#01 Initial BEV
As an important part of high-level assisted driving products, vehicle perception is a system that uses data from a variety of sensors and information from high-precision maps as input. After a series of calculations and processing, it accurately perceives the surrounding environment. Its function is equivalent to that of a human. Eye. Its perceptual recognition task is essentially a 3D geometric reconstruction of the physical world, so that the computer can "recognize" entities and elements in the physical world.

The traditional perception method for autonomous driving algorithms is to perform detection, segmentation, tracking, etc. in front view or perspective view. The core of the previously popular 2D perception is to identify and distinguish target objects from a single image or a continuous image sequence. Although this traditional visual perception technology has achieved significant progress over the past decade thanks to deep learning and large-scale data sets, it is also one of the key factors in the rapid progress in the field of autonomous driving. But for the specific needs of autonomous driving, relying solely on 2D perception is not enough. In fact, in order to support downstream tasks such as vehicle positioning, trajectory prediction, and motion planning, the information obtained from 2D perception must be transformed into a three-dimensional space framework. At the same time, as the number of sensors on vehicles becomes more and more complex, and the installation locations, viewing angles and data formats are different, it is necessary to integrate the multi-source information from different sensors from a unified perspective. Representing features in a unified view becomes critical.
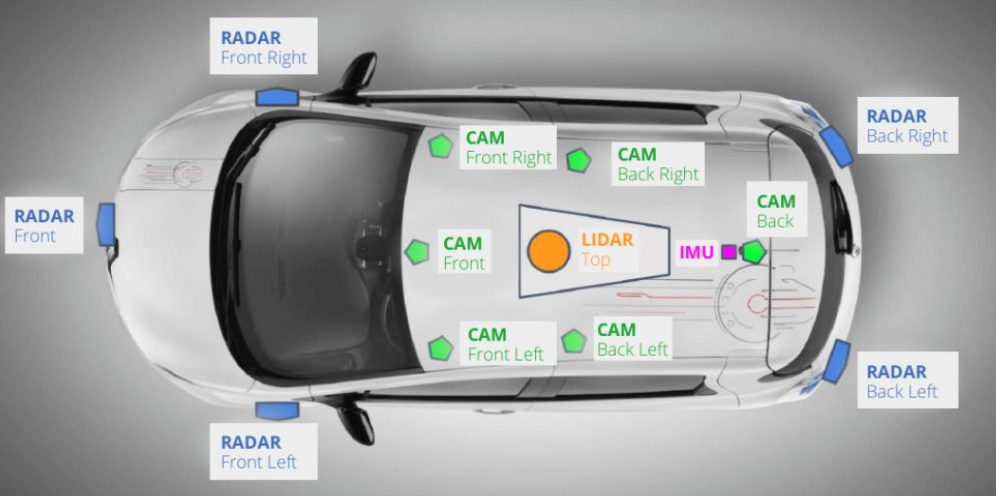
Therefore, although 2D visual perception itself has become increasingly mature, how to effectively solve the problem of conversion from 2D to 3D space is still a major challenge in autonomous driving application scenarios.
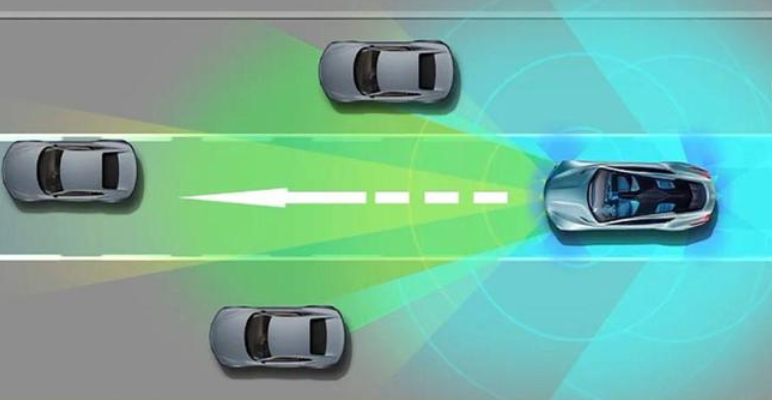
The full English name of BEV is Bird's-Eye-View, which is a vivid expression used to describe the perspective obtained when overlooking the ground from a high altitude, just like a bird flying in the air and looking down. sights that can be seen. In map production, a bird's-eye view is a special form of map representation. It simulates the effect of viewing the earth's surface vertically from directly above, and can clearly display the spatial relationships between geographical elements such as terrain, buildings, and road networks. and layout. This view is crucial for autonomous vehicles because it simplifies the perception and understanding of the surrounding environment.
Compared with front view or perspective view, which have been widely studied in the field of 2D vision, BEV has several advantages:
(1) There are no occlusion or scaling issues common in 2D perception. Identifying vehicles with occlusions or crossings can be better addressed.
(2) Representing objects or road elements in this form facilitates the development and deployment of subsequent modules (such as planning, control).
(3) Global vision and unified coordinate frame. BEV can provide a larger panoramic view around the vehicle, which is not limited by the line of sight of a single sensor. It is especially important for scenes such as complex intersections, intersections, and traffic jams. Converting data from different sensors (such as cameras, radars, LiDAR) into the same BEV coordinate system allows all sensory information to be fused and processed in a standardized space, enhancing the consistency and reliability of the information.
(4) Multi-tasking and parallelization. In the BEV view, multiple perception tasks can be performed more efficiently in parallel, such as obstacle detection, lane line detection, drivable area estimation, etc., reducing the interdependence between different tasks.
(5) Reduce hardware costs and dependencies. Although BEV perception usually involves multi-sensor fusion, it also promotes BEV perception research based on pure vision solutions to achieve low-cost 3D perception through visual sensors and reduce dependence on LiDAR equipment.
#02 How BEV works
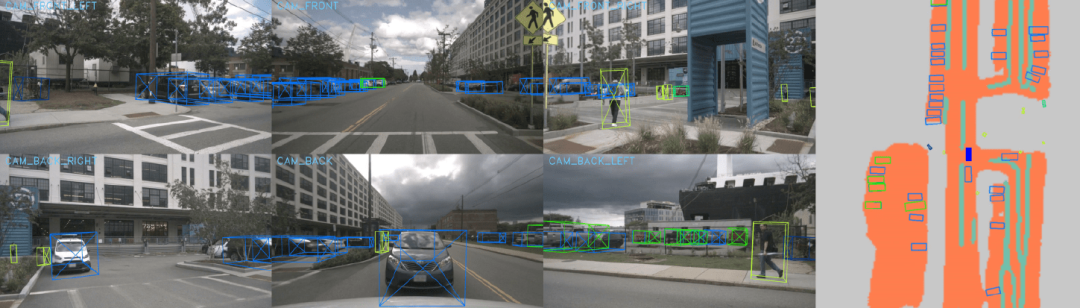
Here’s roughly how BEV sensing works:
(1) Sensor data acquisition. First, various sensors mounted on autonomous vehicles collect real-time data, including but not limited to RGB images from cameras, depth images, or point cloud data from lidar.
(2) Sensor data preprocessing. Perform necessary preprocessing on the data of each sensor, such as correcting distortion, filtering, removing noise, etc.
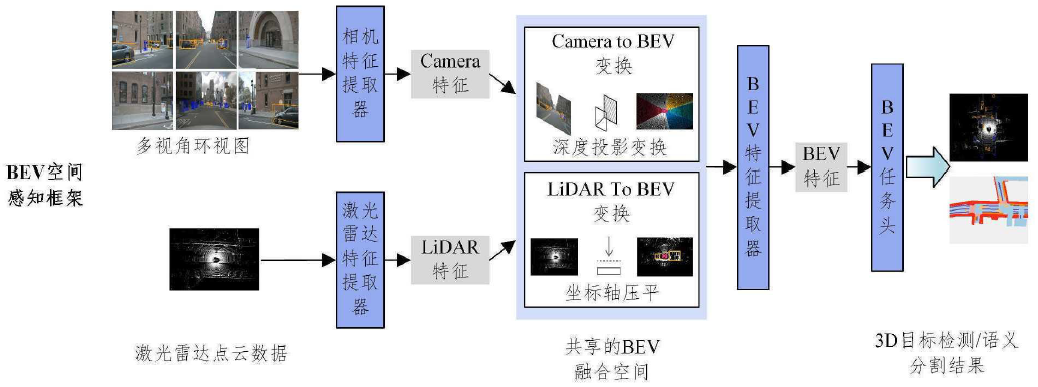
(3) BEV perspective conversion. Perspective conversion is a key step in converting data from different sensors (especially perspective view images taken by cameras) into a bird's-eye view from above. The process involves extracting depth information from 2D images or other 3D data forms (such as laser point clouds) and reconstructing the 3D spatial layout around a vehicle.
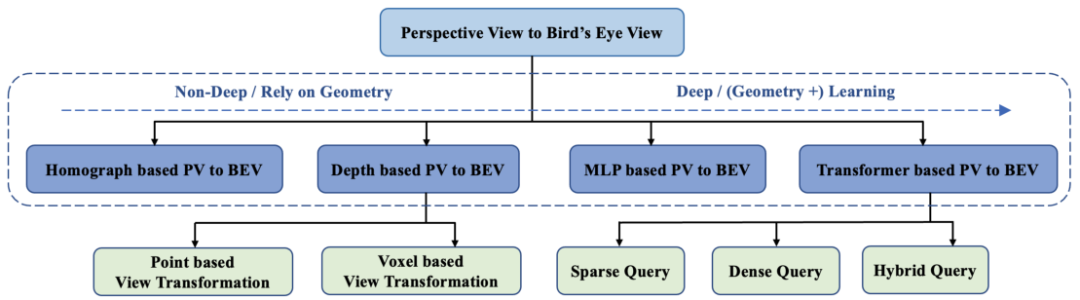
Current research work can be divided into two categories based on perspective transformation: geometric transformation and network-based transformation. The former exploits the physical geometry of the camera to transform views in an interpretable way. The latter uses a neural network to project the perspective view (PV) onto the BEV.

Methods based on geometric transformation:
Monocular vision: Since a monocular camera cannot directly provide depth information, a deep learning model is usually required to estimate the depth of each pixel. Once the depth value of each point in the image is obtained, the internal parameters of the camera (focal length, principal point coordinates, etc.) and the external parameters (the position and attitude of the camera relative to the vehicle) can be combined to perform a three-dimensional spatial geometric transformation (such as perspective projection transformation) Map image pixels into BEV space.
Binocular stereo vision: Use the baseline relationship between the two cameras to calculate the disparity to obtain depth information, which is also mapped to BEV through geometric transformation.
Multi-eye vision: Data from multiple cameras can be combined to improve depth estimation accuracy and further enhance the reconstruction effect of BEV space.
Projection transformation based on deep learning:
Direct learning projection transformation: Use neural networks to directly learn the nonlinear mapping function from perspective images to BEV space. This mapping is usually trained end-to-end and can directly output feature maps in BEV space from the input image.
Convolutional neural network and back-projection: Features are extracted from the image through CNN, combined with the depth information provided by the depth estimation network, and the back-projection operation is used to project the feature points with depth information into the BEV space.
Point cloud data processing:
LiDAR point cloud: The point cloud data collected by LiDAR is already in three-dimensional form, and the point cloud data can be directly converted to the BEV view in the vehicle coordinate system through coordinate transformation (rotation and translation). This is usually simple and precise, but involves a lot of handling of data sparsity and irregularities.
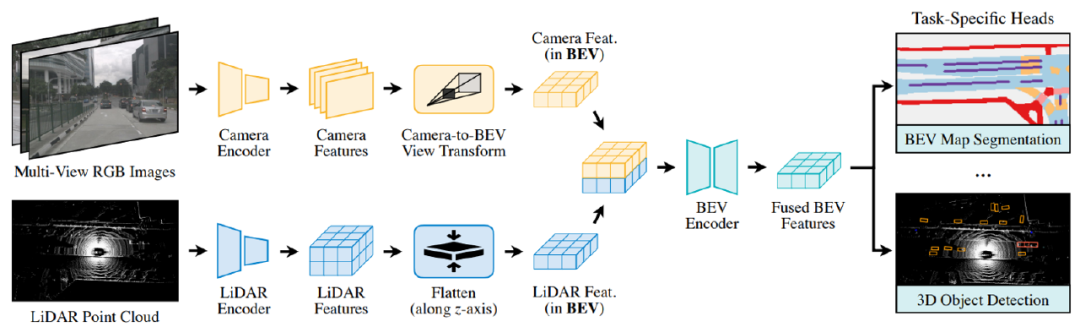
(5) Multi-modal data fusion. The BEV perspective data obtained by each sensor are fused and integrated to form a comprehensive and accurate representation of the surrounding environment. By combining the complementary advantages of different sensors, such as radar’s ability to detect non-visual conditions, cameras’ ability to recognize colors and textures, and lidar’s ability to accurately measure distances. Various sensors first perform preliminary processing separately to extract their own feature information (such as visual features of camera images, geometric features of point clouds), and then deeply fuse these features. In BEV perception, it may include combining object bounding boxes detected from images with three-dimensional geometric information in point clouds to generate more accurate BEV scene representations.
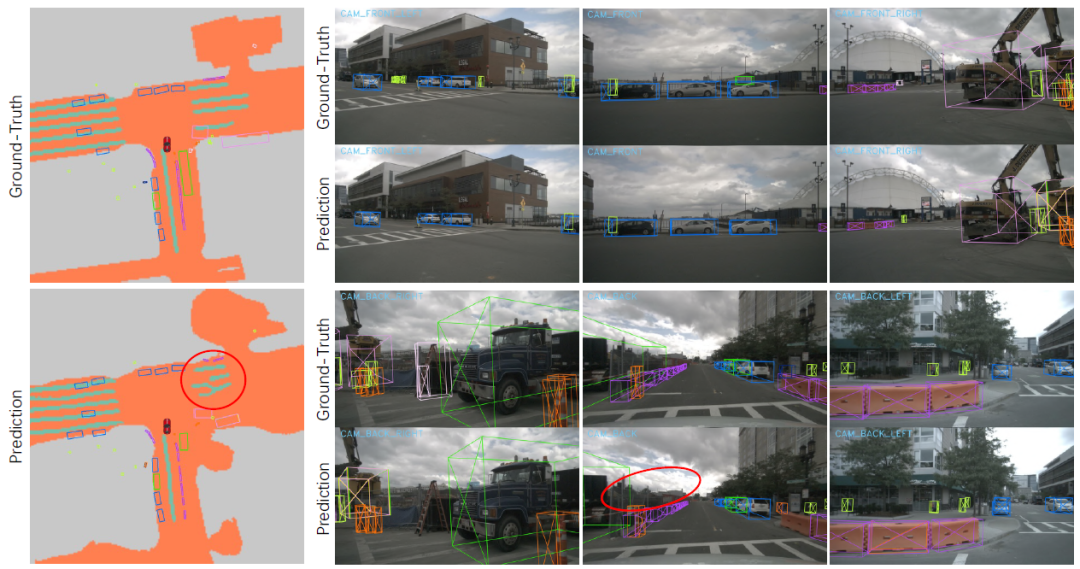
(6) Feature extraction and modeling. From the perspective of BEV, deep learning models (such as Transformer or CNN, etc.) are used to extract and construct environmental feature maps, which are used to identify and track key elements such as road surfaces, vehicles, pedestrians, and traffic signs.
(7) Perceive task execution. On the constructed BEV feature map, a series of perception tasks can be performed, such as target detection, classification, trajectory prediction, etc., so that the autonomous driving system can understand the status of the surrounding environment and make decisions accordingly.
(8) End-to-end optimization. The latest BEV perception technology, such as LSS (Lift, Splat, Shoot) or BEVFormer, etc., realizes end-to-end training, which can directly input from the original sensor to the generation of BEV features, while simultaneously learning and optimizing the perception task, improving the entire system. efficiency and performance.
#03 BEV’s solution
BEV (Bird's-Eye-View) aware solutions are divided into the following categories according to different input data types and processing methods: (1) Visual BEV (Visual BEV) Visual BEV mainly reconstructs the BEV space based on camera image data. This type of method mainly uses 2D perspective images captured by a single or multi-camera camera, performs depth estimation through deep learning technology, and then combines the camera parameters to project the image information into the BEV space. Representative works such as BEVDepth, Mono3D, etc. Some of the latest technologies such as BEVFormer start directly from the original image input and learn feature representations mapped to the BEV space through neural networks to achieve target detection and scene understanding. (2) Laser point cloud BEV (LiDAR BEV) Laser point cloud BEV is based on 3D point cloud data collected by LiDAR (lidar). Since LiDAR itself provides direct three-dimensional spatial information, converting point cloud data to a BEV perspective is relatively straightforward. After preprocessing the point cloud such as downsampling, clustering, and segmentation, the point cloud data can be easily projected into the BEV space for 3D target detection and scene analysis. This type of method is characterized by its ability to fully exploit the precise geometric properties of point cloud data in BEV space. 



Previous article:An article explaining in detail the in-cabin sensing technology of smart cockpits
Next article:Huawei explains lidar in detail
- Popular Resources
- Popular amplifiers
 LM161J-SMD
LM161J-SMD- Car key in the left hand, liveness detection radar in the right hand, UWB is imperative for cars!
- After a decade of rapid development, domestic CIS has entered the market
- Aegis Dagger Battery + Thor EM-i Super Hybrid, Geely New Energy has thrown out two "king bombs"
- A brief discussion on functional safety - fault, error, and failure
- In the smart car 2.0 cycle, these core industry chains are facing major opportunities!
- The United States and Japan are developing new batteries. CATL faces challenges? How should China's new energy battery industry respond?
- Murata launches high-precision 6-axis inertial sensor for automobiles
- Ford patents pre-charge alarm to help save costs and respond to emergencies
- New real-time microcontroller system from Texas Instruments enables smarter processing in automotive and industrial applications






- Innolux's intelligent steer-by-wire solution makes cars smarter and safer
- 8051 MCU - Parity Check
- How to efficiently balance the sensitivity of tactile sensing interfaces
- What should I do if the servo motor shakes? What causes the servo motor to shake quickly?
- 【Brushless Motor】Analysis of three-phase BLDC motor and sharing of two popular development boards
- Midea Industrial Technology's subsidiaries Clou Electronics and Hekang New Energy jointly appeared at the Munich Battery Energy Storage Exhibition and Solar Energy Exhibition
- Guoxin Sichen | Application of ferroelectric memory PB85RS2MC in power battery management, with a capacity of 2M
- Analysis of common faults of frequency converter
- In a head-on competition with Qualcomm, what kind of cockpit products has Intel come up with?
- Dalian Rongke's all-vanadium liquid flow battery energy storage equipment industrialization project has entered the sprint stage before production
- Allegro MicroSystems Introduces Advanced Magnetic and Inductive Position Sensing Solutions at Electronica 2024
- Car key in the left hand, liveness detection radar in the right hand, UWB is imperative for cars!
- After a decade of rapid development, domestic CIS has entered the market
- Aegis Dagger Battery + Thor EM-i Super Hybrid, Geely New Energy has thrown out two "king bombs"
- A brief discussion on functional safety - fault, error, and failure
- In the smart car 2.0 cycle, these core industry chains are facing major opportunities!
- The United States and Japan are developing new batteries. CATL faces challenges? How should China's new energy battery industry respond?
- Murata launches high-precision 6-axis inertial sensor for automobiles
- Ford patents pre-charge alarm to help save costs and respond to emergencies
- New real-time microcontroller system from Texas Instruments enables smarter processing in automotive and industrial applications
- How is your circuit preparation going?
- How to use wireless firmware upgrades for MSP 430 microcontrollers
- MicroPython adds support for STM32L432KC
- Several countermeasures to suppress electromagnetic interference of power modules
- Theory and Application of DAC12 Module of MSP430 Microcontroller
- CC1310 switching rate method
- EEWORLD University - Inverter Principle
- Bluetooth and MSP430 Audio Sink Reference Design
- Apprentice
- 【ST NUCLEO-G071RB Review】TIM-Basic timers






 京公网安备 11010802033920号
京公网安备 11010802033920号