The four commonly used FPGA/CPLD design ideas and techniques discussed in this article: ping-pong operation, serial-to-parallel conversion, pipeline operation, and data interface synchronization are all manifestations of the inherent laws of FPGA/CPLD logic design. Reasonable use of these design ideas can FPGA/CPLD design work achieves twice the result with half the effort.
FPGA/CPLD design ideas and techniques are a very big topic. Due to space limitations, this article only introduces some commonly used design ideas and techniques, including table tennis operations, serial-to-parallel conversion, pipeline operations and data interface synchronization methods. I hope this article will attract the attention of engineers. If these principles can be consciously used to guide future design work, we will achieve twice the result with half the effort!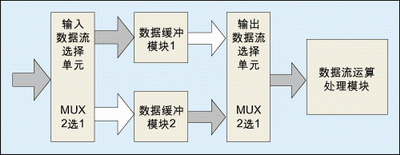
Ping pong operation
"Ping-pong operation" is a processing technique often used in data flow control. The typical ping-pong operation method is shown in Figure 1.
The processing flow of the ping-pong operation is: the input data stream is isochronously distributed to two data buffers through the "input data selection unit". The data buffer module can be any storage module, and the more commonly used storage unit is dual-port RAM (DPRAM). ), single-port RAM (SPRAM), FIFO, etc. In the first buffering cycle, the input data stream is cached to "data buffer module 1"; in the second buffering cycle, through the switching of the "input data selection unit", the input data stream is cached to "data buffer module 2" ", and at the same time, the first cycle data cached by "Data Buffer Module 1" is selected by the "Input Data Selection Unit" and sent to the "Data Flow Operation Processing Module" for calculation processing; in the third buffer cycle, the data is sent through the "Input Data Selection Unit" Select unit" is switched again to cache the input data stream to "data buffer module 1". At the same time, the data of the second cycle buffered by "data buffer module 2" is switched through the "input data selection unit" and sent to "data buffer module 1". Stream operation processing module" performs operation processing. And so on.
The biggest feature of the ping-pong operation is that through the switching of the "input data selection unit" and the "output data selection unit" according to rhythm and mutual coordination, the buffered data stream is sent to the "data stream operation processing module" without pause for calculation and processing. . Treat the ping-pong operation module as a whole and look at the data from both ends of the module. The input data stream and the output data stream are continuous without any pauses, so it is very suitable for pipeline processing of the data stream. Therefore, ping-pong operations are often used in pipeline algorithms to complete seamless buffering and processing of data.
The second advantage of ping-pong operation is that it can save buffer space. For example, in WCDMA baseband applications, a frame is composed of 15 time slots. Sometimes it is necessary to delay the data of a whole frame by one time slot for post-processing. A more direct method is to cache the data of this frame and then delay it. 1 time slot for processing. At this time, the length of the buffer is 1 whole frame of data. Assuming that the data rate is 3.84Mbps and 1 frame is 10ms long, the buffer length required at this time is 38400 bits. If you use ping-pong operation, you only need to define two RAMs that can buffer 1 time slot data (single-port RAM is enough). When writing data to one RAM, the data is read from another RAM and then sent to the processing unit for processing. At this time, the capacity of each RAM is only 2560 bits, and the total capacity of the two RAMs is only 5120 bits. 
Figure 2: Dual-port RAM is used, and a first-level data preprocessing module is introduced after DPRAM to process high-speed data streams with low-speed modules.
In addition, clever use of ping-pong operations can also achieve the effect of using low-speed modules to process high-speed data streams. As shown in Figure 2, the data buffer module uses dual-port RAM, and introduces a first-level data preprocessing module after the DPRAM. This data preprocessing can perform various data operations according to the needs. For example, in WCDMA design, the input data Despreading, descrambling, derotating, etc. of streams. Assume that the input data flow rate of port A is 100Mbps, and the buffering period of the ping-pong operation is 10ms. The following analyzes the data rate of each node port.
The input data flow rate at port A is 100Mbps. Within 10ms of the first buffering period, it reaches DPRAM1 from B1 through the "input data selection unit". The data rate of B1 is also 100Mbps, and DPRAM1 needs to write 1Mb of data in 10ms. Similarly, in the second 10ms, the data stream is switched to DPRAM2, the data rate of port B2 is also 100Mbps, and 1Mb data is written to DPRAM2 in the second 10ms. In the third 10ms, the data stream switches to DPRAM1 again, and 1Mb data is written into DPRAM1.
Careful analysis will reveal that by the third buffering cycle, the total time left for DPRAM1 to read data and send it to "data preprocessing module 1" is 20ms. Some engineers are confused about why the reading time of DPRAM1 is 20ms. This time is obtained as follows: first, within 10ms of writing data to DPRAM2 in the second buffer cycle, DPRAM1 can perform read operations; in addition, during the first buffer cycle Starting from the 5ms of the buffering period (the absolute time is 5ms), DPRAM1 can write data to addresses after 500K while reading from address 0. When 10ms is reached, DPRAM1 has just finished writing 1Mb of data and has read 500K of data. This DPRAM1 read for 5ms during the buffering time; starting from the 5ms of the third buffering period (the absolute time is 35ms), in the same way, you can write data to addresses after 500K while reading from address 0, and read for another 5ms. , so until the data stored in DPRAM1 in the first cycle is completely overwritten, DPRAM1 can read up to 20ms, and the data required to be read is 1Mb, so the data rate of port C1 is: 1Mb/20ms=50Mbps. Therefore, the minimum data throughput capability of "data preprocessing module 1" is only required to be 50Mbps. Similarly, the minimum data throughput capability of "data preprocessing module 2" is only required to be 50Mbps. In other words, through the ping-pong operation, the timing pressure of the "data preprocessing module" is reduced, and the required data processing rate is only 1/2 of the input data rate.
The essence of realizing low-speed module to process high-speed data through ping-pong operation is that the serial-to-parallel conversion of the data stream is realized through a cache unit such as DPRAM, and the shunted data is processed in parallel using "data preprocessing module 1" and "data preprocessing module 2". It is the embodiment of the interchange principle of area and speed!
Design skills for serial-to-parallel conversion
Serial-to-parallel conversion is an important skill in FPGA design. It is a common method for data flow processing and is also a direct embodiment of the idea of area and speed interchange. There are many ways to implement serial-to-parallel conversion. According to the data sorting and quantity requirements, registers, RAM, etc. can be used to implement it. In the previous illustration of the ping-pong operation, the serial-to-parallel conversion of the data stream is realized through DPRAM, and due to the use of DPRAM, the data buffer can be opened very large. For designs with relatively small quantities, registers can be used to complete the serial-to-parallel conversion. If there are no special requirements, synchronous timing design should be used to complete the conversion between serial and parallel. For example, when data goes from serial to parallel, the order of data arrangement is high-end first, which can be achieved with the following coding: 
Figure 3: Structural diagram of pipeline design
prl_temp<={prl_temp,srl_in};
Among them, prl_temp is the parallel output buffer register, and srl_in is the serial data input.
For serial-to-parallel conversion with specified arrangement order, you can use case statements to judge and implement it. For complex serial-to-parallel conversion, it can also be implemented using a state machine. The method of serial-to-parallel conversion is relatively simple and there is no need to go into details here.
Pipeline operation design ideas
First of all, it needs to be stated that the pipeline described here refers to a design idea of processing flow and sequential operations, not the "Pipelining" used to optimize timing in FPGA and ASIC design.
Pipeline processing is a common design method in high-speed design. If the processing flow of a certain design is divided into several steps, and the entire data processing is "single flow", that is, there is no feedback or iterative operation, and the output of the previous step is the input of the next step, you can consider using the pipeline design method. Increase the operating frequency of the system.
The structural diagram of the pipeline design is shown in Figure 3. Its basic structure is as follows: n appropriately divided operation steps are connected in series. The biggest feature and requirement of pipeline operation is that the processing of data flow in each step is continuous in time. If each operation step is simplified and assumed to pass through a D flip-flop (that is, using a register to make a beat), then pipeline operation Just like a shift register bank, the data flow flows through the D flip-flop in sequence to complete the operation of each step. The pipeline design timing is shown in Figure 4.
A key to pipeline design lies in the reasonable arrangement of the entire design sequence, which requires reasonable division of each operation step. If the operation time of the front stage is exactly equal to the operation time of the rear stage, the design is the simplest. The output of the front stage can be directly imported into the input of the rear stage. If the operation time of the front stage is greater than the operation time of the rear stage, the output of the front stage needs to be adjusted. Only when the data is properly cached can it be imported to the input end of the subsequent stage; if the operation time of the front stage happens to be shorter than the operation time of the subsequent stage, the data flow must be shunted through copy logic, or the data must be stored and post-processed in the front stage, otherwise Will cause subsequent data overflow.
Pipeline processing methods are often used in WCDMA design, such as RAKE receivers, searchers, preamble capture, etc. The reason why the pipeline processing method has a higher frequency is that the processing module is copied, which is another concrete embodiment of the idea of exchanging area for speed.
Synchronization method of data interface
Synchronization of data interfaces is a common problem in FPGA/CPLD design, and it is also a key and difficult point. Many design instability is caused by problems with synchronization of data interfaces.
In the circuit diagram design stage, some engineers manually add BUFT or NOT gates to adjust the data delay, thereby ensuring the establishment and hold time requirements of the clock of the current-level module for the data of the upper-level module. In order to have stable sampling, some engineers generate a lot of clock signals that are 90 degrees different. Sometimes they use a positive edge to hit the data, and sometimes they use a negative edge to hit the data to adjust the sampling position of the data. Both of these approaches are highly undesirable, because once the chip is updated or transplanted to a chip from another chipset, the sampling implementation must be redesigned. Moreover, these two approaches result in insufficient margin for circuit implementation. Once external conditions change (such as temperature rise), the sampling timing may be completely disrupted, causing circuit paralysis.
The following is a brief introduction to several synchronization methods of data interfaces in different situations:
1. How to complete data synchronization under conditions where input and output delays (delays between chips, PCB wiring, some driver interface components, etc.) are unpredictable or may change?
For unpredictable or variable data delays, a synchronization mechanism needs to be established, and a synchronization enable or synchronization indication signal can be used. In addition, the purpose of data synchronization can also be achieved by accessing data through RAM or FIFO. 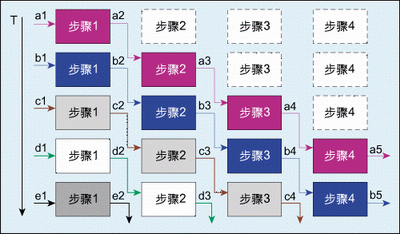
Figure 4: Pipeline design timing diagram.
The method of storing data in RAM or FIFO is as follows: use the data accompanying clock provided by the upper-level chip as a write signal, write the data into RAM or FIFO, and then use the sampling clock of this level (usually the main clock of data processing) to write the data Just read it out. The key to this approach is that the data written into RAM or FIFO must be reliable. If synchronous RAM or FIFO is used, it is required that there should be an accompanying indication signal with a fixed relative delay relationship with the data. This signal can be a valid indication of the data, or it can It is the clock used by the upper-level module to print out the data. For slow data, it is also possible to sample asynchronous RAM or FIFO, but this approach is not recommended.
The data is arranged in a fixed format, and a lot of important information is at the beginning of the data. This situation is very common in communication systems. In communication systems, a lot of data is organized according to "frames". Since the entire system has high clock requirements, a clock board is often specially designed to generate and drive high-precision clocks. And the data has a starting position. How to complete the synchronization of the data and find the "head" of the data?
The data synchronization method can completely adopt the above method, use the synchronization indicator signal, or use RAM or FIFO to cache. There are two ways to find the data header. The first one is very simple, just transmit an indication signal of the starting position of the data along the way. For some systems, especially asynchronous systems, a synchronization code is often inserted into the data (such as training sequence), the receiving end can discover the "head" of the data after detecting the synchronization code through the state machine. This approach is called "blind detection".
The upper-level data and the current-level clock are asynchronous, which means that the clocks of the upper-level chip or module and the current-level chip or module are in asynchronous clock domains.
A principle has been briefly introduced before in the input data synchronization: if the beat of the input data is at the same frequency as the processing clock of the chip at this level, the main clock of the chip at this level can be directly used to sample the input data register to complete the synchronization of the input data. ; If the input data and the processing clock of this level chip are asynchronous, especially when the frequency does not match, the input data can only be synchronized by sampling the input data twice with the processing clock. It should be noted that the use of registers to sample the data in the asynchronous clock domain twice is to effectively prevent the propagation of metastable states (unstable data states), so that the data processed by the subsequent circuits are all valid levels. However, this approach does not guarantee that the data sampled by the two-level register is of the correct level. This method of processing generally produces a certain amount of erroneous level data. So it is only suitable for functional units that are not sensitive to a small number of errors.
In order to avoid erroneous sampling levels in the asynchronous clock domain, RAM and FIFO cache methods are generally used to complete data conversion in the asynchronous clock domain. The most commonly used cache unit is DPRAM. The upper-level clock is used at the input port to write data, and the current-level clock is used at the output port to read data. This makes it very convenient to complete data exchange between asynchronous clock domains.
2. Is it necessary to add constraints when designing data interface synchronization?
It is recommended to add appropriate constraints, especially for high-speed designs. Be sure to add corresponding constraints on cycle, setup, hold time, etc.
The role of additional constraints here is twofold:
a. Increase the working frequency of the design to meet the interface data synchronization requirements. By adding constraints such as cycle time, setup time, and hold time, the synthesis, mapping, layout, and wiring of logic can be controlled to reduce logic and wiring delays, thereby increasing the operating frequency and meeting interface data synchronization requirements.
b. Obtain the correct timing analysis report. Almost all FPGA design platforms include static timing analysis tools, which can be used to obtain timing analysis reports after mapping or placement and routing, so as to evaluate the performance of the design. Static timing analysis tools use constraints as a criterion to determine whether timing meets design requirements. Therefore, designers are required to input constraints correctly so that static timing analysis tools can output correct timing analysis reports.
Common constraints related to Xilinx and data interfaces include Period, OFFSET_IN_BEFORE, OFFSET_IN_AFTER, OFFSET_OUT_BEFORE and OFFSET_OUT_AFTER, etc. Common constraints related to Altera's data interfaces include Period, tsu, tH, tco, etc.
Previous article:Research and implementation of space voltage vector PWM technology based on DSP
Next article:Implementing automatic traffic control system using programmable logic device EPM7032
Recommended ReadingLatest update time:2024-11-16 19:38

- Popular Resources
- Popular amplifiers
-
 MATLAB and FPGA implementation of wireless communication
MATLAB and FPGA implementation of wireless communication - Learn CPLD and Verilog HDL programming technology from scratch_Let beginners easily learn CPLD system design technology through practical methods
- Practical Electronic Components and Circuit Basics (4th Edition)_Explanation of basic circuit principles, introduction to electronic components, design of various circuits and practical circuit analysis
- Multi-port and shared memory architecture for high-performance ADAS SoCs
 MATLAB and FPGA implementation of wireless communication
MATLAB and FPGA implementation of wireless communication




- Huawei's Strategic Department Director Gai Gang: The cumulative installed base of open source Euler operating system exceeds 10 million sets
- Analysis of the application of several common contact parts in high-voltage connectors of new energy vehicles
- Wiring harness durability test and contact voltage drop test method
- Sn-doped CuO nanostructure-based ethanol gas sensor for real-time drunk driving detection in vehicles
- Design considerations for automotive battery wiring harness
- Do you know all the various motors commonly used in automotive electronics?
- What are the functions of the Internet of Vehicles? What are the uses and benefits of the Internet of Vehicles?
- Power Inverter - A critical safety system for electric vehicles
- Analysis of the information security mechanism of AUTOSAR, the automotive embedded software framework
 Professor at Beihang University, dedicated to promoting microcontrollers and embedded systems for over 20 years.
Professor at Beihang University, dedicated to promoting microcontrollers and embedded systems for over 20 years.






- Innolux's intelligent steer-by-wire solution makes cars smarter and safer
- 8051 MCU - Parity Check
- How to efficiently balance the sensitivity of tactile sensing interfaces
- What should I do if the servo motor shakes? What causes the servo motor to shake quickly?
- 【Brushless Motor】Analysis of three-phase BLDC motor and sharing of two popular development boards
- Midea Industrial Technology's subsidiaries Clou Electronics and Hekang New Energy jointly appeared at the Munich Battery Energy Storage Exhibition and Solar Energy Exhibition
- Guoxin Sichen | Application of ferroelectric memory PB85RS2MC in power battery management, with a capacity of 2M
- Analysis of common faults of frequency converter
- In a head-on competition with Qualcomm, what kind of cockpit products has Intel come up with?
- Dalian Rongke's all-vanadium liquid flow battery energy storage equipment industrialization project has entered the sprint stage before production
- Allegro MicroSystems Introduces Advanced Magnetic and Inductive Position Sensing Solutions at Electronica 2024
- Car key in the left hand, liveness detection radar in the right hand, UWB is imperative for cars!
- After a decade of rapid development, domestic CIS has entered the market
- Aegis Dagger Battery + Thor EM-i Super Hybrid, Geely New Energy has thrown out two "king bombs"
- A brief discussion on functional safety - fault, error, and failure
- In the smart car 2.0 cycle, these core industry chains are facing major opportunities!
- The United States and Japan are developing new batteries. CATL faces challenges? How should China's new energy battery industry respond?
- Murata launches high-precision 6-axis inertial sensor for automobiles
- Ford patents pre-charge alarm to help save costs and respond to emergencies
- New real-time microcontroller system from Texas Instruments enables smarter processing in automotive and industrial applications
- What kind of AC socket is most suitable for low-power devices
- How to connect the three wires of GND, VCC and Vout to BNC or XLR port?
- High-efficiency PA design: from Class A to Class J (friendly illustrations and text for PA experts)
- This article reveals the Internet of Things, let’s take a look at it.
- Showing off my goods + some boards I have currently stockpiled
- [Mill MYB-YT507 development board trial experience] Python displays memory and CPU real-time status 1
- How do RF circuits and digital circuits coexist harmoniously?
- Xiangshan high-performance RISC-V processor
- Issues with converting remaining TI points into chip points
- Development process of eCAN in DSP28335






 京公网安备 11010802033920号
京公网安备 11010802033920号