0 Introduction
Today's society has entered the information age, and traditional information carriers and communication methods can no longer meet people's demand for information. Experiments have shown that compared with voice and abstract data, humans receive more information in the form of pictures and videos. Among them, video information is intuitive, specific and efficient, which determines that video communication technology will become one of the important technologies in the information age.
Since the amount of video data is huge, and the resources for storing videos are usually very limited, it is necessary to compress and encode the video to reduce the consumption of storage resources. However, in general, the higher the complexity of the compression algorithm used, the higher the compression ratio, and the lower the decoding speed during video playback. Therefore, while improving the encoding compression rate, it is also necessary to optimize the decoder accordingly to improve the performance of the video decoder on the target platform. This article implements the transplantation and vectorization of the ffmpeg decoder on Loongson 3B, improving the performance of the decoder on Loongson 3B.
1 Video Encoding/Decoding and Loongson 3B
1.1 Video Encoding/Decoding
At present, there are many mature compression coding/decoding methods. Among them, H.261, MPEG-1, MPEG-3 and H.263 use the first generation of compression coding methods, such as predictive coding, transform coding, entropy coding and motion compensation; while MPEG-4 and H.264 use the second generation of compression coding methods, such as segment coding and model-based or object-based coding.
The main purpose of video compression coding is to reduce the resources occupied by video storage, while the goal of decoding technology is to increase the decoding speed, thereby improving the smoothness of video playback. Common soft decoders based on H. 264 encoding methods include CoreAVC, ffmpeg and JM. Among them, JM is the codec provided by the H. 264 official website, which combines various coding/decoding algorithms, and the code structure is clear, which is very suitable for the research of video coding/decoding technology. The CoreAVC decoder is mainly used for commercial purposes, and its decoding rate is more than 50% faster than ffmpeg. ffmpeg is an open source decoder with relatively good performance. Many open source projects directly or indirectly use ffmpeg, such as mplayer player. Through comprehensive consideration of performance and open source characteristics, this article chooses ffmlpeg as the transplantation and vectorization object.
1.2 Loongson 3B architecture
While being compatible with the MIPS64 instruction set, the Loongson 3B processor also implements vector extension instructions for multimedia applications, which greatly helps improve the performance of video encoding/decoding applications.
Loongson 3B provides 256-bit vector registers and implements vector extension instructions including 256-bit vector access registers. Using vector instructions, operations on 32-byte width data can be completed at one time. Such a structure and instruction set design make Loongson 3B very suitable for implementing large-scale operations on the same type of data, such as matrix multiplication and FFT operations, as well as video encoding/decoding operations.
However, since ffmpeg does not support the Loongson 3B platform, it is necessary to complete the porting of ffmpeg to Loongson 3B. Before this article, there were some porting work of ffmpeg to other platforms and porting and optimization work for the Loongson platform, all of which achieved good results.
2 ffmpeg porting based on Loongson 3B
2.1 ffmpeg porting
The ffmpeg decoder provides support for different target platforms, and the files related to these platforms are stored in directories named after the target platform. For example, the ffmpeg decoder implements support for the arm and sparc platforms, as well as the x86 platform.
To implement ffmpeg decoder support for Loongson 3B, the following five steps are mainly completed:
(1) Modify the configure configuration file and add configuration options related to the Loongson architecture;
(2) Create a new Godson folder for Loongson and store all files related to the Loongson architecture in this folder;
(3) Add the newly added files that need to be compiled in the godson folder to the Makefile;
(4) Added a new initialization function dsputil_init_godson similar to dsputil_init;
(5) Add the declaration of the new function in the header file.
The ffmpeg porting work for Loongson 3B is relatively simple, so this article focuses on the vectorization work for Loongson 3B.
2.2 Performance comparison of transplanted ffmpeg
This section tests the performance of the ported ffmpeg decoder and compares the performance of the two cases with and without the Godson 3B vector extension instructions. The test was compiled using the GCC compiler that supports the Godson 3B extension instruction set, and the -ftree-vectorize and -march=godson3b compilation options were enabled to support the Godson 3B extension instructions. The test case used was the video "walk_vag_640x480_qp26.264", and the test results are shown in Table 1.
From the test results in Table 1, we can see that the use of the vector extension instructions of Loongson 3B can improve the performance of the ffmpeg decoder on Loongson 3B, and the decoding time of the video used for the test is reduced by about 466s. However, due to the limitation of the automatic vectorization capability of the GCC compiler itself, the performance improvement of the ffmpeg decoder is still relatively limited. Therefore, vectorizing the transplanted ffmpeg decoder for the instruction set of Loongson 3B has become an important task to further improve the performance.

3 ffmpeg vectorization
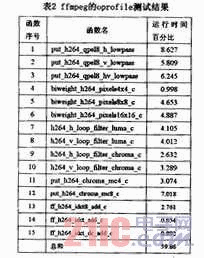
3.1 ffmpeg oprofile test
The process of ffmpeg decoding the video "Wendao Wudang 002.mkv" was tested using oprofile, and the test results are shown in Table 2. Table 2 lists the calling process of each function and the proportion of running time. The vectorization work for the ffmpeg decoder is mainly aimed at the vectorization of several functions with longer execution time and larger running proportion in the oprofile test results.
[page]
The execution time of the above functions accounts for almost 60% of the execution time of the ffmpeg decoder. Therefore, vectorizing the above functions can completely achieve the purpose of improving the overall decoding speed of ffmpeg.
3.2 ffmpeg vectorization for Loongson 3B
3.2.1 Vectorization Method
The main method of implementing the vectorization of the ffmpeg decoder on Loongson 3B is to use the extended vector instructions of Loongson 3B to improve several functions with a large execution time in the oprofile test results in Section 3.1. In addition, while vectorizing, some optimization strategies can also be used to improve the performance of the vectorized functions. The main optimization methods used include:
(1) Loop unrolling. Loop unrolling is a loop transformation technique that copies the instructions in the loop body multiple times, increases the amount of code in the loop body, and reduces the number of loop repetitions. It should be noted that loop unrolling itself cannot directly improve program performance.
The main purpose of loop unrolling is to fully exploit the parallelism between instructions or data. The use of vector extension instructions takes advantage of the parallelism of data in the unrolled loop, while the use of instruction scheduling and software pipelining in the unrolled loop is to fully exploit the parallelism between instructions.
(2) Instruction scheduling. After loop expansion, the number of instructions in the loop body increases, so instruction scheduling can be performed to schedule instructions that have no operand dependencies and no computing unit dependencies together. This can give full play to the pipeline performance of Loongson 3B, thereby improving the execution speed of the code on Loongson 3B.
In addition to using the vector extension instructions of Loongson 3B and the above two optimization methods, other optimization methods can also be used according to the characteristics of specific functions, such as using logical operations and shift operations to replace multiplication operations. The vectorization optimization for each function is introduced in Section 3.2.2.
3.2.2 Vectorization of Specific Functions
Section 3.2.1 outlines some optimization methods used in vectorization. This section will focus on optimizing several functions that are important in the oprofile test.
For the functions in Table 2, we can classify them according to the function names. Functions with similar names can basically use similar optimization methods.
(1) Simple vectorization. For the optimization of functions 1 and 2, this paper adopts the strategy of using shift operations instead of multiplication operations, and uses saturated vector operations to improve the bounded characteristics of the internal operations of the loop. However, for the memory access operation of function 2, due to the existence of data misalignment, additional vector instructions are used to pack and write back the data. Function 3 is a mixture of functions 1 and 2, so the optimization of functions 1 and 2 indirectly improves the performance of function 3.
As for functions 4, 5, and 6, this paper only uses loop unrolling and instruction scheduling strategies for their inner loops to achieve good computing results.
Similarly, functions 11 and 12 can also be vectorized relatively intuitively, which will not be described in detail here.
(2) Indirect vectorization. For functions 7 and 8, which are more difficult to vectorize, this paper adopts the strategies of using masks and matrix transposition operations to indirectly achieve vectorization.
There are many judgment statements in the C language implementation of the h264 v loop filter luma function. This article uses the method of constructing a mask to eliminate these judgment statements.

The construction of the mask is introduced by taking the loop in Figure 1(a) as an example. Figure 1(b) shows the vector instruction that replaces the loop. The specific operation result is shown in Figure 1(c): saturated subtraction is performed on the p vector (array) and the q vector (negative results are set to 0), and the result vector is shown as Vsub. Use Vsub to compare with the zero vector to set the mask: if the result is true, the mask value is 0xFF; otherwise, if the result is false, the mask value is 0. Finally, the mask value is ANDed with the p vector to get the operation result of the loop.
Using the mask construction method to eliminate the judgment statement not only reduces the time overhead caused by the judgment, but also indirectly vectorizes the loop and improves the function performance. The same method can be used to improve functions 9 and 10.
As for function 8, since the operation is to process continuous data, it cannot be vectorized. By using the matrix transposition method, the data can be repackaged and the corresponding vector operation can be performed.

For the operation in Figure 2(a), the original calculation is an operation inside the P vector, so it cannot be vectorized. We use vector instructions to transpose the p vector to q, where q0 stores the data labeled 1 in p, q1 stores the data labeled 2 in P, and so on. The transposed q vector can be operated using the vector instructions in Figure 2(b), and the result is the same as the original operation.
[page]
The above transposition method is also used for the optimization of functions 13 to 15. The test results in Section 4.1 illustrate the optimization effects of each function.
4 Experimental Results
4.1 ffmpeg function speedup ratio
This paper tests each function after vectorization and compares it with the function before vectorization. The speedup ratio of each function after vectorization optimization is shown in Figure 3. The function numbers shown on the horizontal axis in the figure correspond to the functions in Table 2.
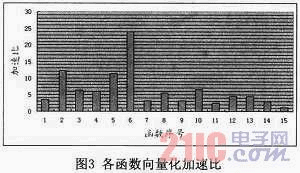
The speedup ratios of the functions in Figure 3 span a wide range. For example, the speedup ratio of function No. 6 is about 23.9, while the speedup ratio of the last function is only about 1.2. The reason for the above situation is not only related to the number of vector instructions used by the improved function and the proportion of modified code, but also related to the type of operands used in the operation. For function No. 6, the type of operands used in the operation in its loop is byte type, so only using vector instructions for optimization, the theoretical speedup ratio can reach 32. However, this paper only vectorizes the inner loop of the function, and the inner loop after vectorization only processes 16 byte type data at a time, that is, it does not fully use the 256-bit vector register. Therefore, the theoretical speedup ratio should be 16, but due to the combination of other optimization strategies such as loop unrolling and instruction scheduling, the actual speedup ratio can reach about 23.9. Similarly, by analyzing the three functions of the same type, No. 4, No. 5 and No. 6, we can also find that the speedup ratio of the latter function is about twice that of the former function. This is because for function No. 4, the inner loop can calculate 4 bytes of data at a time after vectorization, while function No. 5 can calculate 8 bytes of data at a time. Therefore, the theoretical acceleration ratio should also be twice the geometric progression, and the actual results are consistent with the theoretical analysis.
For function 7 and function 8 introduced in Section 3.3.2, their original functions cannot be simply vectorized. This paper uses optimization methods such as mask and matrix transposition to enable them to use the vector extension instructions of Loongson 3B. Therefore, although the performance improvement is not significant, the speedup ratio is 3.2 and 5.5 respectively.
4.2 Comparison of vectorization on different platforms
This article also tests the ffmpeg decoder on different platforms. The two test videos used are "Wendao Wudang 002.mkv" (video A) and "walk_vag_ 640x480_qp26.264" (video B). Video A is a clip from the "Wendao Wudang" video (720p), while the latter is generated by encoding walk_vag.yuv (480p) with x264, and the qp value selected during encoding is 26. The test platforms are AMD and Intel processor platforms respectively.

From the test results in Table 3, we can see that for video A, the performance improvement on Loongson 3B is much higher than that on the other two platforms; and for video B, the performance improvement on Loongson 3B is also close to that on the other two platforms. The experimental results show that the vectorization of the ffmpeg decoder on Loongson 3B is of great help to the performance improvement, and when decoding some videos, the performance improvement is even higher than that of commercial processors with superior performance. By comparing with the results of GCC vectorization compilation in Table 1, we can also see that manually vectorizing the ffmpeg decoder has a greater performance improvement than using GCC vectorization.
5. Summary and Outlook
This paper implements the transplantation of ffmpeg decoder to Loongson 3B, and implements manual vectorization of ffmpeg decoder based on the support of vector extension instructions of Loongson 3B. The experimental results show that the performance of the manually vectorized ffmpeg decoder is much better than that of the ffmpeg decoder compiled with GCC vectorization, and the performance improvement is also greater than that of Intel and AMD platforms.
This article only implements the vectorization transplantation of ffmpeg decoder for Loongson 3B from the code level. In order to further improve the performance, it is necessary to optimize the entire algorithm level. In addition, due to the multi-core characteristics of Loongson 3B, it is also possible to consider using multiple cores for decoding.
Previous article:Design of digitally controlled DC current source system based on microcontroller
Next article:Coding Optimization of CCSDS Image Compression Algorithm Based on Blackfin533
- Popular Resources
- Popular amplifiers
 FFmpeg Getting Started - Audio and Video Principles and Applications (Mei Huidong)
FFmpeg Getting Started - Audio and Video Principles and Applications (Mei Huidong) CVPR 2023 Paper Summary: Video: Low-Level Analysis, Motion, and Tracking
CVPR 2023 Paper Summary: Video: Low-Level Analysis, Motion, and Tracking




- Mir T527 series core board, high-performance vehicle video surveillance, departmental standard all-in-one solution
- Akamai Expands Control Over Media Platforms with New Video Workflow Capabilities
- Tsinghua Unigroup launches the world's first open architecture security chip E450R, which has obtained the National Security Level 2 Certification
- Pickering exhibits a variety of modular signal switches and simulation solutions at the Defense Electronics Show
- Parker Hannifin Launches Service Master COMPACT Measuring Device for Field Monitoring and Diagnostics
- Connection and distance: A new trend in security cameras - Wi-Fi HaLow brings longer transmission distance and lower power consumption
- Smartway made a strong appearance at the 2023 CPSE Expo with a number of blockbuster products
- Dual-wheel drive, Intellifusion launches 12TOPS edge vision SoC
- Toyota receives Japanese administrative guidance due to information leakage case involving 2.41 million pieces of user data






- Innolux's intelligent steer-by-wire solution makes cars smarter and safer
- 8051 MCU - Parity Check
- How to efficiently balance the sensitivity of tactile sensing interfaces
- What should I do if the servo motor shakes? What causes the servo motor to shake quickly?
- 【Brushless Motor】Analysis of three-phase BLDC motor and sharing of two popular development boards
- Midea Industrial Technology's subsidiaries Clou Electronics and Hekang New Energy jointly appeared at the Munich Battery Energy Storage Exhibition and Solar Energy Exhibition
- Guoxin Sichen | Application of ferroelectric memory PB85RS2MC in power battery management, with a capacity of 2M
- Analysis of common faults of frequency converter
- In a head-on competition with Qualcomm, what kind of cockpit products has Intel come up with?
- Dalian Rongke's all-vanadium liquid flow battery energy storage equipment industrialization project has entered the sprint stage before production
- Allegro MicroSystems Introduces Advanced Magnetic and Inductive Position Sensing Solutions at Electronica 2024
- Car key in the left hand, liveness detection radar in the right hand, UWB is imperative for cars!
- After a decade of rapid development, domestic CIS has entered the market
- Aegis Dagger Battery + Thor EM-i Super Hybrid, Geely New Energy has thrown out two "king bombs"
- A brief discussion on functional safety - fault, error, and failure
- In the smart car 2.0 cycle, these core industry chains are facing major opportunities!
- The United States and Japan are developing new batteries. CATL faces challenges? How should China's new energy battery industry respond?
- Murata launches high-precision 6-axis inertial sensor for automobiles
- Ford patents pre-charge alarm to help save costs and respond to emergencies
- New real-time microcontroller system from Texas Instruments enables smarter processing in automotive and industrial applications
- FPGA controls TMS320C6678 power-on reset program
- Lee Kun-hee, chairman of South Korea's Samsung, has passed away. How do you evaluate his life?
- RTT & Renesas high performance CPK-RA6M4 development board review - SPI driven OLED
- 【TGF4042 signal generator】+6th issue pwm modulation
- Free benefits: One-click download of premium sensor data without points required!
- Building a GDB remote debugging environment under TMS320DM8168
- Microwave Engineering
- How does ultra-wideband work?
- Can PCB boards be replaced? Everything you want to know is here!
- 99 out of 100 PCB people will make mistakes in these areas (Part 1)






 京公网安备 11010802033920号
京公网安备 11010802033920号