-
Preface
In the C run time library, memcpy is an important function that has a significant impact on the performance of application software. The development of ARM chips to the Cortex-A8[1][2] architecture has not only greatly improved the frequency, but also greatly improved the architectural design. The added NEON instructions are similar to the original MMX instructions under the X86 platform and are designed for multimedia. However, because these instructions can process 64-bit data at a time, they are also helpful for improving the performance of the memcpy function. This article mainly tests various memcpy implementations using the NEON[2] instruction, explores the impact of the NEON instruction and preload instruction on performance, and the changing trend of these impacts after chip optimization and process improvement. At the same time, it is hoped that chip designers can give an explanation based on the understanding of software implementation, so as to guide the direction of further improving performance.
-
Platform Introduction
The test platform for this time is derived from the Cortex-A8 platform that the author encountered in his work project. See the list below:
- FreeScale i.MX51 / i.MX53
- Qualcomm msm8x50 / msm7x30
- Samsung s5pc100 / s5pc110
- TI omap 3430 / omap 3730
-
i.MX5 family
For an introduction to the i.MX5 family, see [6][7]. The i.MX535 can run at two frequencies: 800MHZ and 1000MHZ.
-
i.MX515
- freq: 800MHZ
- cache size: 32KB/32KB I/D Cache and 256KB L2 Cache
- cache line: 64-bit wide (NEON), 64-byte / line
- i.MX535
- freq: 800MHZ / 1000MHZ
- cache size: 32KB/32KB I/D Cache and 256KB L2 Cache
- cache line: 64-bit wide (NEON), 64-byte / line
-
Snapdragon family
For an introduction to Snapdragon, see [8][9][10]. The msm7x30 can run at two frequencies: 800MHZ and 1000MHZ. In addition, the Snapdragon cache is special in that it is 128-bit wide (NEON), 128-byte / line. In the standard Cortex-A8, this value is 64-bit wide (NEON), 64-byte / line. This has a significant impact on performance.
-
msm8x50
- freq: 1000MHZ
- cache size: 32KB/32KB I/D Cache and 256KB L2 Cache
- cache line: 128-bit wide (NEON), 128-byte / line
-
msm7x30
- freq: 800MHZ / 1000MHZ
- cache size: 32KB/32KB I/D Cache and 256KB L2 Cache
- cache line: 128-bit wide (NEON), 128-byte / line
-
s5pc family
The s5pc family reference platform can be found in [11].
-
s5pc100
- freq: 665MHZ
- cache size: 32KB/32KB I/D Cache and 256KB L2 Cache
- cache line: 64-bit wide (NEON), 64-byte / line
-
s5pc110
- freq: 1000MHZ
- cache size: 32KB/32KB I/D Cache and 512KB L2 Cache
- cache line: 64-bit wide (NEON), 64-byte / line
-
omap3 family
For the omap3 family reference platform, see [12][13][14].
-
omap3430
- freq: 550MHZ
- cache size: 16KB/16KB I/D Cache and 256KB L2 Cache
- cache line: 64-bit wide (NEON), 64-byte / line
-
omap3730
- freq: 1000MHZ
- cache size: 32KB/32KB I/D Cache and 256KB L2 Cache
- cache line: 64-bit wide (NEON), 64-byte / line
-
Introduction to memcpy implementation
There are three versions of memcpy implementation on the ARM platform:
- C language version
- ARM assembly version
-
NEON assembly version
ARM's document [4] has a good description of the implementation of memcpy. Others [5][19][20] have further elaborated on the implementation principles and techniques. A brief description is as follows:
- NEON instructions can process 64-bit data at a time, which is more efficient.
- The NEON architecture has a direct connection to the L1/L2 cache, and better performance can be achieved after being enabled at the OS level.
- The ARM/NEON pipeline may be processed asynchronously, and alternating ARM/NEON instructions may achieve better performance.
- In one loop, use as many registers as possible to copy more data to ensure better pipeline efficiency. Currently, the maximum processing block is 128-byte.
-
The operation of cache is particular.
- memcpy is a one-time scan operation without backtracking. The cache preload strategy can improve the hit rate. Therefore, the pld instruction must be used in the assembly version to prompt ARM to fill the cache line in advance.
- The offset in the pld instruction is very particular. It is usually a multiple of 64 bytes. On the ARMv5TE platform, one pld instruction is used in one loop. On the Cortex-A8 platform, it is faster and requires 2~3 pld instructions in one loop to fill a cache line. Such a loop consumes 2~3 clock cycles in exchange for an increase in cache hit rate, which is worth the effect.
- Furthermore, the Cortex-A8 architecture provides preload engine instructions, which allow software to have a deeper impact on the cache, thereby improving the cache hit rate. However, to use the preload engine instruction in user space, it is necessary to patch the OS to open permissions.
-
C language version
The C language version is mainly for comparison. Two implementations are used:
- 32-bit wide copy. Later marked as in32_cpy.
-
16-byte wide copy. It is marked as vec_cpy. The trick of this implementation is to use the gcc vector extension "__attribute__ ((vector_size(16)))" to implement 16-byte wide copy at the C language level and leave the specific implementation to the compiler.
It is worth noting that the compiler will not actively insert pld instructions because the compiler cannot determine the application's memory access pattern.
-
ARM assembly version
The ARM assembly version is also mainly for comparison. Two implementations are used:
- Implemented by Siarhei Siamashka [15]. Later marked as arm9_memcpy. It is optimized for Nokia N770.
- Nicolas Pitre implemented this [16]. It is denoted as armv5te_memcpy. This is the default arm memcpy implementation in glibc.
-
NEON assembly version
The NEON assembly version uses four implementations:
- M?ns Rullg?rd implementation [19]. This is the simplest implementation of a 128-byte-aligned block. It does not detect the case where the block is not 128-byte aligned. Therefore, it is not a practical version. However, this type of implementation can be used to examine the performance limit of memcpy. He provides a total of 4 implementations.
- The full ARM assembly implementation is marked as memcpy_arm. In addition, the author also removes the pld instruction as a comparative experiment to examine the impact of the pld instruction. It is marked as memcpy_arm_nopld.
- The full NEON assembly implementation is marked as memcpy_neon. In addition, the author also removes the pld instruction as a comparative experiment to examine the impact of the pld instruction. It is marked as memcpy_neon_nopld.
- The implementation of alternating use of ARM / NEON instructions. It is marked as memcpy_armneon. In addition, the author also removes the pld instruction as a comparative experiment to examine the impact of the pld instruction. It is marked as memcpy_armneon_nopld.
- ple + NEON implementation. It is marked as memcpy_ple_neon. In addition, the author also replaced the NEON instructions with ARM instructions as a comparative test to examine the impact of ple instructions on ARM/NEON instructions. It is marked as memcpy_ple_arm. Because this implementation requires patching the Linux kernel, it did not succeed on the omap3430 platform. It is a bit troublesome to replace the kernel on the Snapdragon platform, so it was not tested.
- CodeSourcery implementation [17]. This is the implementation in glibc in the CodeSourcery toolchain. There are also two implementations.
- ARM implementation. The following is marked as memcpy_arm_codesourcery. The author also removed the pld instruction as a comparative experiment to examine the impact of the pld instruction. The following is marked as memcpy_arm_codesourcery_nopld.
- NEON implementation. It is marked as memcpy_neon_codesourcery. This is also the NEON implementation used in Android bionic. The author also removed the pld instruction as a comparative experiment to examine the impact of the pld instruction. It is marked as memcpy_neon_codesourcery_nopld.
- QualComm implementation [18]. It is marked as memcpy_neon_qualcomm. This is an optimized version developed by QualComm for the Snapdragon platform in the Code Aurora Forum. It is mainly optimized for the 8660/8650A platform. The feature of this version is that it is designed for L2 cache line size = 128 bytes, and the pld offset is set to a particularly large value. As a result, it has no effect on other Cortex-A8 platforms. Therefore, the author changed the pld offset to the value implemented by M?ns Rullg?rd. The author also removed the pld instruction as a comparative experiment to examine the impact of the pld instruction. It is marked as memcpy_neon_qualcomm_nopld.
- Implemented by Siarhei Siamashka [20]. Later marked as memcpy_neon_siarhei. This is the NEON version submitted by Siarhei Siamashka to glibc, which was not adopted by glibc. However, it was adopted in the MAEMO project. The feature of this version is that the pld offset increases from small to large in order to adapt to the change of block size.
-
Test plan introduction
The test plan is very simple. It refers to the implementation of the moving memory tester [21]. The execution steps are as follows:
- First, verify the correctness of each implementation. The main method is to fill random content with random block size & offset, then perform memcpy operation, and then use the system's memcmp function to verify the two blocks of memory.
- Then call each implementation 400 times with different block sizes. If total copy size < 1MB, increase count until the requirement is met. Time the total operation.
-
Calculate memcpy bandwidth using the formula total copy size / total copy time.
The block size mentioned above = 2^n ( 7 <= n <= 23 ).
In addition, this test program runs in the openembedded-gpe software system. QualComm / Samsung hardware platforms only provide Android software systems, and it is a bit troublesome to switch to the GPE system, so the chroot method is used for testing. Regardless of the software platform, after entering the graphics system, wait for the black screen and then test.
The following table shows the statistics of the operating environment.
Hardware platform
Software Environment
imx51 800MHZ
openembedded-gpe
imx53 1000MHZ
openembedded-gpe
imx53 800MHZ
openembedded-gpe
msm7230 1000MHZ
Android + chroot
msm7230 800MHZ
Android + chroot
msm8250 1000MHZ
Android + chroot
omap3430 550MHZ
openembedded-gpe
omap3730 1000MHZ
openembedded-gpe
s5pc100 665MHZ
Android + chroot
s5pc110 1000MHZ
Android + chroot
The following table shows the statistics of the test items.
Implementation
i.MX51
i.MX53
Snapdragon
s5pc1xx
omap3430
omap3730
int32_cpy
YES
YES
YES
YES
YES
YES
vec_cpy
YES
YES
YES
YES
YES
YES
arm9_memcpy
YES
YES
YES
YES
YES
YES
armv5te_memcpy
YES
YES
YES
YES
YES
YES
memcpy_arm
YES
YES
YES
YES
YES
YES
memcpy_arm_nopld
YES
NO
YES
YES
YES
YES
memcpy_neon
YES
YES
YES
YES
YES
YES
memcpy_neon_nopld
YES
NO
YES
YES
YES
YES
memcpy_armneon
YES
YES
YES
YES
YES
YES
memcpy_ple_arm
YES
YES
N/A
YES
N/A
YES
memcpy_ple_neon
YES
YES
N/A
YES
N/A
YES
memcpy_arm_codesourcery
YES
YES
YES
YES
YES
YES
memcpy_arm_codesourcery_nopld
YES
NO
YES
YES
YES
YES
memcpy_neon_codesourcery
YES
YES
YES
YES
YES
YES
memcpy_neon_codesourcery_nopld
YES
NO
YES
YES
YES
YES
memcpy_neon_qualcomm
YES
YES
YES
YES
YES
YES
memcpy_neon_qualcomm_nopld
YES
NO
YES
YES
YES
YES
memcpy_neon_siarhei
YES
YES
YES
YES
YES
YES
Note 1: Because the i.MX53 EVK board malfunctioned, all no pld test items could not be tested.
Note 2: After opening the preload engine for omap3430, the test generated an illegal instruction error and failed to test the ple test items.
Note 3: It is a bit troublesome to replace the Snapdragon kernel, and the test items of ple cannot be tested.
-
Test results and analysis
The following chart is limited by the page size and cannot show the details well. The specific data and large picture can be viewed in the data sheet document.
-
Performance of various implementations on various hardware platforms
-
imx51 800MHZ

-
imx53 1000MHZ
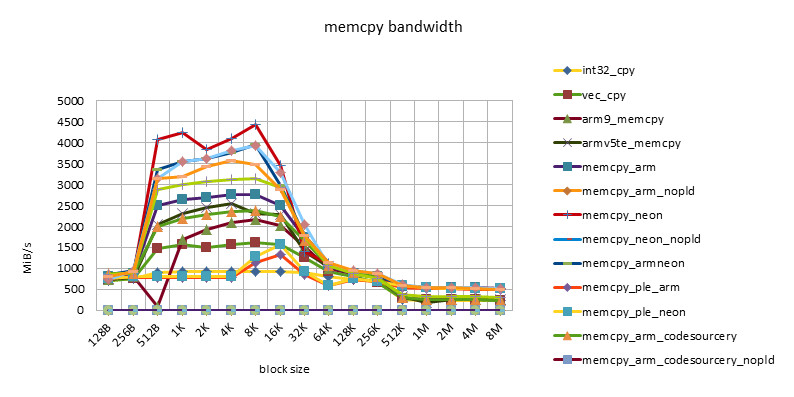
-
imx53 800MHZ
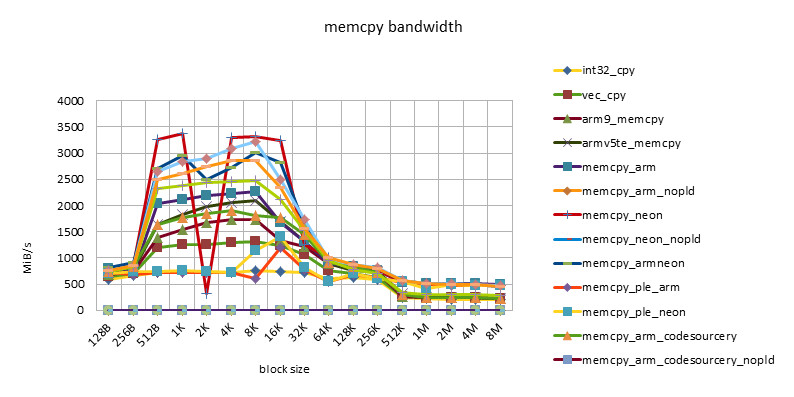
-
msm7230 1000MHZ
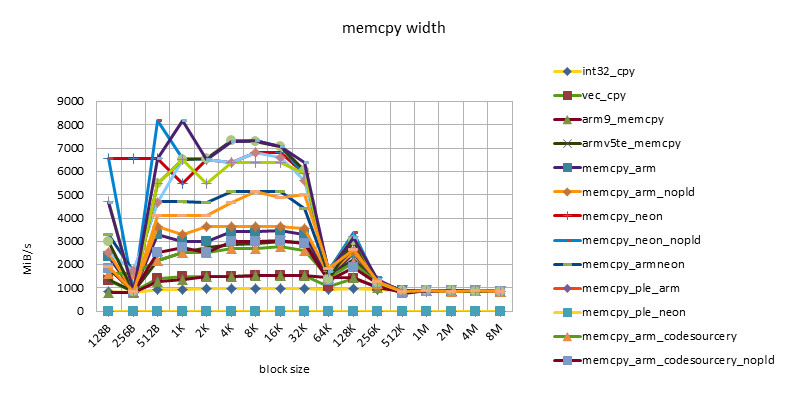
-
msm7230 800MHZ
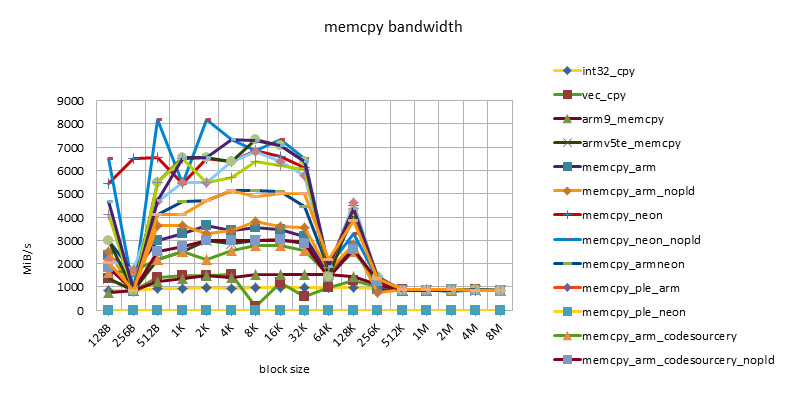
-
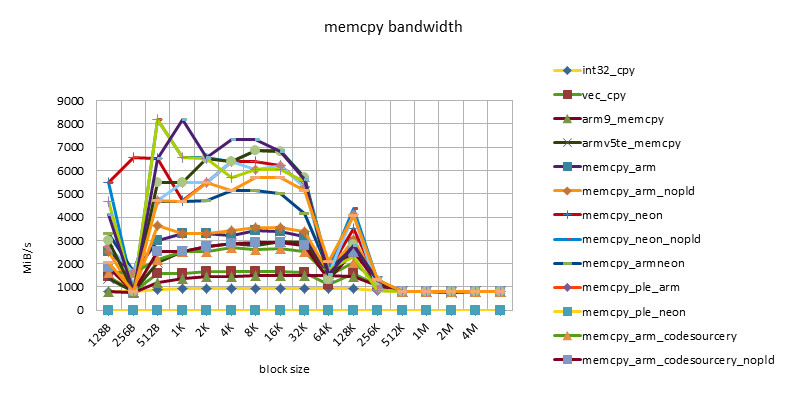
msm8250 1000MHZ
-
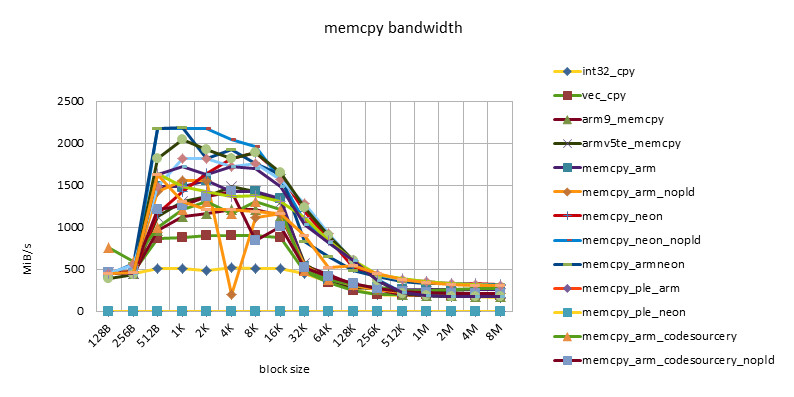
omap3430 550MHZ
-
omap3730 1000MHZ

-
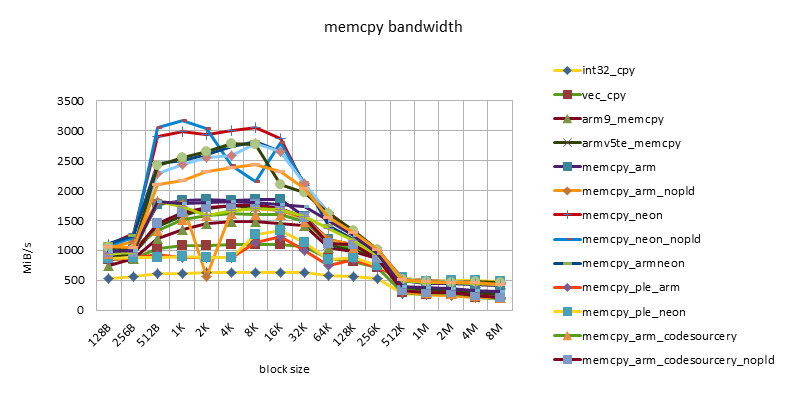
s5pc100 665MHZ
-
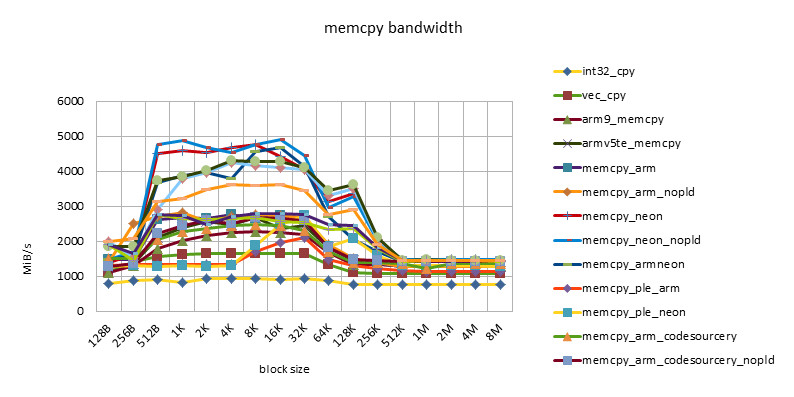
s5pc110 1000MHZ
-
summary
-
- There is a performance plateau between block size = 512B ~ 32K, and there is also a performance turning point at block size = 256K.
- This feature reflects the impact of 32KB L1 / 256KB L2 cache.
- The poor performance of less than 512B may be related to the loss caused by the block alignment technique at the beginning of the function call, or it may be related to the block size being too small and the cache being not ready before the function ends.
- The document [] is still instructive for the implementation of memcpy. However, with the optimization of the chip and the improvement of the process, some rules have changed.
- The performance of NEON instructions is always higher than that of ARM instructions. However, using ARM/NEON instructions alternately does not always lead to performance improvements. With the development, the performance gap between ARM/NEON instructions is narrowing.
- The pld instruction is becoming less and less useful. On older chips, such as the omap3430, the same implementation can get a 50% performance improvement with the pld instruction. On newer chips, such as the msm7230/s5pc110, there is basically no difference in performance, and even the same implementation without the pld instruction has a slight performance improvement. This may be because the pld instruction has no effect, but instead wastes clock cycles in each loop.
- The performance of the implementation using ple instructions is disappointing. This also shows that if there is no good model design, software intervention in the use of cache can easily cause performance degradation.
- The Snapdragon platform has the best cache performance. Beyond the cache, the performance of various implementations (including C language implementation) is basically the same and very efficient. This may be due to the design of the Snapdragon platform's 13-stage load/store pipeline[][]. This feature is good for high-level languages. Because programming cannot use assembly language in many places, developers do not have to consider assembly optimization too much and can rely on the compiler.
- The s5pc110 platform has the best average performance. After out of cache, NEON achieves the best performance, which is basically the same.
-
Performance of various hardware platforms under small/big block size
Since the block size can be divided into two types: fit in cache and out of cache, two profiles are made for comparative analysis.








- 8K block size. This reflects the performance when it fits in cache.
- 8M block size. Reflects out of cache performance.
-
Realization of Möns Rullgörd
Because M?ns Rullg?rd's implementation is the simplest, with only a loop body and no other judgment code, it can be considered as an implementation that reflects the speed limit of the platform.
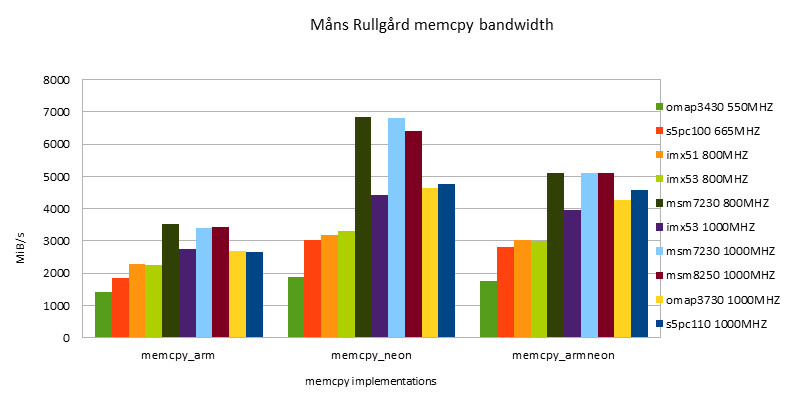
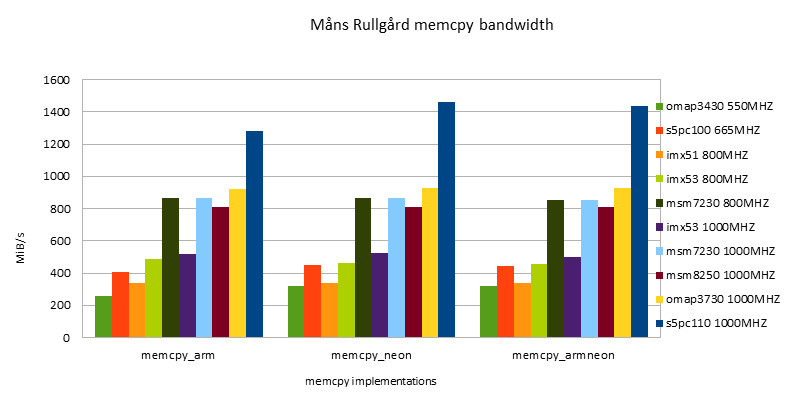
-
ARM Implementation
-
NEON Implementation
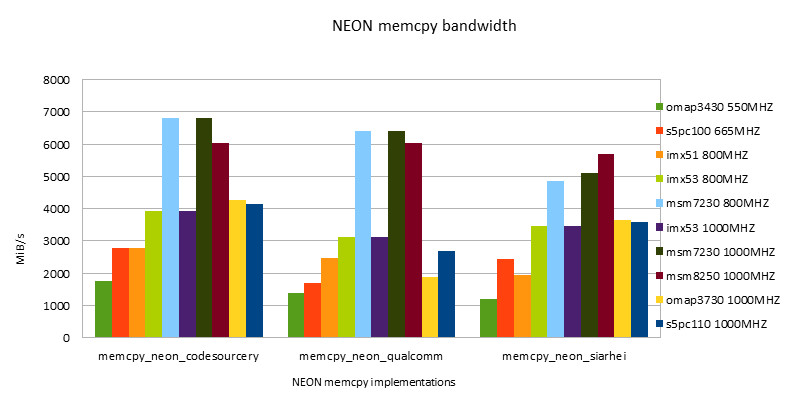

-
summary
- The performance of NEON instructions is always higher than that of ARM instructions. With the development, the performance gap between ARM and NEON instructions is narrowing.
- The performance of the ARM/NEON version is worse than that of the NEON version when fit in cache is used alternately. When out of cache is used, the performance of the two versions is basically the same.
- Under the condition of fit in cache, the Snapdragon platform has the best performance, surpassing the second place s5pc110 by about 43%.
- Under out of cache conditions, s5pc110 has the best performance, surpassing the second place omap3730 by about 57%.
- On the same hardware platform, overclocking (such as i.MX53 800/1000MHZ & msm7x30 800/1000MHZ) has little effect on memory performance.
-
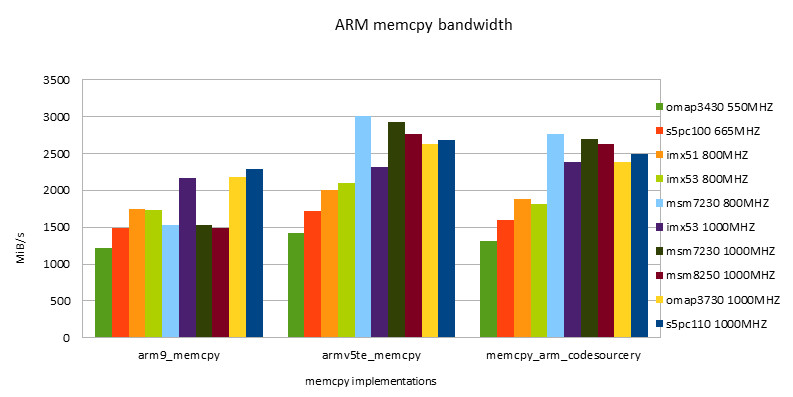
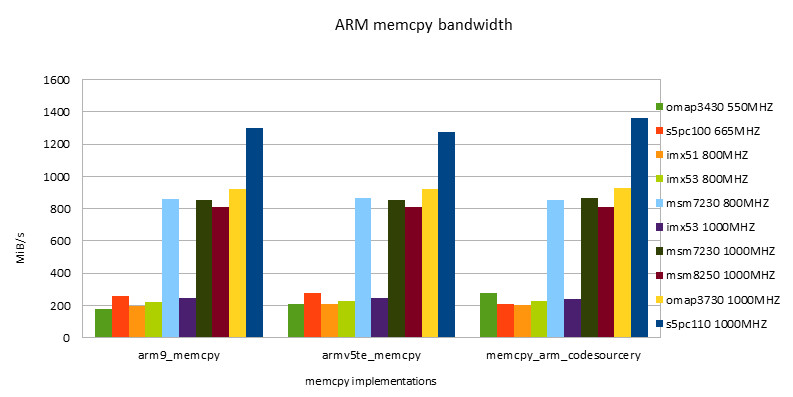
Practical ARM/NEON implementation on various hardware platforms
By comparing the performance of the same implementation on different hardware platforms and combining it with the charts in the previous section, we can evaluate the average performance, or adaptability, of an implementation.
-
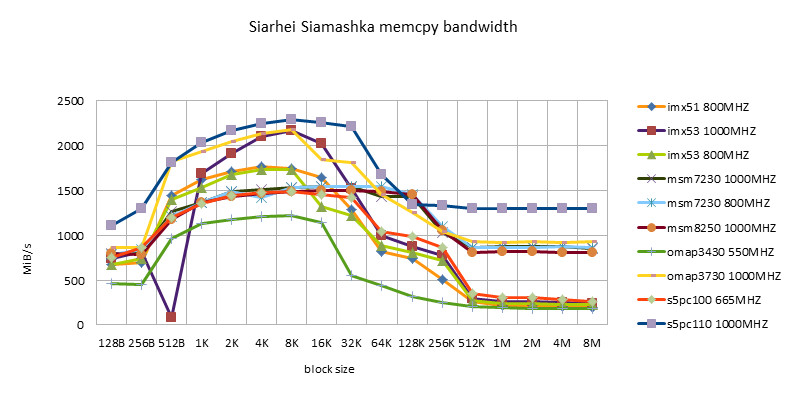
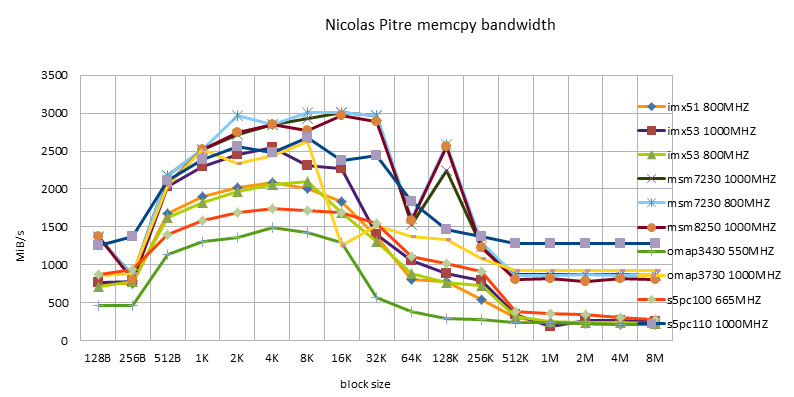
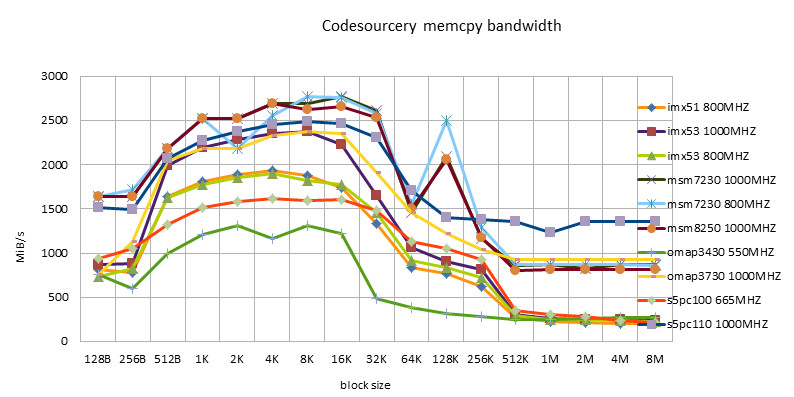
ARM Implementation
-
NEON Implementation
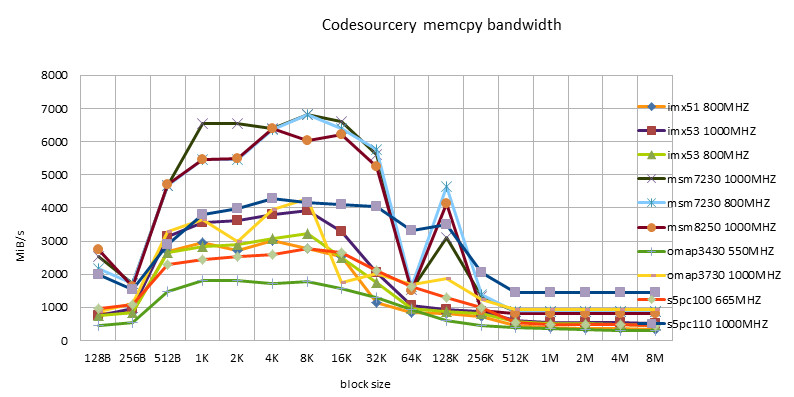
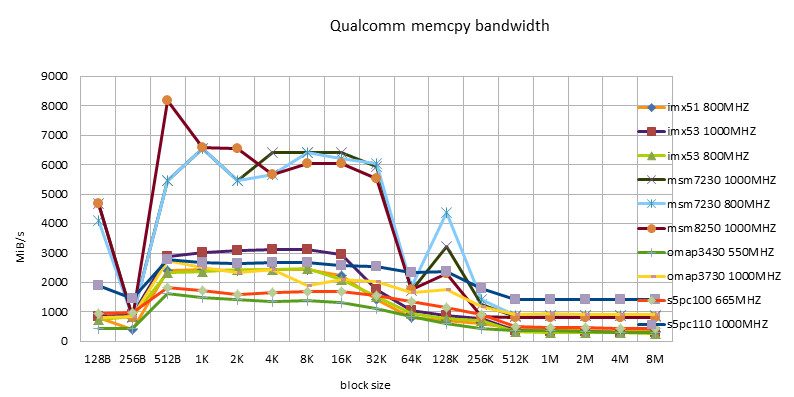
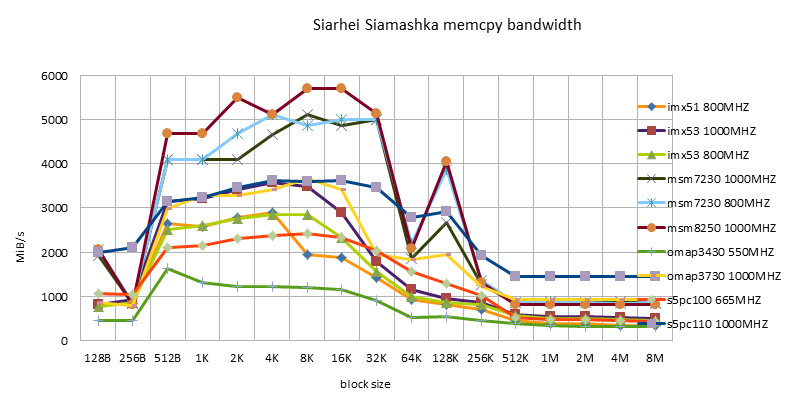
-
summary
- The same implementation may perform differently on different hardware platforms. No one implementation is the best on all platforms.
- Codesourcery version, including ARM/NEON version, has good adaptability. It is worthy of being a toolchain company.
- Siarhei Siamashka's NEON version is also very adaptable. NOKIA's technical strength is also very strong. This guy seems to be the main force in NEON optimization in the pixman project.
- The Qualcomm version is only suitable for Snapdragon platform. Looking forward to testing it on msm8660 and subsequent chips in the future.
-
Summarize
- There is a performance plateau between block size = 512B ~ 32K, and there is also a performance transition at block size = 256K. This feature reflects the impact of 32KB L1 / 256KB L2 cache.
- The performance of NEON instructions is always higher than that of ARM instructions. The performance difference between ARM and NEON instructions is narrowing as the development progresses. When using ARM and NEON instructions alternately, the performance is often worse than the NEON version.
- Without a good model design, software intervention in cache usage can easily lead to performance degradation.
- Under the fit in cache condition, the Snapdragon platform has the best performance.
- Under out of cache conditions, s5pc110 has the best performance.
- On the same hardware platform, overclocking has little impact on memory performance.
- The same implementation may perform differently on different hardware platforms. No one implementation is the best on all platforms.
-
Further testing
Because in the Cortex-A8 series chips, the NEON module is required. In the Cortex-A9 series chips, the NEON module is optional. Because the NEON module affects the die size, thus affecting power consumption and cost. Therefore, some Cortex-A9 chips, such as Nvidia Tegra250, do not have a NEON module. So what impact will the presence or absence of a NEON module have on software performance?











Previous article:Soft floating point and hard floating point issues when compiling ARM code with ARMCC and GCC
Next article:C code optimization method for embedded platform ARM
Recommended ReadingLatest update time:2024-11-16 14:40

- Popular Resources
- Popular amplifiers
 Multithreaded computing in embedded real-time operating systems - based on ThreadX and ARM
Multithreaded computing in embedded real-time operating systems - based on ThreadX and ARM




 Professor at Beihang University, dedicated to promoting microcontrollers and embedded systems for over 20 years.
Professor at Beihang University, dedicated to promoting microcontrollers and embedded systems for over 20 years.






- Innolux's intelligent steer-by-wire solution makes cars smarter and safer
- 8051 MCU - Parity Check
- How to efficiently balance the sensitivity of tactile sensing interfaces
- What should I do if the servo motor shakes? What causes the servo motor to shake quickly?
- 【Brushless Motor】Analysis of three-phase BLDC motor and sharing of two popular development boards
- Midea Industrial Technology's subsidiaries Clou Electronics and Hekang New Energy jointly appeared at the Munich Battery Energy Storage Exhibition and Solar Energy Exhibition
- Guoxin Sichen | Application of ferroelectric memory PB85RS2MC in power battery management, with a capacity of 2M
- Analysis of common faults of frequency converter
- In a head-on competition with Qualcomm, what kind of cockpit products has Intel come up with?
- Dalian Rongke's all-vanadium liquid flow battery energy storage equipment industrialization project has entered the sprint stage before production
- Allegro MicroSystems Introduces Advanced Magnetic and Inductive Position Sensing Solutions at Electronica 2024
- Car key in the left hand, liveness detection radar in the right hand, UWB is imperative for cars!
- After a decade of rapid development, domestic CIS has entered the market
- Aegis Dagger Battery + Thor EM-i Super Hybrid, Geely New Energy has thrown out two "king bombs"
- A brief discussion on functional safety - fault, error, and failure
- In the smart car 2.0 cycle, these core industry chains are facing major opportunities!
- The United States and Japan are developing new batteries. CATL faces challenges? How should China's new energy battery industry respond?
- Murata launches high-precision 6-axis inertial sensor for automobiles
- Ford patents pre-charge alarm to help save costs and respond to emergencies
- New real-time microcontroller system from Texas Instruments enables smarter processing in automotive and industrial applications






 京公网安备 11010802033920号
京公网安备 11010802033920号