigaDevice unveils new MCU products, deeply unlocking industrial application scenarios with diversified products and solutions
- Advantech: Investing in Edge AI Innovation to Drive an Intelligent Future
- CGD and QORVO will revolutionize motor control solutions






- Innolux's intelligent steer-by-wire solution makes cars smarter and safer
- 8051 MCU - Parity Check
- How to efficiently balance the sensitivity of tactile sensing interfaces
- What should I do if the servo motor shakes? What causes the servo motor to shake quickly?
- 【Brushless Motor】Analysis of three-phase BLDC motor and sharing of two popular development boards
- Midea Industrial Technology's subsidiaries Clou Electronics and Hekang New Energy jointly appeared at the Munich Battery Energy Storage Exhibition and Solar Energy Exhibition
- Guoxin Sichen | Application of ferroelectric memory PB85RS2MC in power battery management, with a capacity of 2M
- Analysis of common faults of frequency converter
- In a head-on competition with Qualcomm, what kind of cockpit products has Intel come up with?
- Dalian Rongke's all-vanadium liquid flow battery energy storage equipment industrialization project has entered the sprint stage before production
- Allegro MicroSystems Introduces Advanced Magnetic and Inductive Position Sensing Solutions at Electronica 2024
- Car key in the left hand, liveness detection radar in the right hand, UWB is imperative for cars!
- After a decade of rapid development, domestic CIS has entered the market
- Aegis Dagger Battery + Thor EM-i Super Hybrid, Geely New Energy has thrown out two "king bombs"
- A brief discussion on functional safety - fault, error, and failure
- In the smart car 2.0 cycle, these core industry chains are facing major opportunities!
- The United States and Japan are developing new batteries. CATL faces challenges? How should China's new energy battery industry respond?
- Murata launches high-precision 6-axis inertial sensor for automobiles
- Ford patents pre-charge alarm to help save costs and respond to emergencies
- New real-time microcontroller system from Texas Instruments enables smarter processing in automotive and industrial applications
- 【AT-START-F425 Review】Overclocking Performance of AT32F425
- I can't access GitHub anymore, what should I do? I can't access it at all
- [Mill MYB-YT507 development board trial experience] opencv face detection
- TouchGFX application development based on STM32CubeMX on STM32H7A3 processor - HelloWorld!
- How large a fifo capacity can ep4ce6 achieve?
- Introduction to the causes of TPS79633KTTR voltage instability
- Bicycle modification series: colorful taillights
- Staying at home during the epidemic, reading books
- 【TI recommended course】#Motor control voltage and current sampling solution#
- Allwinner heterogeneous multi-core AI intelligent vision V853 development board evaluation - separate compilation and testing of V853 SDK LVGL routines






 京公网安备 11010802033920号
京公网安备 11010802033920号