|
| |
|
|
|
|
|


 提升卡
提升卡 变色卡
变色卡 千斤顶
千斤顶Guess Your Favourite
- 【Posts】Why does TI C6000 need cache?
- 【Posts】TI C6000 DSP McASP port problem
- 【Posts】TI C6000 Teaching Experiment Box Operation Tutorial: 5-8 Histogram Equalization (LCD Display)
- 【Posts】Why does C6000 need Cache?
- 【Posts】TI enters the M0 MCU camp. What is it up to?
- 【Posts】[Analysis of the topic of the college electronic competition]——2022 TI Cup Shanghai C topic "Active two-way audio amplifier circuit"
- 【Posts】A large collection of TI M0 official information, a board online, if you want to review it, please give it a thumbs up
- 【Posts】I took a look at TI's official M0 chip product pictures and found that there are products with Flash ranging from 8KB to 64KB. What applications are they all aimed at?
- 【Download】【TI】OMAP-L138 C6000 DSP+ARM Processor
- 【Download】Introduction: uC/OS-II & lwIP ports for TI C6000 DSP. Very useful!
- 【Download】TI C6000 board support function library is very useful for beginners
- 【Download】Summary of C code optimization for TI DSP c6000 series
- 【Download】The more you control, the more fun it is-TI C2000 LaunchPad development story
- 【Download】2012 TI C2000 and MCU Grand Prix Undergraduate Group_Control System_Xi\'an University of Science and Technology_Intelligent Car Based on MSP430 Series MCU Control.rar
- 【Download】2012 TI C2000 and MCU Grand Prix Intelligent car based on MSP430 series microcontroller control.rar
- 【Download】\"Typical Examples of DSP Embedded Application System Development (C6000)\"
- 【Design】TI launches wireless metering bus M-BUS reference design
- 【Design】ti power adjustable module
- 【Design】XDS110 CMSIS-DAP TI emulator
- 【Design】ti car
- 【Design】TI ultra-low power wireless vibration sensor monitors motor reference design
- 【Design】TI releases space-grade 3-7V input, 24A/0.95V output reference design
- 【Circuits】TI LMZM2360x step-down power module, do you know it?
- 【Circuits】TI TCAN4550 system basic chip analysis
- 【Circuits】Shire YB-5T, YB-5TL, YB-5TI, YR-5M warm water dispenser circuit diagram
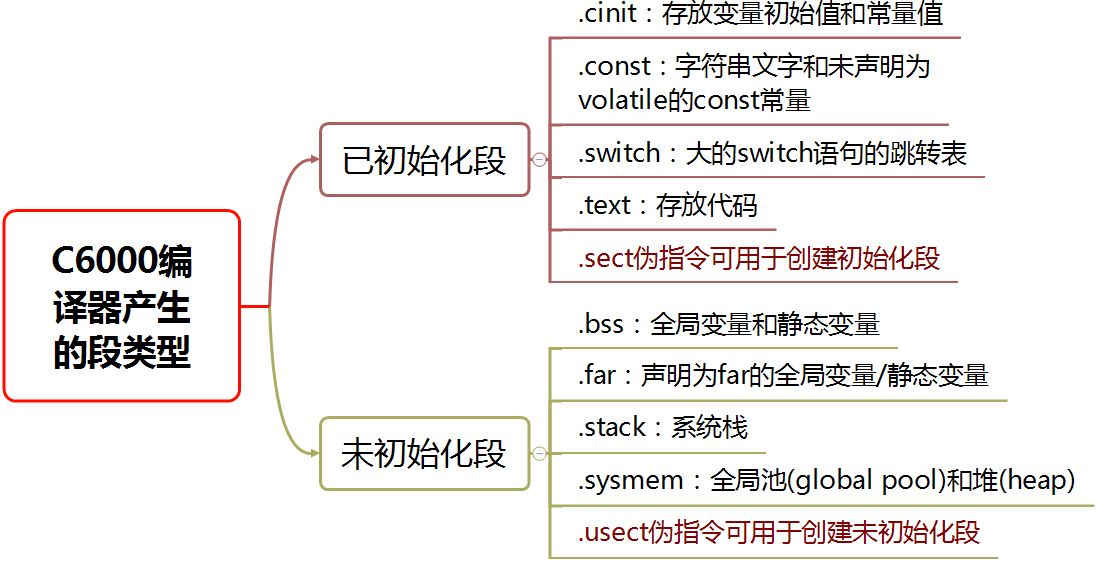
- 【Articles】Design and implementation of multicast network based on C6000 DSP NDK
- 【Articles】Research on Flash Secondary Loading Technology of C6000 Series DSP
- 【Articles】Nvidia explains that the RTX 4060 Ti uses 128-bit video memory: the L2 cache is increased by 16 times, which greatly improves the hit rate.
- 【Articles】News says Nvidia GeForce RTX 4060 Ti and RTX 4060 will be launched in May
- 【Articles】TI announces 2021 revenue, with automotive and industrial accounting for more than 60%, and promises to expand production capacity
- 【Articles】Texas Instruments omap4460 Introduction
Just looking around
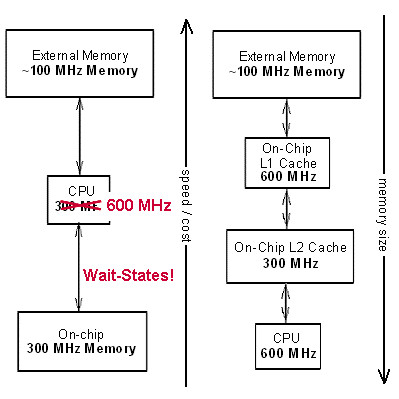
- Why does C6000 need Cache?
- Cache miss categories of the C6000 series
- [Review of "Artificial Intelligence Practical Tutorial"] Python Function
- Help! My newly bought power bank is broken!
- I have a question about the network port circuit?
- Work and classes are suspended, but learning continues! Rohm R Classroom is officially launched online
- RF Technology - The Key to Next-Generation WLAN
- How to design the switching power supply input filter circuit?
- 【BLE 5.3 wireless MCU CH582】6. PWM breathing light
- In these years in the forum
Find a datasheet?
EEWorld Datasheet Technical Support
Hot tag
Related articles more>>
- "Cross-chip" quantum entanglement helps build more powerful quantum computing capabilities
- Ultrasound patch can continuously and noninvasively monitor blood pressure
- Europe's three largest chip giants re-examine their supply chains
- It is reported that Kioxia will be approved for listing as early as tomorrow, and its market value is expected to reach 750 billion yen
- The US government finalizes a $1.5 billion CHIPS Act subsidy to GlobalFoundries to support the latter's expansion of production capacity in the US
- SK Hynix announces mass production of the world's highest 321-layer 1Tb TLC 4D NAND flash memory, plans to ship it in the first half of 2025
- UWB is a new way to use it in cars. Can wireless BMS also use it?
- Filling the domestic gap! China Mobile, Huawei and others jointly released the first GSE DPU chip
- Samsung Electronics NRD-K Semiconductor R&D Complex to import ASML High NA EUV lithography equipment
- Apple reveals the secret of its own chip success: competitors can't use the latest cutting-edge technology
New Posts
- Problems with STM32 and passive buzzer playing sound
- Embedded Tutorial_DSP Technology_DSP Experiment Box Operation Tutorial: 2-28 Building a Lightweight WEB Server Experiment
- OPA847IDBVR op amp domestic replacement
- AG32VF407 Test UART
- [Digi-Key Follow Me Issue 2] Chapter 1: Sharing on receiving the goods
- What model is this infrared receiver? Which model can be used instead? Thank you
- Selling brand new unopened ZYNQ 7Z020 FPGA core board
- The LORA module used in the lithium battery-powered water meter setting can save energy when 100 water meters are installed in one corridor.
- I would like to ask, when a port is set to RX0, is it necessary to set the input and output direction of this port?
- Why is this year so difficult? It’s even more difficult than during the pandemic. I’m 30 and facing unemployment. I’m so confused.
- Ask about the voltage regulator test question
- [Xiaohua HC32F448 Review] About Xiaohua Semiconductor's UART interrupt sending and PRINTF construction and redirection
- 【BIGTREETECH PI development board】 HDMI output test
- 【BIGTREETECH PI development board】+08. Audio test (zmj)
- [Xiaohua HC32F448 Review] +RTC electronic clock
EEWorld
subscription
account

EEWorld
service
account

Automotive
development
circle

About Us Customer Service Contact Information Datasheet Sitemap LatestNews
User Search:
 Room 1530, Zhongguancun MOOC Times Building,
Block B, 18 Zhongguancun Street, Haidian District,
Beijing 100190, China
Tel:(010)82350740
Postcode:100190
Room 1530, Zhongguancun MOOC Times Building,
Block B, 18 Zhongguancun Street, Haidian District,
Beijing 100190, China
Tel:(010)82350740
Postcode:100190
Copyright © 2005-2024 EEWORLD.com.cn, Inc. All rights reserved
京B2-20211791
京ICP备10001474号-1
电信业务审批[2006]字第258号函
 京公网安备 11010802033920号
京公网安备 11010802033920号
京公网安备 11010802033920号
