summary
Semantic occupancy grid perception is crucial for autonomous driving, as autonomous vehicles require fine-grained perception of 3D urban scenes. However, existing benchmarks fall short in terms of the diversity of urban scenes and only evaluate forward-looking prediction perception. To comprehensively evaluate surrounding perception algorithms, we propose OpenOccupancy, the first benchmark for surrounding semantic occupancy grid perception. In the OpenOccupancy benchmark, we extend the large-scale nuScenes dataset by adding dense semantic occupancy grid annotations. Previous annotations rely on the overlay of LiDAR point clouds, which results in some occupancy labels being missed due to the sparsity of LiDAR data. To alleviate this problem, we introduce an augmentation and purification (AAP) pipeline that increases the annotation density by about 2 times, involving about 4,000 man-hours of annotation. In addition, camera-, LiDAR-, and multi-modal baseline models are established for the OpenOccupancy benchmark. Furthermore, considering the complexity of surrounding occupancy perception lies in the computational burden of high-resolution 3D prediction, we propose a cascaded occupancy network (CONet) to improve the coarse prediction, which improves the performance by about 30% relative to the baseline model. We hope that the OpenOccupancy benchmark will promote the development of occupancy-aware algorithms.
Main Contributions
Despite the growing interest in semantic occupancy grid perception, most of the related benchmarks are designed for indoor scenes. SemanticKITTI extends occupancy perception to driving scenes, but its dataset is relatively small in size and limited in diversity, which affects the generalization and evaluation of developed occupancy-aware algorithms. In addition, SemanticKITTI only evaluates occupancy grid results for the front view, while surround perception is more critical for safe driving. To address these issues, we propose OpenOccupancy, the first benchmark for surround semantic occupancy perception. Introduced in the OpenOccupancy benchmark is nuScenes-Occupancy, which combines the large-scale nuScenes dataset with dense semantic occupancy annotations.
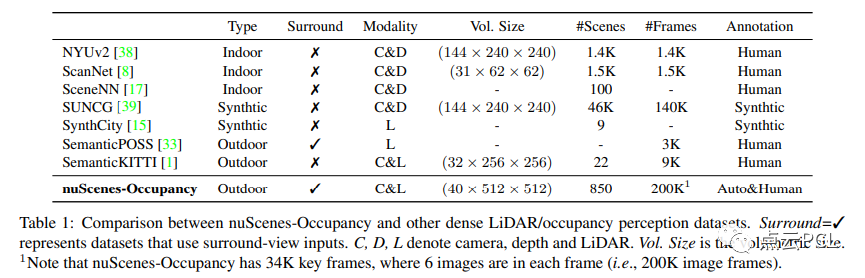
As shown in Table 1, nuScenes-Occupancy annotates about 40 times and 20 times more scenes and frames than nuScenes-Occupancy. It is worth noting that it is almost unrealistic to directly annotate large-scale occupancy labels manually. Therefore, the Augmenting And Purifying (AAP) process is introduced to efficiently annotate and densely label occupancy labels.

Figure 1: nuScenes-Occupancy provides dense semantic occupancy grid labels for all keyframes in the nuScenes dataset, with the annotated ground truth shown here, with a volume size of (40 × 512 × 512) and a grid size of 0.2 meters.
Figure 1 shows the visualization of dense annotations. To facilitate future research, we establish camera-based, LiDAR-based, and multimodal baselines in the OpenOccupancy benchmark. Experimental results show that camera-based methods perform better on small objects (such as bicycles, pedestrians, motorcycles), while LiDAR-based methods perform better on large structured areas (such as driving surfaces, sidewalks). It is worth noting that the multimodal baseline improves the overall performance of camera-based and LiDAR-based methods by 47% and 29% respectively by adaptively fusing the intermediate features of the two modalities. Considering the computational burden of surrounding occupancy perception, the proposed baseline can only generate low-resolution predictions. To achieve efficient occupancy perception, we propose the Cascaded Occupancy Network (CONet), which builds a coarse-to-fine process on top of the proposed baseline, improving the performance by about 30% relative to the original baseline. The main contributions are summarized as follows:
We propose OpenOccupancy, the first benchmark for ambient occupancy awareness in driving scenarios.
The AAP pipeline was introduced through the nuScenes dataset, which efficiently annotates and densifies the surrounding semantic occupancy labels, resulting in the first dataset nuScenes-Occupancy for surrounding semantic occupancy segmentation.
We establish camera-based, LiDAR-based, and multi-modal baselines on the OpenOccupancy benchmark. In addition, we introduce CONet to reduce the computational burden of high-resolution occupancy prediction, improving the baseline performance by about 30% relative to the baseline.
Main content
Perspective semantic occupancy grid perception
Peripheral semantic occupancy perception refers to generating a complete 3D representation of the scene, including volume occupancy and semantic labels. Unlike the monocular paradigm of front view perception, the periphery occupancy perception algorithm aims to generate semantic occupancy in the driving scene of the surrounding view. Specifically, given a 360-degree input Xi (such as a LiDAR scan or a surrounding view image), the perception algorithm needs to predict the surrounding occupancy label F(Xi) ∈ RD×H×W, where D, H, W are the volume sizes of the entire scene. It is worth noting that the input range of the periphery view is about 5 times larger than the range covered by the front vision sensor. Therefore, the core challenge of periphery occupancy grid perception is to efficiently build a high-resolution occupancy representation.
nuScenes-Occupancy
SemanticKITTI is the first dataset for outdoor occupancy perception, but it lacks diversity in driving scenarios and only evaluates forward perception. In order to create a large-scale environmental occupancy perception dataset, we introduced nuScenes-Occupancy, which adds dense semantic occupancy annotations on the basis of the nuScenes dataset. The authors introduced the AAP (Augmenting And Purifying) process to efficiently annotate and densify occupancy labels.
The entire AAP process is shown in Algorithm 1.

As shown in Figure 2, the pseudo-labels are complementary to the initial annotations, while the enhanced and purified labels are denser and more accurate. It is worth noting that there are about 400,000 occupied voxels in each frame in the enhanced and purified annotations, which is about 2 times denser than the initial annotations. In summary, nuScenes-Occupancy contains 28,130 training frames and 6,019 validation frames, with 17 semantic labels assigned to the occupied voxels in each frame.

Figure 2: Comparison between the original annotation, pseudo-annotation, and enhanced purified annotation. The red and blue circles highlight areas where the enhanced annotation is more dense and accurate.
OpenOccupancy Baseline
Most existing occupancy perception methods are designed for forward-looking perception. To extend these methods to surrounding occupancy perception, the input from each camera view needs to be processed separately, which is inefficient. In addition, there may be inconsistencies in the overlapping area of two adjacent outputs. To alleviate these problems, we establish baselines that consistently learn surrounding semantic occupancy from 360-degree inputs (such as LiDAR scans or surround images). Specifically, we propose camera-based, LiDAR-based, and multimodal baselines for the OpenOccupancy benchmark, as shown in Figure 3.

Figure 3: The overall architecture of the three proposed baselines. The LiDAR branch uses a 3D encoder to extract voxelized LiDAR features. The camera branch uses a 2D encoder to learn surround view features, which are then converted to generate 3D camera voxel features. In the multimodal branch, the adaptive fusion module dynamically integrates the features of the two modalities. All three branches use a 3D decoder and an occupancy head to produce semantic occupancy. In the occupancy result map, the red and purple circles indicate that the multimodal branch can generate more complete and accurate predictions.
experiment
In the OpenOccupancy benchmark, the surrounding semantic occupancy perception performance is evaluated based on nuScenes-Occupancy, and comprehensive experiments are conducted on the proposed baseline, CONet, and modern occupancy perception algorithms. All models are trained on 8 A100 GPUs with a batch size of 8 for a total of 24 epochs. Using the OpenOccupancy benchmark, we analyzed the surrounding occupancy perception performance of six modern methods (MonoScene, TPVFormer, 3DSketch, AICNet, LMSCNet, JS3C-Net) as well as the proposed baseline and CONet. From the results in Table 2, we can see that:
The surrounding occupancy awareness paradigm shows better performance compared to single-view methods.
The proposed baseline is adaptable and scalable for ambient occupancy awareness.
The information from camera and LiDAR complements each other and the multimodal baseline significantly improves the performance.
The complexity of periscopic occupancy perception lies in the computational burden of high-resolution 3D prediction, which can be alleviated by the proposed CONet.

Visual results are provided here (see Figure 5) to verify that CONet can generate fine occupancy grid results based on coarse predictions.

Figure 5: Visualization of semantic occupancy predictions, row 1 is the periscopic image. Rows 2 and 3 show the coarse and fine occupancy of the camera views generated by the multimodal baseline and multimodal CONet, and row 4 compares their global view predictions.
Summarize
In this paper, we present OpenOccupancy, the first benchmark for semantic occupancy awareness in driving scenarios. Specifically, we introduce nuScenes-Occupancy, which extends the nuScenes dataset with dense semantic occupancy annotations based on the proposed AAP pipeline. We establish camera-based, LiDAR-based, and multimodal baselines on the OpenOccupancy benchmark. In addition, we propose CONet to reduce the computational burden of high-resolution occupancy prediction. Comprehensive experiments are conducted on the OpenOccupancy benchmark and show that the camera-based and LiDAR-based baselines complement each other, while the multimodal baseline further improves the performance by 47% and 29%, respectively. In addition, the proposed CONet improves by about 30% over the baselines with minimal latency overhead. We hope that the OpenOccupancy benchmark will help the development of semantic occupancy awareness in driving scenarios.


Previous article:Analysis of 800v fast charging technology for new energy vehicles
Next article:For 800V platform models, why is the battery pack voltage less than 800V?
- Popular Resources
- Popular amplifiers
 5962R9679801QXA
5962R9679801QXA- How Lucid is overtaking Tesla with smaller motors
- Detailed explanation of intelligent car body perception system
- How to solve the problem that the servo drive is not enabled
- Why does the servo drive not power on?
- What point should I connect to when the servo is turned on?
- How to turn on the internal enable of Panasonic servo drive?
- What is the rigidity setting of Panasonic servo drive?
- How to change the inertia ratio of Panasonic servo drive
- What is the inertia ratio of the servo motor?
 Professor at Beihang University, dedicated to promoting microcontrollers and embedded systems for over 20 years.
Professor at Beihang University, dedicated to promoting microcontrollers and embedded systems for over 20 years.






- LED chemical incompatibility test to see which chemicals LEDs can be used with
- Application of ARM9 hardware coprocessor on WinCE embedded motherboard
- What are the key points for selecting rotor flowmeter?
- LM317 high power charger circuit
- A brief analysis of Embest's application and development of embedded medical devices
- Single-phase RC protection circuit
- stm32 PVD programmable voltage monitor
- Introduction and measurement of edge trigger and level trigger of 51 single chip microcomputer
- Improved design of Linux system software shell protection technology
- What to do if the ABB robot protection device stops
- How Lucid is overtaking Tesla with smaller motors
- Wi-Fi 8 specification is on the way: 2.4/5/6GHz triple-band operation
- Wi-Fi 8 specification is on the way: 2.4/5/6GHz triple-band operation
- Vietnam's chip packaging and testing business is growing, and supply-side fragmentation is splitting the market
- Vietnam's chip packaging and testing business is growing, and supply-side fragmentation is splitting the market
- Three steps to govern hybrid multicloud environments
- Three steps to govern hybrid multicloud environments
- Microchip Accelerates Real-Time Edge AI Deployment with NVIDIA Holoscan Platform
- Microchip Accelerates Real-Time Edge AI Deployment with NVIDIA Holoscan Platform
- Melexis launches ultra-low power automotive contactless micro-power switch chip
- iTOP3399 development board Android application development environment construction - installation of AndroidStudio (I)
- From acquiring ThreadX to making ThreadX open source, where will Microsoft go next? And how will other RTOS companies respond?
- Intelligent RV control system
- 360° Lid Detection using LSM6DSO
- WIFI6 Explained
- 【NXP Rapid IoT Review】 + Kit Modification-External Lithium Battery (Link)
- How to design a typical analog front-end circuit
- [Fudan Micro FM33LG0 Series Development Board Review] Driving RGB TFT Display
- Thank you for being there + thank you for everyone who appears in my life
- Use NucleiStudio to import GD32VF103_Demo_Suites routine






 京公网安备 11010802033920号
京公网安备 11010802033920号